Download

1 / 24
240 likes | 328 Views
Threads. Process : program in execution and its context resources assigned to it a virtual machine with memory - segments and pages, and high level facilities open files, semaphores, buffers etc. scheduling and dispatching execution interleaved with other processes; priorities

E N D
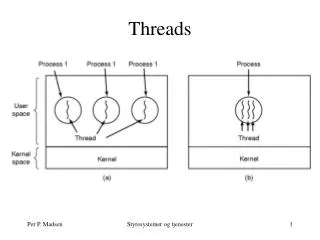
Operating Systems: Threads Threads • Process : • program in execution and its context • resources assigned to it • a virtual machine with memory - segments and pages, and high level facilities • open files, semaphores, buffers etc. • scheduling and dispatching • execution interleaved with other processes; priorities • volatile context of PC, Stack pointers, registers etc. • Threads : • multiple threads can exist within a single process • creation, deletion, synchronisation • can execute concurrently • thread priorities • multiprocessor machines
Operating Systems: Threads • Unit of resource ownership remains the process • all threads within a process share the same resources • virtual memory - all code and data, open files, pipes, sockets etc. • processes compete for resources from the kernel • threads must cooperate in using their resources • Unit of scheduling and dispatching becomes the thread • each thread needs its own volatile context • PC, stack and stack pointers, registers and status
Operating Systems: Threads • Threads can be created much more quickly than processes • no virtual machine to be created • just a new volatile context, stack area and registration with the scheduler • threads are typically created to run procedures within a program • Thread libraries available for most Operating Systems • Windows NT/2000, Solaris, Mach, OS/2 • standard threads package - POSIX threads • Multi-threaded concurrent languages : • ADA, Occam • a thread per task • intercommunication by means of rendezvous • inter-thread message passing very efficient - via virtual memory • Java • extend Thread class in java.lang package
Operating Systems: Threads • Benefits of threads : • better programming paradigm for many applications • a thread for each inherently concurrent activity • simpler and more reliable programs • performance gains • example: less hold-up by blocking system calls • ability to use multi-processor systems easily and conveniently • data can be partitioned to take advantage of multi-processing • real-time programs: • interrupts, signals and events occurring asynchronously • create a new thread for each asynchronous event as in happens • network servers: • servers handle multiple concurrent requests from network machines • create a thread to deal with each request separately
Operating Systems: Threads • distributed object servers in a network - CORBA object brokers • a thread per object • databases and transaction systems • dealing with multiple input sources and outputs • a thread per stream • user interaction: • foreground keyboard, mouse and screen interaction concurrent with background computation e.g. a spreadsheet • create separate threads for foreground and background • a menu selection thread • screen update and scrolling threads • command execution thread • checkpoint threads • a background thread, executed periodically, that saves data • protects against crashes
Operating Systems: Threads • Example: a CS4 graphics project : A Virtual Orrery • each planet and moon represented by a thread • work out their own motions in cooperation with other threads • Example: a Network File Server • for each request from a user: • file directories accessed to get disc addresses • page faults will cause a hiatus - delaying later requests • server initiates disc transfers and waits for completion • disc device driver will reschedule transfers depending on head position • transfers may be completed out of order depending on disc rotation position • server has to remember all requested actions still outstanding and deal with completions in any order • effectively having to incorporate concurrency control into the server • much easier to start a new thread for each request • a thread held up for actions to complete does not hold up other threads • each thread a simple sequential series of actions
Operating Systems: Threads Example: Pagemaker DTP package • service thread : • initialisation - takes up idle time whilst creating and opening files • printing, importing data and “flowing” text • event-handing thread : • menu item selection • window operations • synchronising with service thread is tricky • user may continue to type, or use mouse, whilst service thread activity still in progress • user activity restricted by disabling menu items until service thread activities complete • screen-redraw thread : • allows redrawing to be aborted • dynamic scrolling as user drags scroll bar • event-handling thread monitors scroll bar and redraws margin rulers • screen-redraw thread constantly monitors rulers and tries to redraw screen and catch up • three threads always active
Operating Systems: Threads • Solaris Threads : • kernel level threads • kernel knows nothing about user-level threads • only knows about kernel threads • can be multiplexed onto any processor • can be tied to run only on a specific processor • can be pinned to a specific processor • kernel threads for OS device drivers and other kernel functions • all scheduling done on kernel level threads
Operating Systems: Threads • lightweight processes (LWP) • one kernel thread per LWP • LWPs scheduled with associated kernel thread • a pre-emptive priority-based scheduler • can have several LWPs per process • user-level threads • only user-level threads perform user’s work • each has to be connected to an LWP to be scheduled • LWPs can be blocked • need as many LWPs as number of concurrent kernel operations • can be multiplexed around available LWPs dynamically or tied to one • does not require kernel interaction to do connection • may have to wait for a free LWP to be connected to • can synchronise amongst themselves
Operating Systems: Threads • Solaris threads resource needs : • kernel threads : • small data structure and stack • context switching between kernel threads relatively fast • lightweight processes : • need a process control block (PCB) • may be quite slow • user level threads : • program counter, stack and pointer needed • no kernel resources involved • connecting user level threads to LWPs very fast • may be lots of user level threads and fewer LWPs • kernel only sees LWPs
Operating Systems: Threads POSIX Threads • system of choice for portability • similar to Solaris threads • incompatible with Microsoft Win32 NT threads! • textbook • Pthreads Primer - A Guide to Multithreaded Programming, Lewis & Berg • primitives :int pthread_create (pthread_t *ID, pthread_attr *attr, void *(*func)(void *ptr), void *arg); int pthread_join (pthread_t ID, void *arg); int pthread_mutex_init (pthread_mutex_t *m, pthread_mutex_attr *attr); int pthread_lock (pthread_mutex_t *m); int pthread_unlock (pthread_mutex_t *m); int pthread_cond_init (pthread_cond_t *c, pthread_cond_attr *attr); int pthread_cond_wait (pthread_cond_t *c, pthread_mutex_t *m); int pthread_cond_signal (pthread_cond_t *c); etc. etc.
Operating Systems: Threads • Example : partitioned matrix multiplication : • partition each matrix into quarters: M1 : A1 B1 M2 : A2 B2 C1 D1 C2 D2 M1 * M2 = A1*A2 + B1*C2 A1*B2 + B1*D2C1*A2 + D1*C2 C1*B2 + D1*D2 • multiplication procedure for each thread, written to deal with any quarters • thread procedure arguments passed by pointer to structures • first version uses separate argument structures for each thread • second version uses one structure but then needs to synchronise use of it by means of semaphores - just for demo purposes • also uses semaphores to synchronise thread termination • semaphore package built from mutex functions and condition variables • both versions do a normal N*N multiplication first for result comparison
Operating Systems: Threads #include <pthread.h> struct args { float (*p)[N]; int px0, py0; float (*q)[N]; int qx0, qy0; float (*r)[N]; int n2; }; void fill_args (struct args *args_ptr, float (*p)[N]; int px0, py0; float (*q)[N]; int qx0, qy0; float (*r)[N]; int n2; ) { args_ptr->p = p; args_ptr->px0 = px0; args_ptr->q = q; args_ptr->qx0 = qx0; args_ptr->r = r; args_ptr->rx0 = rx0; args_ptr->n2 = n2; } void *matrix_mult (void *ptr) { float (*p)[N], (*q)[N], (*r)[N], sum; int px0, py0, qx0, qy0, n2, px, py, qx, qy, i, j; p = ((struct args *)ptr)->p; px0 = ((struct args *)ptr)->px0; py0 = ((struct args *)ptr)->py0; q = ((struct args *)ptr)->q; qx0 = ((struct args *)ptr)->qx0; qy0 = ((struct args *)ptr)->qy0; r = ((struct args *)ptr)->r; n2 = ((struct args *)ptr)->n2; for (px=px0; px<px0+n2; px++) { for (qy=qy0; qy<qy0+n2; qy++) { sum = 0; for (py=py0, qx=qx0; py<py0+n2; py++, qx++) sum = sum+p[px][py]*q[qx][qy]; r[px][qy] = sum; } }}
Operating Systems: Threads main () { float p[N][N], q[N][N], r[N][N], r1[N][N], r2[N][N]; pthread_t mmt, a1a2, b1c2, a1b2, b1d2, d1c2, c1,b2, d1d2; struct args mmt_args, a1a2_args, b1c2_args, a1b2_args, b1d2_args, c1a2_args, d1c2_args, c1b2_args, d1d2_args; int i, j; void *status; // arbitrary matrix values for testing for (i=0; i<N; i++) { for (j=0; j<N; j++) { p[i][j] = i*j; q[i][j] = i*j; } } // normal N*N multiplication first with one thread fill_args (&mmt_args, p, 0, 0, q, 0, 0, r, N); pthread_create (&mmt, NULL, matrix_mult, (void *)&mmt_args); // print results printf(“\nSingle thread result :\n”); for (i=0; i<N; i++) { for (j=0; j<N; j++) { printf(“%4.0f “, r[I][j]); } printf(“\n”); }
Operating Systems: Threads fill_args (&a1a2_args, p, 0, 0, q, 0, 0, r1, N/2); pthread_create (&a1a2, NULL, matrix_mult, (void *)&a1a2_args); fill_args (&b1c2_args, p, 0, N/2, q, N/2, 0, r2, N/2); pthread_create (&b1c2, NULL, matrix_mult, (void *)&b1c2_args); fill_args (&a1b2_args, p, 0, 0, q, 0, N/2, r1, N/2); pthread_create (&a1b2, NULL, matrix_mult, (void *)&a1b2_args); fill_args (&b1d2_args, p, 0, N/2, q, N/2, N/2, r2, N/2); pthread_create (&b1d2, NULL, matrix_mult, (void *)&b1d2_args); fill_args (&c1a2_args, p, N/2, 0, q, 0, 0, r1, N/2); pthread_create (&c1a2, NULL, matrix_mult, (void *)&c1a2_args); fill_args (&d1c2_args, p, N/2, N/2, q, N/2, 0, r2, N/2); pthread_create (&d1c2, NULL, matrix_mult, (void *)&d1c2_args); fill_args (&c1b2_args, p, N/2, 0, q, 0, N/2, r1, N/2); pthread_create (&c1b2, NULL, matrix_mult, (void *)&c1b2_args); fill_args (&d1d2_args, p, N/2, N/2, q, N/2, N/2, r2, N/2); pthread_create (&d1d2, NULL, matrix_mult, (void *)&d1d2_args);
Operating Systems: Threads pthread_join (a1a2, &status); pthread_join (b1c2, &status); pthread_join (a1b2, &status); pthread_join (b1d2, &status); pthread_join (c1a2, &status); pthread_join (d1c2, &status); pthread_join (c1b2, &status); pthread_join (d1d2, &status); // final summation for (i=0; i<N; i++) { for (j=0; j<N; j++) { r[I][j] = r1[I][j] + r2[I][j]; } } // print results printf(“\nMultiple thread result :\n”); for (i=0; i<N; i++) { for (j=0; j<N; j++) { printf(“%4.0f “, r[I][j]); } printf(“\n”); } }
Operating Systems: Threads • Semaphore package : typedef struct semaphore { pthread_mutex_t m; pthread_cond_t c; int count; } sema_t; void sema_init (sema_t *s) { pthread_mutex_init (&s->m, NULL); pthread_cond_init(&s->c, NULL); s->count = 0; } void sema_P (sema_t *s) { pthread_mutex_lock (&s->m); while (s->count == 0) { pthread_cond_wait (&s->c, &s->m); } s->count--; pthread_mutex_unlock (&s->m); } void sema_V (sema_t *s) { pthread_mutex_lock (&s->m); s->count++; pthread_mutex_unlock (&s->m); pthread_cond_signal (&s->c); }
Operating Systems: Threads #include <pthread.h> struct args { float (*p)[N]; int px0, py0; float (*q)[N]; int qx0, qy0; float (*r)[N]; int n2; sema_t *args_sem, *fin_sem }; void fill_args ( struct args *args_ptr, float (*p)[N]; int px0, py0; float (*q)[N]; int qx0, qy0; float (*r)[N]; int n2; sema_t *args_sem, sema_t *fin_sem ) { args_ptr->p = p; args_ptr->px0 = px0; args_ptr->q = q; args_ptr->qx0 = qx0; args_ptr->r = r; args_ptr->rx0 = rx0; args_ptr->n2 = n2; args_ptr->args_sem = args_sem; args_pts->fin_sem = fin_sem; }
Operating Systems: Threads void *matrix_mult (void *ptr) { float (*p)[N], (*q)[N], (*r)[N], sum; int px0, py0, qx0, qy0, n2, px, py, qx, qy, i, j; p = ((struct args *)ptr)->p; px0 = ((struct args *)ptr)->px0; py0 = ((struct args *)ptr)->py0; q = ((struct args *)ptr)->q; qx0 = ((struct args *)ptr)->qx0; qy0 = ((struct args *)ptr)->qy0; r = ((struct args *)ptr)->r; n2 = ((struct args *)ptr)->n2; // signal that arguments have been copied out sema_V (((struct args *)ptr)->args_sem); for (px=px0; px<px0+n2; px++) { for (qy=qy0; qy<qy0+n2; qy++) { sum = 0; for (py=py0, qx=qx0; py<py0+n2; py++, qx++) sum = sum+p[px][py]*q[qx][qy]; r[px][qy] = sum; } } // signal that this thread has finished sema_V (((struct args *)ptr)->fin_sem);}
Operating Systems: Threads main () { float p[N][N], q[N][N], r[N][N], r1[N][N], r2[N][N]; pthread_t mmt, a1a2, b1c2, a1b2, b1d2, d1c2, c1,b2, d1d2; struct args mmt_args; int i, j, t; void *status; sema_t args_sem, fin_sem; // arbitrary matrix values for testing for (i=0; i<N; i++) { for (j=0; j<N; j++) { p[i][j] = i*j; q[i][j] = i*j; } } sema_init (&args_sem); sema_init (&fin_sem); // normal N*N multiplication first with one thread fill_args (&mmt_args, p, 0, 0, q, 0, 0, r, N, &args_sem, &fin_sem); pthread_create (&mmt, NULL, matrix_mult, (void *)&mmt_args); sema_P (&args_sem); // wait until arguments copied sema_P (&fin_sem); // wait until thread finished // print results . . . . etc.
Operating Systems: Threads • fill_args (&mmt_args, p, 0, 0, q, 0, 0, r1, N/2, &args_sem, &fin_sem); pthread_create (&a1a2, NULL, matrix_mult, (void *)&mmt_args); sema_P (&args_sem); // wait until arguments read • fill_args (&mmt_args, p, 0, N/2, q, N/2, 0, r2, N/2, &args_sem, &fin_sem); pthread_create (&b1c2, NULL, matrix_mult, (void *)&mmt_args); sema_P (&args_sem); • fill_args (&mmt_args, p, 0, 0, q, 0, N/2, r1, N/2, &args_sem, &fin_sem); pthread_create (&a1b2, NULL, matrix_mult, (void *)&mmt_args); sema_P (&args_sem); • fill_args (&mmt_args, p, 0, N/2, q, N/2, N/2, r2, N/2, &args_sem, &fin_sem); pthread_create (&b1d2, NULL, matrix_mult, (void *)&mmt_args); sema_P (&args_sem); fill_args (&mmt_args, p, N/2, 0, q, 0, 0, r1, N/2, &args_sem, &fin_sem); pthread_create (&c1a2, NULL, matrix_mult, (void *)&mmt_args); sema_P (&args_sem); • . . . . . . . . etc. for (t=0; t<8; t++) sema_P (&fin_sem); // wait for all threads to finish // final summation and print results etc. . . . . . . .
Operating Systems: Threads Java Threads • Example showing interleaved thread execution : class SimpleThread extends Thread { public SimpleThread (String str) { // superclass constructor super (str); } public void run () { for (int i=0; i<10; i++) { System.out.println (i + “ “ + getName() ); try { sleep ((int) (Math.random () * 1000)); catch (InterruptedException e) { } } System.out.println (“Finished “ + getName () ); } } class TwoThreadsTest { public static void main (String[ ] args) { new SimpleThread (“Edinburgh”).start (); new SimpleThread (“Glasgow”).start (); } }
Operating Systems: Threads • main method starts two threads by calling the start method • output something like : 0 Edinburgh 0 Glasgow 1 Glasgow 1 Edinburgh 2 Edinburgh 3 Edinburgh 2 Glasgow 3 Glasgow 4 Glasgow 4 Edinburgh 5 Glasgow 5 Edinburgh 6 Glasgow 7 Glasgow 8 Glasgow 6 Edinburgh 7 Edinburgh 8 Edinburgh 9 Edinburgh Finished Edinburgh 9 Glasgow Finished Glasgow
Operating Systems: Threads Windows NT Threads • initial thread built automatically for a process • more created through calls to thread library • each thread has its own user and kernel stacks • 32 levels of priority (Java threads only have 10) • pre-emptive priority scheduler • threads can change their priority within limits • mutual exclusion locks between threads • between processes and within one process • event objects for synchronisation • semaphores with resource counts • more than one thread can get a semaphore when multiple resources controlled by it • fibers in NT Version 4 onwards • finer user control of scheduling • all other threads signalled when one terminates