Download

1 / 31
350 likes | 730 Views
4. Molecular Similarity. Similarity and Searching. Historical Progression Similarity Measures Fingerprint Construction “Pathological” Cases MinMax- Counts Pruning Search Space Aggregate Queries LSH. Historical Progression. Maximum Common Subgraph-Isomorphism (MCS)

E N D
Similarity and Searching • Historical Progression • Similarity Measures • Fingerprint Construction • “Pathological” Cases • MinMax- Counts • Pruning Search Space • Aggregate Queries • LSH 2
Historical Progression • Maximum Common Subgraph-Isomorphism (MCS) • maximum common substructure between to molecules. • “NP-complete” • Structural Keys • dictionary of predetermined, domain-specific sub-structures keyed to particular positions in a bit-vector constructed for each molecule • similarity computed between bit-vectors (fast O(D) scan) • 2D Compressed Fingerprints • ALL substructures stored in a bit-vector using a hashing scheme plus lossy compression (modulo operator) • Similarity computed between bit-vectors or count vectors • Faster Searches • database pruning • locality sensitive hashing (LSH): towards O(log n) similarity searching 3
Superstructure and Substructure Searches • A is a superstructure of B (ignoring H) • B is a substructure of A • Tversky similarity B A 4
The Similarity Problem How similar? 5
Spectral Similarity • Count substructures • Compare the count/bit vectors 6
2D Graph Substructures • For chemical compounds • atom/node labels: A = {C,N,O,H, … } • bond/edge labels: B = {s, d, t, ar, … } • Trace ALL Paths • O(N*dl) • Cycles and trees • Combinatorial Space (CsNsCdO) 7
Mapping Structures to Bits • Compact data representation • Hash each path to bit vector Feature space → Bit space • Resolve clashes with OR operator (i.e 1+1=1) 8
Similarity Measures • There are many ways of measuring similarity (or distance) between bit/count vectors: • Euclidean • Cosine • Exponentials • Tanimoto/Jaccard • Tversky • MinMax • And many more (L1,L2,Lp,Hamming, Manhattan,….) 9
A B a c b Similarity Measures: Tanimoto • Tally features: • Unique (a,b) • Both on (c) • Both off (d) • Similarity Formula • Tanimoto=c/(a+b+c) 12
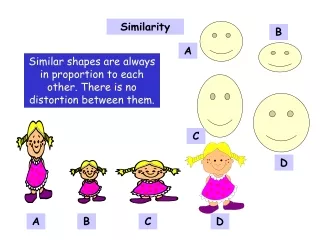
The Fingerprint Approximation • Fingerprint bit similarity approximates chemical feature similarity. 13
A B a c b Similarity Measures: Tversky • Tally features: • Unique (a,b) • Both on (c) • Both off (d) • Similarity Formula • Tanimoto=c/(a+b+c) • Tversky(α,β)=c/(αa+βb+c) 14
Pathological Cases On the Properties of Bit String-Based Measures of Chemical Similarity. Flower DR, J. Chem. Inf. Comput. Sci. 1998, 38, 379-386 15
Pathological Cases Issue of labeling scheme. 16
Counts • MinMax similarity is a generalization of Tanimoto which uses the counts. • MinMax can work better than Tanimoto. 17
Pruning Search Space Using Bounds • Linear speedup (search CxD) for fixed threshold, often by one order of magnitude or more. • Sub-linear speedup (search CxD0.6) for top K. 18
Speedup from Pruning Speedup depends on: • Threshold • Query • Fingerprint length • Database size 20
Two Basic Strategies • Similar to bioinformatics • Aggregate individual pairwise measures • Build a fingerprint profile • Linear approaches • Non-linear approaches (consensus, modal, etc) • Hybrid (profile + aggregation/”scaling”)) • Profile-profile 27
Aggregations 28
Consensus Fingerprints • Create consensus fingerprint • Search database using the consensus & = 29
Local Sensitive Hashing • Bin fingerprints based on projections onto randomly directed vectors • log D random vectors → O(log D) • Search for neighbors by returning bin corresponding to the query’s projection • Has been used for clustering. May be useful for building diverse data sets. Not yet developed for searching 30
Outline • Historical Progression • Similarity Measures • Fingerprint Construction • Pathologic Cases • MinMax- Counts • Pruning Search Space • Aggregate Queries • LSH 31