Download
1 / 9
90 likes | 210 Views
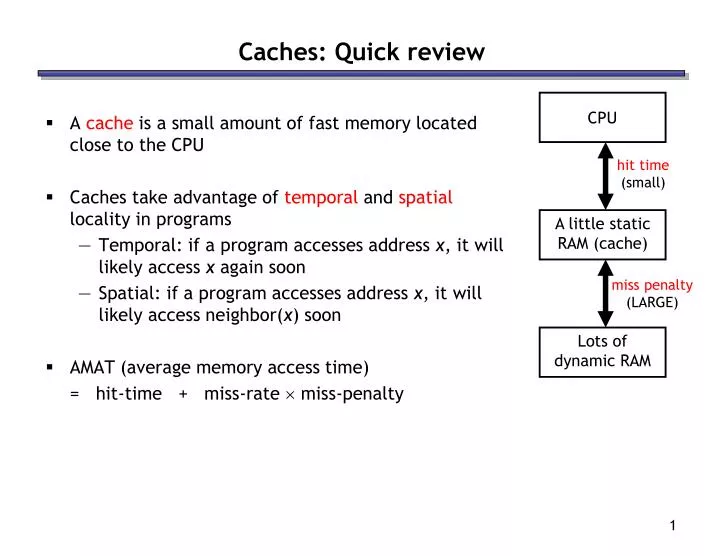
Caches: Quick review. A cache is a small amount of fast memory located close to the CPU Caches take advantage of temporal and spatial locality in programs Temporal: if a program accesses address x , it will likely access x again soon

E N D
Caches: Quick review A cache is a small amount of fast memory located close to the CPU Caches take advantage of temporal and spatial locality in programs Temporal: if a program accesses address x, it will likely access x again soon Spatial: if a program accesses address x, it will likely access neighbor(x) soon AMAT (average memory access time) = hit-time + miss-rate miss-penalty CPU A little static RAM (cache) Lots of dynamic RAM hit time (small) miss penalty (LARGE) 1
Four important questions 1. When we copy a block of data from main memory to the cache, where exactly should we put it? 2. How can we tell if a word is already in the cache, or if it has to be fetched from main memory first? 3. Eventually, the small cache memory might fill up. To load a new block from main RAM, we’d have to replace one of the existing blocks in the cache... which one? 4. How can write operations be handled by the memory system? • Questions 1 and 2 are related—we have to know where the data is placed if we ever hope to find it again later! 2
Direct-mapped cache • Think of memory as a long array M[] of bytes, and the cache as a short array C[] of bytes • Where should we place M[i] in the cache? • A natural choice: C[i % sizeof(C)] • If sizeof(C) = 2k (a power of two): i % 2k = i & (2k – 1) = i & (111…1) • Thus, C-index = k least significant bits of M-index = k least significant bits of address • In a direct-mapped cache, the address directly tells us the location of the data in the cache M C k times
Several addresses map to the same row. How can we distinguish between them? We add a tag, using the rest of the address the tag is the whole address without the index bits But wait a minute… Memory Address Main memory address 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 Index Tag Data 00 + 00 = 0000 11 + 01 = 1101 01 + 10 = 0110 01 + 11 = 0111 00 01 10 11 00 11 01 01 Index 00 01 10 11 4
Index Valid Tag Data Address (32 bits) 0 1 2 3 ... ... ... 22 10 Index Tag Data 1 Loading a byte into the cache • After data is read from main memory, putting a copy of that data into the cache is straightforward • The lowest k bits of the address specify the cache index • The upper (m-k) address bits are stored in the tag field • The data from main memory is stored in the data field • The valid bit is set to 1 at boot-up, the tag and data will be garbage and we don’t want an “accidental” hit
Byte Address Block Address 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 000 001 010 011 100 101 110 111 (n-m-b) bits m bits b-bit Block Offset n-bit Address Tag Index Block offset Index 0 1 00 01 10 11 Spatial locality • Our current scheme does not exploit spatial locality • Get a block of 2b bytes each time • The b least significant bits of the address form the block offset (byte number within the block)
How big is the cache? Byte-addressable machine, 16-bit addresses, cache details: • direct-mapped • block size = one byte • index = 5 least significant bits Two questions: • How many blocks does the cache hold? • How many bits of storage are required to build the cache (data plus all overhead including tags, etc.)?
Memory Address 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 Index 00 01 10 11 Disadvantage of direct mapping • The direct-mapped cache is easy: indices and offsets can be computed with bit operators or simple arithmetic, because each memory address belongs in exactly one block • However, this isn’t really flexible. If a program uses addresses 10, 110, 10, 110, ... then each access will result in a cache miss and a load into cache block 10 • This cache has four blocks, but direct mapping might not let us use all of them • This can result in more misses than we might like
Hacks that won the Tournament • Spring 2006: Circular scan region similar to this semester int scan_delay = 25 * scan_radius * scan_radius; • (illegal entry): buffer overflow in bot name • Fall 2009: Code set random seed srand(time(NULL)) • time() returns time in seconds • tournament would run from 2pm to 2:50pm on Friday… • Spring 2010: spim allows file input/output • MIPS code opened a pre-defined file and sent data to it • Own C program ran in background and “instantly” processed scan • Fall 2010: Two steps (1) compute scan delay on basis of size; (2) scan • Request a “tiny” scan region in step (1) • Change to “huge” scan region before step (2)