Download

1 / 21
210 likes | 389 Views
OAI. What I’ll cover. What is OAI, and why it was developed How it’s used How it works The records themselves: examples How you can use it. What is OAI?. Began in 1990 as a method for sharing open access repositories Started by the folks who run (ran) arXiv

E N D
What I’ll cover • What is OAI, and why it was developed • How it’s used • How it works • The records themselves: examples • How you can use it
What is OAI? • Began in 1990 as a method for sharing open access repositories • Started by the folks who run (ran) arXiv • OAI stands for Open Archives Initiative “…develops and promotes interoperability standards that aim to facilitate the efficient dissemination of content.”
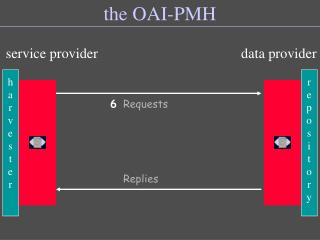
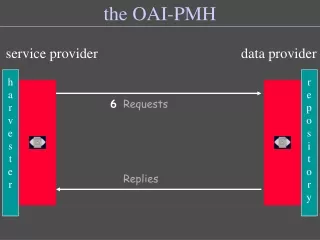
THIS kind of sharing • On one side are those who have resources they want to share: data providers • On the other side are those who would like to use resources offered: service providers
Examples of data providers • Deep Blue: as a DSpace implementation • DLPS/DLXS collections: home-grown • MBooks: home-grown • And over 1000 more… (over 500K records just from UM alone)
Examples of service providers • OAIster: all OAI repositories • OpenDOAR: open access repositories • BASE: scientific repositories • CARL/ABRC: Canadian repositories • Sheet Music Consortium
OAI-PMH • Open Archives Initiative Protocol for Metadata Harvesting • Designed to be simple to implement • Consists of 6 verbs • Data provider software ranges from turnkey solutions to home-grown tools
The verbs • Identify: will tell you about the data provider, give context, indicate if conforms to aspects of the protocol • ListMetadataFormats: simple Dublin Core is required (oai_dc), others are encouraged • ListSets: how has the data provider categorized their records?
The verbs • ListIdentifiers: if you’re interested only in accessing the OAI identifiers • ListRecords: if you want all the records • GetRecord: if you want only one record • Notice the resumptionToken and completeListSize attribute
Harvesting • Harvester software is used to retrieve the records shared by the data provider • Majority of harvesters are open-source and non-proprietary • UM Libraries has built its own, soon to be provided via SourceForge • written in Perl, open-source, Unix platform
What’s out there to harvest? • All subjects and formats • Some repositories are “good” and some not so good-- check with me! • XML errors • incorrect UTF-8 encoding • Around 400 repositories provide MARC in one flavor or another
Texts • Pre- and post-prints • arXiv: site, harvest • Digitized books • Project Gutenberg (through Internet Archive): site, harvest • Journals • Entomotropica (PKP system): site, harvest • DOAJ: site, harvest (descriptions), harvest (articles)
Images • By location • PictureAustralia: site, harvest • Cleveland Memory (ContentDM system): site, harvest • By collection (in the library sense) • U. Utah (also ContentDM): site, harvest
Datasets • Geographic • Pangaea: site, harvest • Atmospheric • NCAR: site, harvest • Census • Counting California: site, harvest
Primary source • Manuscripts • MADID: site, harvest • Papyri and ostracon • Giessen: site, harvest • Also repositories containing records detailing physical artifacts, specimens
How to use these records? • Put in the OPAC • Add to electronic journal lists • Create a brand-new database of materials accessible via SRU or OpenURL for a federated engine
Google • This stuff might be in Google, but if scholarly why not aggressively collect and provide access to it here? • IMO: Getting resources like this into Google Scholar will happen…eventually