Download

1 / 80
800 likes | 814 Views
Time Series Center Initiative in Innovative Computing. What is it about? Vision, people Current projects: Anomaly detection Extra solar planets Outer solar system Search in large data sets of time series Pavlos Protopapas CfA-IIC. G. ASTRONOMY. Vision. Idea:

E N D
Time Series CenterInitiative in Innovative Computing What is it about? Vision, people Current projects: Anomaly detection Extra solar planets Outer solar system Search in large data sets of time series Pavlos Protopapas CfA-IIC
G ASTRONOMY
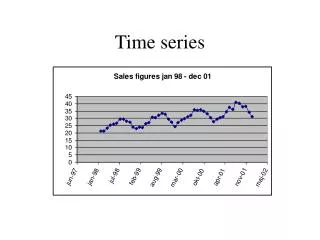
Vision Idea: Create the largest collection of time series in the world and do interesting science. Discoveries. Recipe: 5 tons of data 1 dozen of people that are interested in the science 2-3 people with skills 2 tons of hardware Focus: Astronomy. Light curves = time series
Ubiquity of Time Series Cyclist’sheartrate tcppackets Cadence design stock prices FishcatchoftheNorth-eastpacific
0 200 400 600 800 1000 1200 Supporting Exact Indexing of Shapes under Rotation Invariance with Arbitrary Representations and Distance Measures VLDB 2006: 882-893. Eamonn Keogh · Li Wei · Xiaopeng Xi · Michail Vlachos · Sang-Hee Lee · Pavlos Protopapas
Data Right now we have only astronomical data. We want to extend beyond astronomy. MACHO.(Microlensing survey)- 66 million objects. 1000 flux observations per object in 2 bands (wavelengths) SuperMACHO (another microlensing survey)- Close to a million objects. 100 flux observations per objects. TAOS (outer solar system survey) - 100000 objects. 100K flux observations per object. 4 telescopes. ESSENCE (supernovae survey). Thousands objects, hundred observations. Minor Planet Center Light curves - Few hundred objects. Few hundred observations Pan-STARRS. (general purpose panoramic survey) Billions of objects. Hundred observations per object. OGLE (microlensing and extra solar planet surveys) and few others and we will have 90% of existing light curves. DASCH Digital Access to a Sky Century @ Harvard
There are over 500,000 glass photographic plates in the Harvard Plate stacks, exposed in both the northern and southern hemispheres. • T100 year coverage - between 1885 and 1993 • Unique resource for studying temporal variations in the universe. • Because there are so many plates, built a specialized scanner, funded in part by grant from the National Science Foundation. • Looking for funding to scan the rest. Space Time Machine (A. Goodman)
Astronomy Extra-solar planets: Either discovery of extra solar planet or statistical estimates of the abundance of planetary systems Cosmology:Supernovae from Pan-STARRS will help determine cosmological constants. Asteroids, Trans Neptunian objects etc: Understanding of the solar system. Killer asteroids. AGN: (Active Galactic Nuclei) Automatic classification of AGN Eclipsing binaries:Determining masses and distances to objects Variable stars:Finding a new class or subclass of variable stars will be “cool”. Study of variable stars.Automatic classification. Microlensing: Determine dark matter question. and many more
Computer Science and Statistics Outlier/anomaly detection Clustering Classification Motif detection In either case, analyzing a large data set requires efficient algorithms that scale linearly in the number of time series. The feature space in which to represent the time series (Fourier Transform, Wavelets, Piecewise Linear, and symbolic methods) A distance metric for determining similarities in time series.
Computational The sizes of data sets in astronomy, medicine and other fields are presently exploding. The time series center needs to be prepared for data rates starting in the 10’s of gigabytes per night, scaling up to terabytes per night by the end of the decade. Interplay between the algorithms used to study the time series, and the appropriate database indexing of the time series itself. Real-time: Read time access and real time processing Distributed Computing: Standards, subscription query.
Who Astronomers: C. Alcock, R. Di Stefano, C. Night, R. Jimenez, L. Faccioli (many more indirectly) Computer Scientists: C. Brodley, U. Rebbapragada, R. Khardon, G. Wachman, S. Pember Statisticians: J. Rice, N. Meinshausen, M. Xiaoli, T. Yeon Computational Scientist: R. Dave
Hardware • Disk: • 100 TB of disk GPFS • Computing nodes: • 100 quad cores • DB server: • Dual with 16 GB of memory and 2 TB of disk • Web servers
Why IIC? • Hardware: (not as important to this effort) • Multi-disciplinary effort: We need the framework for such work. • Multi-disciplinary can mean different things. • For me it is • NOT “I am astronomer I will pass my problem to CSs and statisticians and they will solve it for me” • NOT“I am a CS give me data and I will solve the problem for you” • BUT • Working together. Everybody should be involved and feel ownership of the problem. That is scientist, software engineers. Astronomers do understand statistics and algorithms and CS do understand astronomy. [I really really believe this] • Support stuff: Computational expertise.
Rest of the talk Outlier detection Identification of extra solar planets Outer solar system Efficient searches in large data set
Outlier Detection Goal: Detection of anomalous light-curves Find unusual items potential novel astronomical phenomena We seek to develop algorithms to perform the following tasks: Given n light-curves, find the m most anomalous curves, where m is a reasonable number that can be investigated by a domain expert and n is an unreasonably large number of light-curves that will not fit into memory. work withC. Brodley, U. Rebbapragada,
Variable Stars Variable stars: Most stars are of almost constant luminosity (sun usually about 0.1% variability over an 11 year solar cycle in the optical). Stars that undergo significant variations in luminosity are called variable stars. Intrinsic pulsating-Cepheid, RR Lyrae, Mira eruptive-Luminous blue variables explosive- Supernovae extrinsic variable stars rotating eclipsing binary planetary transits Periodic non periodic. We focus on periodic for now For periodic we use folding to simplify the light curve
Similarity In order to find outliers we need to define what is similar means. This is the first step in most machine learning exercises. Euclidean Distance, Dynamic Time Warping, Longest Common Subsequence Euclidean distance between light curves Q and C z-normalized Euclidean Distance C Q
“Warped” Time Axis Time warping Fig: Y. Sakurai, et al.: FTW: fast similarity search under the time warping distance. PODS 2005: 326-337 D. J. Berndt, and J. Clifford: Finding Patterns in Time Series: A Dynamic Programming Approach. Advances in Knowledge Discovery and Data Mining 1996: 229-248
Phasing Two light curves can be identical but off phase. light curve Q t light curve C
Observational Errors • All measurements have associated errors (due to the atmosphere, optics etc). • A light curves is a series of estimation of flux/photons from a particular source • Each one of those estimations include many steps background subtraction, fit to a PSF (point spread function) etc. • Depends on the conditions • Some of those measurements are more believable than others x y 0 10 20 30 40 50 60 70 80
Algorithm 1 • For each pair of light curves Q and C calculate the similarity • Construct the similarity matrix • Find light curves that are the less like the rest - odd objects ignore diagonal dark means dissimilar light curve C Outliers light curve Q
Algorithm 1 Problems: Calculate all pairs O(n2) Only finds global outliers [more later]
Algorithm 2a: • The measure of dissimilarity of light curve Q to the set is: • the average of the distances of Q to all other light curves • the distance of Q to the “average light curve” • If we could calculate the “AVERAGE” light curve (do this only once) we could do this very fast. • Problem: Every pair has a particular phase that maximizes the distance (correlation).
Algorithm 2b: • If we find clusters of light curves that are similar then we can hope to find a phase for each light curves that “almost” maximizes the correlations in that cluster • Then we represent the cluster with an “average” light curve • Compare to these “averages” • Result PK-means.A heuristic algorithm to find clusters of light curves that are similar. • Start with k clusters. Randomly selected centroids • Assign light curve to the closer cluster (perform phase adjustment) • Recalculate centoids • Goto 1 Check for different k’s and initial starts-BIC • Proof that converges • Performs very well (for out data set it finds the same outliers as the O(n2) algorithm) • Problems: • Only finds global outliers. • Finds too many clusters if data set is heterogeneous
Other types of outliers OUTLIER CLUSTER GLOBAL LOCAL
Pruning If light curve Q shows similarity to few light curves early then we stop C calculation abandoned at this point Q 0 10 20 30 40 50 60 70 80 90 100 Fig: Eamonn J. Keogh
Archetype of Cepheid • Cepheid catalog from OGLE survey. • 3546 light curves in the catalog (pre-selected). • 9 top outliers
Archetype of Eclipsing Binary • Eclipsing Binaries catalog from OGLE survey. • 2580 light curves in the catalog (pre-selected). • 9 top outliers
Current work • Multiple projection • Outliers are defined with respect to a particular representation of the data. (FT, Wavelet, Piecewise representation) • For example a light-curve that has a variable period will be clearly flagged as an outlier among light-curves with a constant period if the investigation is done in Fourier space. However, the same light-curve will not be flagged as an outlier if the analysis is performed in normal space (assuming the variability of the period is small). • We combine the rankings from different projections by computing the weighted average of the ranks in each projection. • The weights are combination of the uniqueness of each projection. We calculate the “uniqueness” of each projection as a linear combination of Spearman's rank correlation between each pair of projection. • Meaning of outlier. When do we stop looking ? • Do the analysis for non-periodic light curves.
So far we search for novel objects. • How about things that we know how they are but are rare ? • Extra solar planets • Trans Neptunian objects • Need smart algorithms • How about rare objects with low signal-to-noise ? • Need smart algorithms and solid statistical approach
Extra Solar Planets • Big question is whether they might support extraterrestrial life. • Planet formation mechanism. • Work with C. Alcock, J. Rice and R. Jimenez
Chronology of main events 1992: Wolszczan and Frail first extra solar planet orbiting pulsar star PSR 1257+12 1995: 51 Peg b. The first definitive extrasolar planet around solar-type Star by Mayor and Queloz. A band name after that too. 51 Peg - http://www.51peg.com/ 1999: HD 209458 b.First transiting planet by David Charbonneau. 2006: OGLE-2005-BLG-390Lb. First Earth-like extra solar to be observed. MOA,PLANET/RoboNet,OGLE. 2007: (yesterday) Number of transiting extra solar discovered 21
Detection Techniques • Six methods (may be more) of detecting extrasolar planets which are too faint relative to their much brighter host stars to be directly detected by present conventional optical means. • Pulsar timing: Time anomalies between pulsars. Millisecond variations. • Astrometry: (measurement of position of the object) • Not reliable very high accuracy (<milliarcsec) is needed to detect changes in motion. • Requires orbit to be perpendicular to line of sight. • Radial velocity: • Measure variations in the speed with which the star moves away from Earth or towards Earth. Only know m sin(i) • Gravitational microlensing: • A notable disadvantage is that the lensing cannot be repeated because the chance alignment never occurs again. • The key advantage of gravitational microlensing is that it allows low mass (i.e. Earth-mass) planets to be detected using available technology.
Transit method: (produces light curves) • Relatively new method. • Only works for a small percentage that the orbits align from our vantage point. • Large number of stars can be follow simultaneously. • Observe atmosphere. • Determine size. Along with Doppler can learn density. • Many false positives. However we are getting better.
Summary of discoveries • SUMMARY 239 Planets • -Radial velocity- updated : April 2007 • 178 planetary systems • 206 planets • 18 multiple planet systems • Microlensing- updated : April 2007 • 4 planets • Direct Imaging- updated : April 2007 • 4 planets • Pulsar planets- updated : April 2007 • 2 planetary systems • 4 planets • 1 multiple planet systems • -Transit Method: April 2007 • 21 planets
Transit Method How to design a transit survey ? • Large coverage (large part of the sky) • High Precision (error<1%) • Specific targets depending on the goals. Open clusters, high metallicity regions. • Observational sampling (few observations per hour) • Continually taking data 24 hours HOW ABOUT SURVEYS THAT ARE NOT DESIGNED FOR THAT?
typical light curve with non optimal sampling may look like anything
Transit model • We need to choose a model for our transits • Four free parameters: • Period, P • Depth, • Duration, • Epoch, • Note: A more realistic model can easily be made using tanh
S2-const for a light curve containing a transit. True Period is at 1.03 days.
MOPED Multiple Optimized Parameter Estimation and Data CompressionMOPED Method to compress data by Heavens et al. (2000) Given data x (our case a light-curve) which includes a signal part μ and a noise n The idea is to find weighting vector bm (m runs from 1 to number of parameters) that contains as much information as possible about the parameters (period, duration of the transit etc.). These numbers ym are then used as the data set in a likelihood analysis with the consequent increase in speed at finding the best solution. In MOPED, there is one vector associated with each parameter.
Find the proper weights such as the transformation is lossless. Lossless is defined as the Fisher matrix remains unchanged at the maximum likelihood. The Fisher matrix is defined by: The posterior probability for the parameters is the likelihood, which for Gaussian noise is (alas needs to be Gaussian) If we had the correct parameters then this can be shown to be perfectly lossless. Of course we can not know the answer a priory. Nevertheless Heavens et al (2000) show that when the weights are appropriate chosen the solution is still accurate.
The weights are (complicated as it is) Where comma denotes derivatives. Note: C is the covariance matrix and depends on the data is the model and it depends on the parameters. Need to choose a fiducial model for that
Now what we do with that? Write the new likelihood Where qf is the fiducial model and q is the model we are trying out. We choose q and calculate the log likelihood in this new space. WHY ? If the covariant matrix is known (or stays significantly same) then the second term needs to be computed only once for the whole dataset (because it depends on fiducial model and trial models) So for each light-curve I compute the dot-product and subtract. But there is more (do not run away)
Multiple Fiducial Models For an arbitrary fiducial model the likelihood function will have several maxima/minima. One of those maxima is guaranteed to be the true one. If there was no noise this would have been exact. For an another fiducial model there again several maxima/minima. One of those maxima is guaranteed to be the true one Combine several fiducial models and eliminate all but the true solutions. We define a new measure
Y as a function of period. First panel is after 3 fiducial models Second panel after 10 fiducial models Third panel after 20 fiducial models. Synthetic light curves: One 5 measurements/hour, total of 4000 measurements. S/N=5
We can calculate the p-value analytically. Y as a function of period for synthetic light curve. Each panel shows different S/N Dotted line shows 80% confidence level. Light curves with 2000 measurements and S/N>5 we have 85% recovery with no false positives for 80% confidence threshold.
Computational method • Most of the work can be done once at the beginning of the survey. • For each fiducial model we can calculate the part of the equations that are expensive (the weighting factors b) • For each new light curve we only need to take the dot product of weighting factors and add them up. This is independent of the search parameters (period etc) . • Other adjustments can be done to make it really fast. • N ~ Nobs Nfid as oppose to Nobs Nq where q is the search parameter. This could easily mean speed up factors of 104