Download

1 / 5
50 likes | 65 Views
BaBar cluster facing disk failures, limited healthy nodes, and high maintenance costs. Upgraded with 4 Viglen quad-core workers. Added local workers to the grid. Upgraded to SL4 with kickstart and Cfengine. Replaced broken CPUs fans. Migrating DPM head node. Performance issues with ext3 fs. Testing SRMv2.2 with token reservation. Grid storage with private network. Testing gLite deployment on BlueBear cluster. SouthGrid's pro-active approach with VOs. Manpower issues with APEL support.

E N D
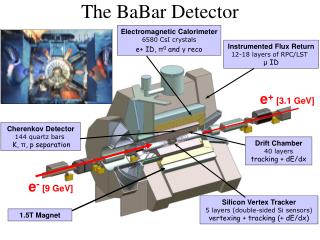
Had been unstable mainly because of failing disks Very few (<20 out of 120) healthy workers nodes left Many workers died during two shut downs ( no power to motherboards?) Very time consuming to maintain Recently purchased 4 twin Viglen quad core workers – two will go to the grid (2 Twin quad core nodes = 3 racks with 120 nodes! ) BaBar cluster withdrawn from the Grid as effort better spent getting new resources online BaBar Cluster
Added 12 local workers to the grid 21 workers in total -> 42 job slots Will provides 60 jobs slots after local twin boxes are installed Upgraded to SL4 Installation with kickstart / Cfengine, maintained with Cfengine VOS: alice atlas babar biomed calice camont cms dteam fusion gridpp hone ilc lhcb ngs.ac.uk ops vo.southgrid.ac.uk zeus Several broken CPUs fans are being replaced Monitoring (pakiti, nagios) is being moved from BaBar farm node to Mon Box Atlas Farm
1 DPM SL 3 head node with 10 TB attached to it Mainly dedicated to Atlas – no used by Alice but ... Latest SL4 DPM provides xrootd needed by Alice Have just bought an extra 40 TB Upgrade strategy: current DPM head node will be migrated to new SL4 server, then a DPM pool node will be deployed on new DPM head node Performance issues with deleting files on ext3 fs were observed -> Should we move to XFS? SRMv2.2 with 3TB space token reservation for Atlas published Latest srmv2.2 clients (not in gLite yet) installed on BlueBear UI but not on PP desktops Grid Storage
31 nodes (servers included) with 2 Xeon CPU 3.06GHz and 2GB of RAM hosted by IS All on a private network but one NAT node Torque server on private network Connected to the grid via SL4 CE in Physics – more testing needed Serves as model for gLite deployment on BlueBear cluster -> installation assume no root access to workers Setup use gLite relocatable distribution and is similar to the installation we performed on BlueCrystal in Bristol Aimed to have it passing SAM test by GridPP20, but may not meet target as delayed by security challenge and helping with setting up Atlas on BlueBear Software area is not large enough to meet Atlas 100GB requirement :( ~150 cores will be allocated to Grid on BlueBear eScience Cluster
How can SouthGrid become more pro-active with VOs (Atlas)? Alice is very specific with its VOBOX. Will need to publish arch type soon, eSc nodes are 32 bits and BlueBear runs x86_64 SL4 -> Can we publish info with one CE? Considering importance of accounting, do we need independent cross-checks? Manpower issues supporting APEL? Bham PPS nodes are broken -> PPS service suspended :( What strategy should SouthGrid adopt (PPS needs to do 64 bit testing) ? Issues?