Download

1 / 12
120 likes | 390 Views
Klastering dengan K-Means. Tujuan. Mahasiswa mampu mendeskripsikan konsep dasar klastering K-means dalam hal algoritma, kelemahan dan penerapannya. Pendahuluan. K-mean merupakan teknik klastering yang paling umum dan sederhana.

E N D
Tujuan • Mahasiswa mampu mendeskripsikan konsep dasar klastering K-means dalam hal algoritma, kelemahan dan penerapannya
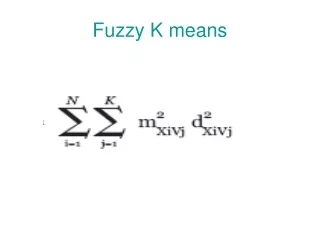
Pendahuluan • K-mean merupakan teknik klastering yang paling umum dan sederhana. • Tujuan klastering ini adalah mengelompokkan obyek ke dalam k klaster/kelompok. • Nilai k harus ditentukan terlebih dahulu (berbeda dengan hierarchical clustering). • Ukuran ketidakmiripan masih tetap digunakan untuk mengelompokkan obyek yang ada.
Algoritma K-means • Secara ringkas algoritma K-means adalah sebagai berikut: • Pilih jumlah klaster k • Inisialisasi k pusat klaster • Tempatkan setiap data/obyek ke klaster terdekat • Perhitungan kembali pusat klaster • Ulangi langkah 3 dengan memakai pusat klaster yang baru. Jika pusat klaster tidak berubah lagi maka proses pengklasteran dihentikan.
Penentuan Jumlah dan Pusat Klaster • Inisialisasi atau penentuan nilai awal pusat klaster dapat dilakukan dengan berbagai macam cara, antara lain: • Pemberian nilai secara random • Pengambilan sampel awal dari data • Penentuan nilai awal hasil dari klaster hirarki dengan jumlah klaster yang sesuai dengan penentuan awal. • Dalam hal ini biasanya user memiliki pertimbangan intuitif karena dia memiliki informasi awal tentang obyek yang sedang dipelajari, termasuk jumlah klaster yang paling tepat.
Penempatan Obyek ke Dalam Klaster • Penempatan obyek ke dalam klaster didasarkan pada kedekatannya dengan pusat klaster • Dalam tahap ini perlu dihitung jarak tiap data ke tiap pusat klaster yang telah ditentukan. • Jarak paling dekat antara suatu data dengan pusat klaster tertentu merupakan hal penentu data tersebut akan masuk klaster yang mana.
Perhitungan Kembali Pusat Klaster • Pusat klaster ditentukan kembali dengan cara dihitung nilai rata-rata data/obyek dalam klaster tertentu. • Jika dikehendaki dapat pula digunakan perhitungan median dari anggota klaster yang dimaksud • Mean bukan satu-satunya ukurang yang bisa dipakai • Pada kasus tertentu pemakaian median memberikan hasil yang lebih baik. Karena median tidak sensitif terhadap data outlier (data yang terletak jauh dari yang lain, meskipun dalam satu klaster - pencilan) • Contoh: • Mean dari 1, 3, 5, 7, 9 adalah 5 • Mean dari 1, 3, 5, 7, 1009 adalah 205 • Median dari 1, 3, 5, 7, 1009 adalah 5
Keterbatasan K-means • K-means sangat bergantung pada penentuan nilai pusat klaster awal • Penentuan nilai awal yang berbeda dapat memberikan hasil akhir yang berbeda.
Komentar pada Metoda K-Means • Strength • Relatively efficient: O(tkn), dimana n adalah # objects, k adalah # clusters, dan t merupakan # iterations. Umumnya, k, t << n. • Biasanya berhenti pada nilai optimum lokal (local optimum). Nilai global optimum dapat ditentukan dengan menggunakan teknik seperti deterministic annealing dan genetic algorithms • Weakness • Dapat diterapkan hanya saat nilai mean telah ditentukan, bagaimana untuk data-data bersifat kategori? • Perlu ditentukan k, jumlah klaster • Tidak dapat menangani noisy data dan outliers • Tidak tepat untuk membentuk klaster dengan data non-convex shapes
The K-Means Clustering Method • Example
Tugas • Carilah bahan bacaan (dapat dari jurnal, artikel, ataupun buku-buku referensi) untuk diskusi kelompok mengenai hal-hal berikut: • Adakah kemungkinannya jika k-means dipakai untuk mengklasifikasikan data yang tidak bersifat numeris, misalnya dokumen • Bagaimanakah caranya? • Adakah penelitian yang membuktikan bahwa outlier dapat ditangani dalam k-means, jelaskan? • Bagaimanakah nilai optimum k klaster dapat dicapai dalam metoda k-means?