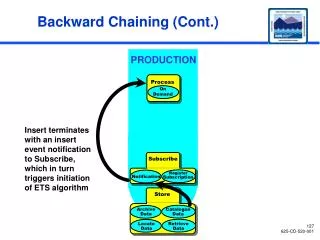
Download

1 / 21
350 likes | 1.05k Views
Backward chaining. Assume the same representation of rules as in forward chaining, i.e. If <antecedent 1> is true, <antecedent 2> is true, … <antecedent i> is true Then <consequent> is true.

E N D
Backward chaining Assume the same representation of rules as in forward chaining, i.e. If <antecedent 1> is true, <antecedent 2> is true, … <antecedent i> is true Then <consequent> is true. Rule interpretation starts with (i) an empty fact base, and (ii) a list of goals which the system tries to derive, and consists of the following steps: • Form a stack initially composed of all “top-level” goals. • Consider the first goal from the stack, and gather all of the rules capable of satisfying this goal. • For each of these rules, examine the rule’s premises: • If all premises are satisfied, execute the rule to infer its conclusion, and remove the satisfied goal from the stack.
Backward chaining (cont.) • If there is a premise which is not satisfied, look for rules by means of which this premise can be derived; if such rules exist, add the premise as a sub-goal on the top of the stack, and go to 2. • If no rule exists to satisfy the unknown premise, place a query to the user and add the supplied value to the fact base. If the premise cannot be satisfied, consider the next rule which has the initial goal as its conclusion. • If all rules that can satisfy the current goal have been attempted, and all failed, then the goal is unsatisfiable; remove the unsatisfiable goal from the stack and go to 2. If the stack is empty (i.e. all of the goals have been satisfied) stop.
The fruit identification example Assuming that we do not have any information about the object that we are trying to recognize, let the “top-level” goal be (fruit = (? X)). Step1Initial fact base: ( ) Initial stack of goals: ((fruit = (? X))) Step 2 Rules capable of satisfying this goal are: 1, 1A, 6, 7, 8, 9, 10, 11, 12, 13, 13A, 13B. Step 3 Consider Rule 1. Its first premise is (shape = long). There is no data in the FB matching this premise and no rule has (shape = (? Y)) as its conclusion. Therefore, a query is placed to the user to acquire for the shape of the fruit under consideration. Assume that the user replies that the fruit is round, i.e. the current FB becomes Current fact base: ((shape = round)). Rule 1 fails, and Rule 6 is examined next. The first premise of Rule 6 results in a new goal which is added at the beginning of the current stack of goals. Current stack of goals: ((fruitclass = (? Y)) (fruit = (? X)))
The fruit identification example (cont.) There are three rules capable of satisfying the newly stated goal, namely 2, 2A, and 3.The first premise of Rule 2, (shape = round), matches a datum in the FB. The second premise leads to a new query regarding the diameter of the fruit. Assume that the answer is (diameter = 1 inch). Current fact base: ((shape = round)(diameter = 1 inch)). Rules 2 and 2A fail, and Rule 3 is examined next. It succeeds, thus a new conclusion, (fruitclass = tree) is added to the FB and the first goal is removed from the current stack of goals. Current fact base: ((shape = round)(diameter = 1 inch)(fruitclass = tree)). Now Rules 6, 7 and 8 fail, and Rule 9 is examined next. Its first premise succeeds, but its second premise places a new query regarding the color of the fruit. Assume that the user enters (color = red), which fails Rules 9 and 10. The first two premises of Rule 11 are satisfied, the third premise places a query regarding the seedclass. Rules 4 and 5 have conclusions (seedclass = (? Z)), which becomes a new subgoal. Rule 4 only premise (seedcouunt = 1) cannot be dirived by any rule --> place a query to the user about the seedcount and assume that the answer is (seedcouunt = 1). Rule 4 succeeds and (seedclass = stonefruit), is added to the FB resulting in all premisses of Rule 11 to hold and its conclusion (fruit = cherry) is added to the FB. Note that this proves our top-level goal. Current fact base: ((shape = round)(diameter = 1 inch)(fruitclass = tree)(color = red)(seedcount = 1)(seedclass = stonefruit)(fruit = cherry)). Current stack of goals: () Step 4 Stop, no more goals remain to be proved.
Mixed modes of chaining Consider the following set of rules: Rule 1: F & H => K Rule 2: E & A => K Backward chaining rules Rule 3: E & B => H Rule 4: A & G => B Rule 5: B & D => H Rule 6: G & D => E Forward chaining rules Rule 7: A & B => D Rule 8: A & C => G Assume that A and C are the only known facts, and we want to infer K (the only top-level goal). Because the set of rules is divided into two subsets, backward and forward chaining rules, the are two ways in which these rules can be applied: • Forward chaining rules have a higher priority, thus they are the first ones to be tried. • Backward chaining rules have a higher priority.
Priority to forward chaining rules (example cont.) Assuming that the forward chaining rules have a higher priority, the inference process is carried out as follows, given FB: (A, C) and goal K. Step 1: Attempt to fire only forward chaining rules for as long as possible. Rule 8 fires thus the current FB becomes (A, C, G) Rule 4 fires thus the current FB becomes (A, C, G, B) Rule 7 fires thus the current FB becomes (A, C, G, B, D) Rule 5 fires thus the current FB becomes (A, C, G, B, D, H) Rule 6 fires thus the current FB becomes (A, C, G, B, D, H, E) Step 2: If no more forward chaining rules can fire, and the goal has not been derived, proceed with the backward chaining rules. Rule 1 is attempted, but fails. Rule 2 succeeds, thus K is proven.
Priority to backward chaining rules (example cont.) Assuming that the backward chaining rules have a higher priority, the inference process is carried out as follows: Step 1: Search for a backward chaining rule which has K as its conclusion. Rule 1 is such a rule, which will fire only if F and H are satisfied. Therefore, F and H become new goals. Step 1A: Search for a backward chaining rule whose conclusion is F. There is no such a rule, therefore this goal fail. Step 1B: Search for a backward chaining rule whose conclusion is H. Rule 3 is such a rule, and it in turn creates two new goals, E and B. However, there are no backward chaining rules whose conclusions are F, E or B, which is why the forward chaining rules must be activated next.
Priority to backward chaining rules (example cont.) Step 2: Given the fact base (A, C), forward chaining rules will fire in the following order: Rule 8 fires thus the current FB becomes (A, C, G). Rule 4 fires thus the current FB becomes (A, C, G, B). The derivation of B satisfies one of the goals on the stack of goals. The remaining goals are F and E. Rule 7 fires thus the current FB becomes (A, C, G, B, D). Rule 5 fires, thus the current FB becomes (A, C, G, B, D, H). Rule 6 fires, thus the current FB becomes (A, C, G, B, D, H, E). The derivation of E satisfies one of the current goals, which leaves F as the only goal that remains to be proved. However, no more forward chaining rules can fire meaning that F cannot be proved by either forward chaining or backward chaining rules. Step 3: Because our top-level goal was to prove K, we look for another backward chaining rule, which has K as its conclusion. Rule 2 is such a rule, and it can fire because both of its premises are satisfied at this point, thus proving our original goal K.
Completeness of the chaining algorithms Consider the following set of sentences: x hungry(x) => likes(x, apple) x ¬hungry(x) => likes(x, grapes) x likes(x,apple) => likes(x, fruits) x likes(x,grapes) => likes(x, fruits) Assume that we want to prove likes(Bob, fruits). Obviously, this is true if likes(Bob, apple) v likes(Bob, grapes) is true, which is always true, because the first disjunct depends on hungry(Bob) and the second disjunct depends on ¬hungry(Bob). None of the chaining algorithms, however, will allow us to infer likes(Bob, fruits). The reason is that x ¬hungry(x) => likes(x, grapes) is not a Horn formula. Chaining algorithms, which use the generalized MP as the only inference rule, are incomplete for non-Horn KBs.
Why do we need a stronger inference rule? Consider the following example: Bob wants to take CS 501 next semester. This class will meet either MW 6:45 -- 8:00, or TR 6:45 -- 8:00. Bob has to be at his soccer sessions MTF 5:30 -- 8:30. Can he take CS 501? Initial KB: MW(CS501, 645--800) v TR(CS501, 645--800) MW(CS501, 645--800) & Busy(Bob, M, 530--830) => nogood-class(Bob) TR(CS501, 645--800) & Busy(Bob, T, 530--830) => nogood-class(Bob) Busy(Bob, M, 530--830) Busy(Bob, T, 530--830) Possible inferences: MW(CS501, 645--800) => nogood-class(Bob) …. (A) TR(CS501, 645--800) => nogood-class(Bob) ….. (B)
The resolution rule can help We can draw more inferences if we look at MW(CS501, 645--800) v TR(CS501, 645--800) as describing two different cases: • Case 1: MW(CS501, 645--800) is true, in which case nogood-class(Bob) is true by means of (A). • Case 2: TR(CS501, 645--800) is true, in which case nogood-class(Bob) is true by means of (B). The answer to the initial query is derived no matter which is the right case. This type of reasoning is called case analysis, and it can be carried out by means of the resolution rule as follows: ¬MW(CS501, 645--800) v nogood-class(Bob) MW(CS501, 645--800) v TR(CS501, 645--800) nogood-class(Bob) v TR(CS501, 645--800) ¬TR(CS501, 645--800) v nogood-class(Bob) nogood-class(Bob) v nogood-class(Bob) nogood-class(Bob)
The resolution rule revisited Recall the resolution rule for propositional logic: (A v B, ¬B v C A v C) (¬A => B, B => C ¬A => C) There are two different ways to interpret this rule: • As describing 2 cases, namely • B is true, ¬B is false, in which case C is true. • ¬B is true, B is false, in which case A is true. In both cases, A v C is true. • Because the implication operation is transitive, the resolution rule let us link the premise of one implication with the conclusion of the second implication, ignoring intermediate sentence B, i.e. let us derive a new implication. None of these can be done with MP, because MP derives only atomic conclusions.
Consider the following propositional version of generalized MP: A1 & A2 & … & Am => B D1 & D2 & … & Dn => C From these two formulas, we can infer the following one making use of the monotonicity of the PL: A1 & A2 & … & Am & D1 & D2 & … & Dn => B Assume now that B = B1 v B2 v … v Bk, and C = Ai A1 & A2 & … & Am => B1 v B2 v … v Bk D1 & D2 & … & Dn => C A1 & A2 & …& A(i-1) & D1 & D2 & … & Dn & A(i+1) & … & Am => B1 v B2 v … v Bk Consider the following cases: • If A’s hold, then at least one B holds. • If m = 0, then our formula degenerates to a form B1 v B2 v … v Bk • If k = 1, then our formula has the form A1 & A2 & … & Am => B1
If k = 0, then A1 & A2 & … & Am => False, which is equivalent to ¬(A1&A2&…&Am), which is in turn equivalent to ¬A1 v … v ¬Am. Note that at the same time m = 1, then we can represent negated formulas such as ¬student(Bob), or in its equivalent form, student(Bob) => False. If m = 0, then we have True => False, which represents a contradiction. That is, formulas of the form A1 & A2 & … & Am => B1 v … v Bk are general enough to represent any logical formula. If a KB is comprised of only formulas of this type, we say that it is in a normal form. We need a generalized version of the resolution rule to work with such KBs.
The generalized resolution rule: definition Generalized resolution is the following rule of inference: A1 & A2 & … & Am => B1 v B2 v … v Bk D1 & D2 & … & Dn => C1 v C2 v … v Cx A1 & … & Ai & … & Am & D1 & … & Dn => B1 v … v Bk v C1 v… v Cj v… v Cx Here Ai = Cj, which is why we can ignore them from the l.h.s. and r.h.s. of the implication, respectively. Here is the alternative version of generalized resolution: A1 v A2 v … v Ai v … v Ap C1 v C2 v … v Cj v … v Ck A1 v A2 v … v Ai v… v Ap v C1 v… v Cj v… v Cx Here Ai = ¬Cj, which is why we can ignore them both.
Proving formulas by the resolution rule If we have a FOL KB, then Ai and Cj (in the first case, or ¬Cj in the second case), will be the same if there is a substitution such that subst(, Ai) = subst(, Cj) (or subst(, Ai) = subst(, ¬Cj), respectively). Assuming that all formulas in the KB are in a normal form, we can apply the resolution rule in forward or backward chaining algorithms. Example: Consider the following KB ¬P(w) v Q(w), P(x) v R(x), ¬Q(y) v S(y), ¬R(z) v S(z). Using forward chaining, the following conclusions can be derived: ¬P(w) v Q(w) ¬Q(y) v S(y) {y / w} These are ¬P(w) v S(w) P(x) v R(x) called {w / x} resolvents. S(x) v R(x) ¬R(z) v S(z). {x /A, z /A} S(A) v S(A) S(A)
Completeness of the chaining process with the resolution rule Chaining with the resolution rule is still an incomplete inference procedure. To see why, consider an empty KB from which you want to derive P v ¬P. Note that this is a valid formula, therefore it follows from any KB including the empty KB. However, using only the resolution rule, we cannot prove it. Assume that we add ¬(P v ¬P) (¬P & P) (¬P, P). Adding a negation of a valid formula to the exiting KB introduces a contradiction in that KB. If we can prove that KB & ¬A => False, where KB |= A, then we prove that KB |-- A. In the example above { P , ¬P} => Nil, which proves P v ¬P.
The refutation method The inference procedure that proves a formula by showing that its negation, if added to the KB, leads to a contradiction is called refutation. The following procedure implements the refutation method: • Negate the theorem to be proved, and add the result to the set of axioms. • Put a list of axioms into a normal form • Until there is no resolvable pair of clauses do: • Find resolvable clauses, and resolve them. • Add the result of the resolution to the list of clauses. • If Nil is produced, stop (the theorem has been proved by refutation). • Stop (the theorem is false). The refutation method is a complete inference procedure.
Example Consider the following set of axioms: ¬hungry(w) v likes(w, apple) hungry(x) v likes(x, grapes) ¬likes(y,apple) v likes(y, fruits) ¬likes(z,grapes) v likes(z, fruits) Assume that we want to prove likes(Bob, fruits). Therefore, we must add ¬likes(Bob, fruits) to the set of axioms. ¬hungry(w) v likes(w, apple) ¬likes(y,apple) v likes(y, fruits) {y / w} ¬hungry(w) v likes(w, fruits) hungry(x) v likes(x, grapes) {w / x} likes(x, fruits) v likes(x, grapes) ¬likes(z,grapes) v likes(z, fruits) {z / x} likes(x, fruits) ¬likes(Bob, fruits) {x / Bob} Nil
Problems with the resolution rule The resolution proof is exponential, which is why we must use some strategies to direct it. The following two ideas can help here: • Every resolution involves the negated theorem or a derived clause which has used the negated theorem directly or indirectly. • Always remember what your goal is, so that given what you currently have, you can find the difference, and using your intuition try to reduce this difference to get closer to the goal. This ideas can be implemented as resolution strategies working at a meta- logical level. Among the most popular strategies are the following: • Unit preference. Always prefer a single literal when doing resolution. This strategy was found efficient only for relatively small problems. • Set of support. The current resolution involves the negated theorem or the new clauses directly or indirectly involving it. The set of such clauses plus the theorem are called the support set. Initially, the support set involves only the negated theorem.
Resolution strategies (cont.) • The breadth-first strategy. First resolve all possible pairs of initial clauses, then resolve all possible pairs of the resulting set together with the initial set, and so on. • Input resolution. Every resolution uses one of the initial clauses or the negated theorem. If we allow resolutions to use also clauses where one clause is an ancestor or another clause, we have the strategy called linear resolution. • Subsumption. Eliminate all sentences subsumed by other sentences. For example, if P(x) KB, then P(A) will not be added if inferred, because it is subsumed by P(x). Note that in order to apply the refutation method, we must first convert the initial set of sentences into a normal form.