Download
1 / 2
20 likes | 150 Views
Community Grids Laboratory. http://grids.ucs.indiana.edu/ptliupages/presentations/PC2007/ contains a set of 4 parallel computing lectures given by Fox at Microsoft Research February 26 to March 1 2007 http://www.connotea.org/user/crmc is a tagged collection of multicore links

E N D
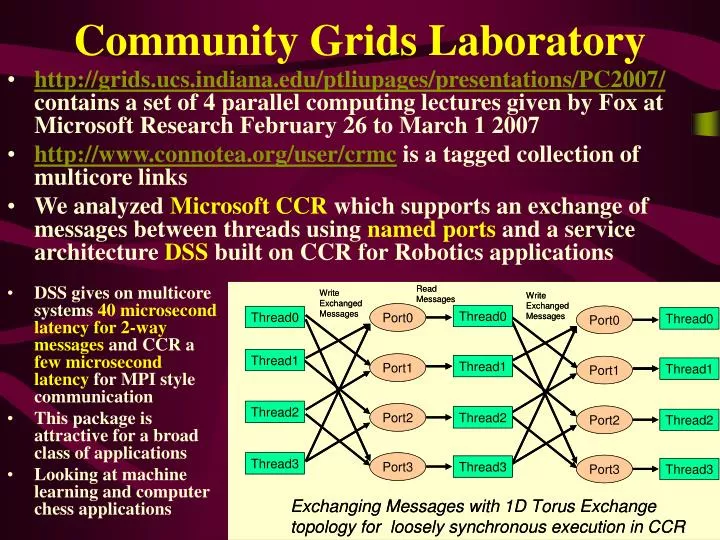
Community Grids Laboratory http://grids.ucs.indiana.edu/ptliupages/presentations/PC2007/ contains a set of 4 parallel computing lectures given by Fox at Microsoft Research February 26 to March 1 2007 http://www.connotea.org/user/crmc is a tagged collection of multicore links We analyzed Microsoft CCR which supports an exchange of messages between threads using named ports and a service architecture DSS built on CCR for Robotics applications DSS gives on multicore systems 40 microsecond latency for 2-way messages and CCR a few microsecond latency for MPI style communication This package is attractive for a broad class of applications Looking at machine learning and computer chess applications
Summary of CCR Stage Overheads for Intel 4-core 2-processor Machine These are stage switching overheads in microseconds for a set of runs with different levels of parallelism and different message patterns –each stage takes about 30 microseconds. 2-core 2-processor Xeon overheads in parentheses. We also benchmarked 2-core 2-processor AMD machine These measurements are equivalent to MPI latencies Match uses a number of threads = number of parallel computations Default uses 8 threads
















