Download

1 / 32
320 likes | 456 Views
Molecular Genetics. Protein Synthesis Chapter 5. History. One Gene – One Enzyme Archibald Garrod – early 1900’s Certain illnesses occurred in some families more often than in others

E N D
Molecular Genetics Protein Synthesis Chapter 5
History • One Gene – One Enzyme • Archibald Garrod – early 1900’s • Certain illnesses occurred in some families more often than in others • Enzymes are under the control of hereditary material, thus an error in hereditary material resulted in an error in an enzyme • “Inborn error of metabolism” • Alkaptonuria urine appears black due to containing alkapton • People with alkaptonuria have a defective alkapton metabolising pathway
History • Beadle & Tatum – 1941 • Experimentally demonstrated Garrod’s idea using bread mould Neurospora crassa • Regular strains could grow on minimal media • Inorganic salts, sugar, B vitamins • Defective strains could not grow on minimal media • Could not manufacture complex compounds required • They could grow on a complete media • So which AA or vitamin where they unable to synthesize?
Placed colonies of the mutant strain in vials, each containing minimal medium plus one main nutrient • One strain only grew on minimal medium plus arginine. • One of the precursors to arginine was defective. • Some strains could not grow in the presence of ornithine but could grow in citrulline or argininosuccinate defective enzyme A or B • 4 distinct mutant strains • Concluded that one gene controls production of one enzyme
History • Vernon Ingram – 1952 • Working with hemoglobin in 1952 he realized that some proteins consist of more than one polypeptide chain and therein the protein was controlled by more than one gene. • Hemoglobin is made of 4 polypeptide chains • Two are denoted alpha and two are denoted beta • In the beta polypeptide of people who have sickle cell anemia glutamic acid is substituted for valine.
History • Change in the AA from glutamic acid to valine in individuals who suffer from sickle cell anemia. • He linked a human hereditary abnormality to a single alteration in the amino acid sequence of a protein. • The Father of Molecular Medicine
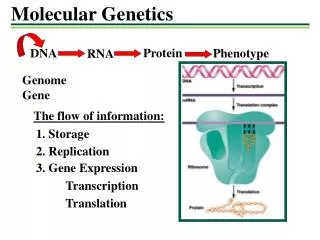
Protein Synthesis - Overview • Central Dogma • The notion that ribosomes need to synthesize protein without access to DNA • DNA should not be leaving the nucleusdamaged? • Proteins are required in large amounts only two strands of DNA to be read? • DNA back into nucleus reentry strategy? • Transcriptioncopying of information in DNA to mRNA • Translation ribosomes using the mRNA as a blueprint to synthesize proteins from amino acids
Protein Synthesis - Overview • RNA • Ribose sugar instead of a deoxyribose sugar (hydroxyl group on its 2’ carbon) • Contains uracil instead of thymine (similar in shape except thymine has a methyl group on its 1’ carbon and uracil just has an H) • RNA is single stranded • 3 main types of RNA • mRNA end product of transcription; will vary in length depending on gene transcribed • tRNA delivers amino acids to the ribosomes for translation; short in length (70-90 bp long) • rRNA binds with ribosomal protein to form ribosomes
Protein Synthesis - Overview • Transcription & Translation • InitiationRNA polymerase binds to DNA at a specific site known as the promoter, near the beginning of the gene. • Elongation Using DNA as a template, RNA polymerase puts appropriate ribonucleotides in order to create an RNA transcript • TerminationRNA polymerase passes the end of the gene and is signaled to stop. The mRNA transcript leaves the nucleus for the cytoplasm
Protein Synthesis - Overview • Translation • Initiationa ribosome binds to mRNA. The ribosome moves along the mRNA three nucleotides at a time as each set of three nucleotides (codon) codes for one amino acid. • ElongationtRNA delivers the AA and the polypeptide chain is elongated. • Terminationa codon sequence is reached that signals the process to stop. Ribosome falls off mRNA and polypeptide chain is released.
Protein Synthesis - Overview Genetic Code – p.240, fig. 7 • There are 20 different amino acids found in proteins, but only four different bases in mRNA • One nucleotide per amino acid would mean 4 amino acids could be created (41 = 4) • Two nucleotides (42 = 16) • Therefore (43 = 64) however we only need 20 amino acids so there is quite a bit of overlap. • What that means is that more than one codon can code for a single amino acid • UUU, UUC, UCU, UCC all code for phenylalanine • One codon serves as the start codon (AUG, GUG, UUG) and others serve as stop codon (UGA, UAA, UAG)
Transcription - 5.3 (p. 243, fig. 2) • Initiation • RNA polymerase binds to the DNA upstream of the region to be transcribed. The upstream region is known as the promotor which is usually filled with adenine and thymine bases. Only 2 H-bonds, energy saving? • Elongation • RNA polymerase has bound and opened the double helix, now it starts building single stranded mRNA in the direction of 5’ to 3’. • RNA polymerase starts the process of elongation • no primer • Template strandthe strand of DNA that gets transcribed • Coding strandthe strand of DNA that does not get transcribed
Transcription • Termination • Terminator sequence bases at the end of a gene that signals RNA polymerase to stop transcribing • The mRNA dissociates from the DNA template strand, RNA polymerase is free to bind to another promoter region • Modifications • Primary transcript adjustments. • 5’ cap is added 7-methyl guanosine is added to the start of the primary transcript to protect it from digestion in the cytoplasm by nucleases and phosphatases & to facilitate the initiation of translation • 3’ tail is added 200 adenine ribonucleotides added by poly-A polymerase; poly-A tail • Eukaryotic genes have coding regions (exons) and non-coding regions (introns) • Introns need to be spliced out as they will lead to improperly formed proteins • Spliceosomes particles made of RNA and protein that cut out introns and join together the remaining exon regions • mRNA transcript is created! • No checking though as with DNA replication errors are not as detrimental
Translation • Ribosome consists of two subunits large subunit (60s) & small subunit (40s). • The “s” refers to the rates at which various components sediment when centrifuged. • The two-subunits clamp the mRNA between them and the subunits move along the mRNA from 5’ to 3’ Initiation • The point at which new amino acids are added, that is, when the subunits are actually reading the mRNA is known as the reading frame.
Translation • tRNA delivers the amino acids. • Anticodon recognize and pair with the codon of the mRNA. • The opposite arm carries the appropriate corresponding amino acid • Some discussion about whether there are 20, 64 or some other number of different tRNA molecules • Wobble hypothesis idea that tRNA can recognize more than one codon by unusual pairing between the first base of the anticodon and the third base of a codon. • Aminoacyl-tRNA a tRNA molecule with its corresponding amino acid attached to its acceptor site at the 3’ end. • Aminoacyl-tRNA synthetases.
Translation • Elongation of Polypeptide Chain (p. 252, fig. 4) • Starts with AUG methionine • Two sites for tRNA within the large subunit of the ribosome: • A (acceptor) site site where tRNA brings in an amino acid • P (peptide) site site where peptide bonds are formed between adjacent amino acids on a growing polypeptide chain.
Translation • Termination • Ribosome eventually reaches a codon which does not code for an amino acid, known as stop codons (UGA, UAG, UAA) • Release factor protein that recognizes that the ribosome has stalled and aids in release of polypeptide chain from the ribosome. Essentially the two subunits fall off the mRNA. • Possible final steps to the amino acids or the polypeptide chain: • Sugars added glycosylation • Phosphates added phophorylation • Enzymes cut up polypeptide chain
Control Mechanisms • Housekeeping genesgenes switched on all the time because they are needed to keep the (organism) alive. • Gene regulation Genes get turned on by transcription factors (proteins) that bind to DNA and help RNA polymerase bind. • Regulation of gene expression • Transcriptionalcontrol of which genes are transcribed or the rate of transcription • Posttranscriptionalcontrol of rate of creation of mRNA transcript • Translationalcontrol how often and how rapidly mRNA transcripts are translated into proteins • Posttranslationalcontrol rate at which proteins pass through the cell membrane
Control Mechanisms • lac Operon • Lactose disaccharide found in milk products consisting of two sugars: glucose and galactose • E. coli bacteria use the two monomer sugars as an E source • -galactosidase enzyme responsible for the breakdown of lactose into glucose and galactose • E. coli should not produce -galactosidase if milk is not present. Negative control • The gene for -galactosidase is part of an operon cluster of genes under the control of one promoter and one operator in prokaryotic cells • Operator regulatory sequence of DNA to which a repressor protein binds (helps with the negative control)
Control Mechanisms • lac operon three genes that code for proteins involved in the metabolism of lactose (lacZ, lacY & lacA) • lacZ codes for enzyme -galactosidase • lacY codes for -galactosidase permease (enzyme that allows lactose to enter the cell) • lacA transacetylase with unknown function
Control Mechanisms • LacI protein repressor protein that blocks the transcription of -galactosidase by binding to the lactose operator and getting in the way of RNA polymerase • Inducer a molecule that binds to a repressor protein and causes a change in conformation, resulting in the repressor protein falling off the operator…LACTOSE DOES THIS TO LacI
Mutations • Mutations changes in the DNA sequence that are inherited • Types of Mutations (p. 260, fig. 1) • Silent mutation no change to coded amino acid and no phenotypic change • Introns & redundancy in genetic code • (UUU to UUC on mRNA still phenylalanine) • Frameshift Mutation cause a change in the reading frame of codons. Usually result in different amino acids being incorporated into a polypeptide • Deletion one or more base pairs are deleted from a DNA sequence • Insertionplacement of an extra nucleotide in the DNA sequence
Mutations • Point Mutations include silent, insertion and deletion mutations as they may all occur at a certain point in the base sequence and may only involve one base pair. • Substitution one base pair changed for another • Missense mutation results in the single substitution of one amino acid for another • Nonsense mutation results in a normal codon being changed to a stop codon • Translocation transfer of a fragment of DNA from one site in the genome to another location. Often two fragments from nonhomologous chromosomes will trade place • can create a fusion protein (new and different). • Transposable elements segments of DNA that are replicated as a unit from one location to another on chromosomal DNA • Inversion reversal of a segment of DNA within a chromosome
Mutations - Causes • Spontaneous mutations occurring without chemical change or radiation but as a result of errors made in DNA replication • DNA polymerase I rereads duplicated DNA to check for errors but sometimes point mutations do occur • Induced mutations caused by chemical agent or radiation • UV light – possesses more energy than visible light; can cause a point mutation in skin • X-rays – high frequency, high energy radiation that can break the backbone of DNA
Cancer • This is perhaps one of the most dangerous human diseases. • One third of children born this year will contract cancer and of that one quarter of males and one third of females who contract cancer will die from it. • It is a growth disorder of cells. Something happens to a normal cell and it starts to grow in an uncontrolled and invasive way. • The ball of cells is called a tumor and if it turns hard is called a sarcoma (connective tissue) or carcinoma (epithelial tissue). Metastases is when cells break away from the ball and move to other parts of the body. • Carcinogens and viruses lead to cancer
Cancer • Molecular Basis of Cancer • Techniques to study what happens to Cancer Cells • Transfection – isolating DNA from human tumor cells • - cleaving it into random fragments using enzymes • - testing the fragments individually for the ability to induce cancer • Using this process it was found that in some cases only a single gene was responsible for the cancerous growth. This led to the onc gene theory, that is, it was the onc gene that was causing the cells cancer. Onc genes are genes that have gone wrong
Cancer • Conclusions about onc genes • 1. A cellular regulatory protein – epidermal growth factor (EGF) – binds to a specific receptor on the inner plasma membrane and triggers cell division. A protein encoded by a gene called ras acts to determine what cellular levels of EGF are adequate to initiate cell division. In several forms of cancer the onc version of ras encoded protein activates the receptor in response to much lower levels of EGF than does the normal version of the protein. • 2. normal gene onc gene one point mutation. • For example, a human bladder carcinoma induced by ras is a single NB change from G to T which changes the protein from glycine to valine. • 3. Mutation from ras to onc can lead to cancer. • There are probably no more than thirty to fifty genes whose mutation can lead to cancer • 4. Onset of cancer over the age of 40 accumulation of onc genes. That is, for most cancers, more then one mutation is required and this is accomplished naturally over time.
Eukaryotes vs. Prokaryotes • Endosymbiotic Relationships • Endosymbiotic physical and chemical contact between one species and another species living within its body, which is beneficial to at least one of the species • Prokaryotic mitochondria and host prokaryotic cells are believed to have an endosymbiotic relationship • The Facts… • Mitochondria have circular genomes not contained in a nucleus…same as prokaryotic cells • The sequence of mitochondrial DNA is similar to the genomes of prokaryotic cells • Mitochondria divide by the process of fission (asexual reproduction through separation) • Mitochondria possess their own system of DNA synthesis indicating that they may once have been free-living cells
Gene Organization • Chromosomes human (eukaryotes) genome organization complex including protein and DNA (chromatin) • nucleus is 5 m in diameter and an entire genome stretched out in individual nucleotides would be 1.8m in length…how does this happen? • Every 200 nucleotides DNA is coiled around eight histones…this complex is called a nucleosome • Nucleosomes are coiled into chromatin fibres • Chromatin fibres are coiled into a supercoil
Gene Organization • Coding and Non-coding Regions • 80000-100000 genes with 95% being non-coding (introns) • Non-coding regions are filled with VNTRs (variable number tandem repeats) which are repetitive sequences of DNA that vary among individuals • Telomeres long sequences of repetitive, non-coding DNA on the end of chromosomes • Centromeres constricted region of chromosome that holds two replicated chromosome strands together • Why would these two regions be good candidates for VNTRs?