Download

1 / 46
460 likes | 570 Views
CONCEPT MODELING:. A Research Review. Đorđe Popović, Ognjen Šćekić, Veljko Milutinović. January – July 2006. Initial Assignment. January 2006 Initial assignment: Get acquainted with different ways of Concept Modeling, in general.

E N D
CONCEPT MODELING: A Research Review Đorđe Popović, Ognjen Šćekić,Veljko Milutinović January – July 2006.
Initial Assignment • January 2006Initial assignment:Get acquainted with different ways of Concept Modeling,in general. • More specifically, explore the possibilities offered by RDF and OWL. • One of the ideas: Use the 7 Ws - WHAT, WHO, WHEN, WHERE, WHY, WHICH, (W)HOW.
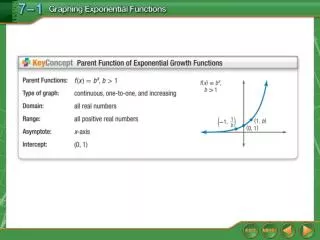
What is concept modeling? • A way of modeling reality: • Identifying concepts • Identifying relations among concepts • Organizing the concepts in a knowledge-base, allowing an "intelligent" way to search and process this data. • Why do we need concept modeling?To make electronic resources not only machine-processable, but also machine-understandable!
Challenges • How to create a model that has a uniform structure, and is powerful enough to capture the essence of any concept? • How should these models be linked into an efficient structure? • How can we bridge the gap between natural languageand a machine-processable model?
Why start with patents? • Described by a very formal, structured language – claims. • Each patent is a novel concept. • Definition of one patent is usually based on another one.
Structure of a Patent Document General info about the patent Description References to related patents Claims – primary target for What Abstract of the patent
Conceptual Indexing • What is conceptual indexing? “New technique for organizing information to support subsequent access that can dramatically improve your ability to find the information you need,with less hassle and with better results.” William A. Woods • Conceptual indexing combines techniques of: • Knowledge representation • Natural language processing • Classical techniques for indexing words and phrases • Bridges the gap between natural languageand a machine processable model.
Conceptual Indexing Conceptual indexing technology is a combination of: • Concept extractor Identifies phrases to be indexed. • Concept assimilator Analyzes a concept phrase to determine its place in the conceptual taxonomy. • Conceptual retrieval system Uses conceptual taxonomy to make connections between requested and indexed items. Figure 1 – Main components of a conceptual indexer
Hybrid Approach: Indices + RDF/OWL • Conceptual indices • RDF/OWL • Motivation:Use the advantages of one approach to eliminate the drawbacks of the other.
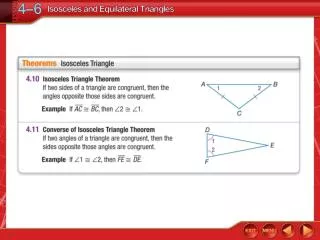
Why not use ontologies alone? • If we want to use an ontology we have 2 choices: • Use an existing, well-established ontology that might not suite our needs. • Create a new ontology which does suit our needs: • We can create several different ontologies,depending on how we want to capture the information. • Problems arise when we want to merge ontologies. • This approach works fine within a closed communitywith specific needs: • There already exists a well-defined basic ontology structure. • Community members have a good knowledge of how to model new conceptsin terms of the existing ones.
Why not use indices alone? • For example, let us take the simplest possible definition, for a bird: bird 1 – a creature with wings and feathers that lays eggs and can usually fly. • Our index might then contain the following associations:creature, wings, feathers, eggs, fly. • A conceptual index does not offer the possibility to state the fact that some birds do not fly! 1 - Word definition taken from Longman Dictionary of Contemporary English, 3rd edition, 1995.
Hybrid Approach • An index of associations represents a simple model,similar to what humans have on their mindwhen they first think of a bird. • Having enough associations, one can create a model with a considerable degree of accuracy. • RDF/OWL statements provide a means for expressing additional (but very important) information(e.g. there are birds that cannot fly!) • We believe this is good enough for most applications.
Hybrid Approach • It is important to keep track of how many times a term is mentioned,because it affects its descriptive power. • Example: U.S. Patent 6,989,179 – “Synthetic grass sport surfaces”, claims section: 1. synthetic grass [10] 2. playing surface [9] … • These terms represent the essence of what is being described!
Hybrid Approach • However, this is only because we know what “synthetic grass” and “playing surface” are! At some level, we need to have some intrinsic, built-in knowledge-base of basic concepts! • All the other concepts can then be described in terms of these basic concepts. • Solution: Conceptual indexers are equipped with a knowledge base of basic terms.
Patent Model – Conceptual Index • A patent’s Claims section is scanned and processedby a conceptual indexer. • The result is a descriptive index,associated with the patent (it size is approx. 1-5% of the full text). • This index can be seen as an ordered list of the patent’s WHAT associations(terms, phrases, sentence fragments). • An entry in the descriptive index contains a low-level concept,and the number of its occurrences.
Patent Model – RDF/OWL • For a different application, a different RDF/OWL model needs to be devised. • For describing patents this model could be used to capture explicitly stated information: • Patent number and other numbers ( WHICH) • Inventor, examiner, attorney, … ( WHO) • Date when the patent was filed ( WHEN) • Explicit references to similar patents ( WHICH) • etc… • Each W can have multiple sub-categories that are application-specific!
Patent Model – Creation Figure 2 – Creation of a patent model: Claims section is processed by the conceptual indexer to produce an index associated with the patent. Additional information about the concept is captured by RDF/OWL statements,into a predefined, application-specific structure.
Patent Model – Result Figure 3 – Patent model: WHAT associations are contained in a descriptive index. Other Ws are expressed through RDF/OWL statements.
Patent model – Big Picture • Descriptive indices are re-processed by the Conceptual indexer,to form the system index. • Each entry in the system index retains links to the descriptive indices it originates from,and vice-versa. • This structure allows us to: • Perform quick searches of the existing patents • Add/remove patents easily
Patent Model – Implicit Links • Descriptions of similar concepts (patents) usually make a frequent use of similar or even same terms. • By determining overlapping terms we createdynamic, implicit links among similar concepts. • The number of such implicit links can be used to express similarity among concepts. • The algorithm for determining the similarity needs to be tweaked empirically.
Advantages & Drawbacks • Advantages • Reduced complexity(a great reduction of direct links between concepts) • Fast search and retrieval(as the result of using indices) • Scalability • Drawbacks • Use of indices implies loss of precision
New Assignment • May 2006 Specific assignment: • Find ways of extracting prior art from previously filed patents. • Use the results to determine novel art in the descriptions of patents that have yet to be filed. • Generate new claims from newly found novel art,to be submitted for new patents.
Determining prior and novel art • This work is currently done by experts. • Requires great knowledge on the subject, and much time spent searching various databasesof existing patents. • Both time-consuming and money-consuming!
Determining prior and novel art • Existing tools use statistical, data-mining techniques. • Very efficient and fast algorithms available for extracting relevant keyphrases. • But limited capabilities of establishing any other than basic relationsamong concepts. Usually undefined relations. • Problem: How to determine more complex relations among concepts to create claims (sentences)? • Solution: Additional Natural Language Processing (NLP) techniques required!
Proposed solution – Stage 1 • Statistical analysis & seed extraction: • Process the text with a statistical analysis tool. (In our case KEA 3.0) • The output of such tools is an index of relevant words/phrases – keywords, associated with a score. • Ideally, by using a conceptual indexer the output would be a much more expressive “conceptual index”. • Composite keywords are turned into a single keyword and its descriptors. • Use empirical rules on word scores and composite phrasesto determine the most relevant keywords, and declare them to be the seeds for further analysis. Three stages: 1. Statistical analysis & seed extraction 2. Construction of Claims table 3. Creation of claims
Proposed solution – Stage 1 • Tools such as KEA require initial training and tweakingto achieve maximum performance. • We trained KEA on a set of 12 relevant Sun’s patents. • All the seeds extracted once are kept in a database,to be at disposal later when needed.
Proposed solution – Stage 2 • Construction of Claims table: • Text is processed once more to eliminate the sentences not containing any of the seeds. • Each seed is assigned an entry in the claims table, and its occurrences in the text marked with a unique marker. • The text is then analyzed sentence by sentence. • Each sentence is decomposed into its functional parts – subject fragments, object fragments, predicate fragments and different adverbial fragments. (NLP – the hardest part!)
[0] Grass(WHAT) • TYPE: synthetic • [1] Surface(s) (WHAT) • TYPE: [0], support, playing • are manufactured from s.g. panels [2] (predicate) • [2] Panel(s) (WHAT) • TYPE: [0] • are placed side-by-side (predicate) • to form continuous support surface[1] (WHY) • form continuous support surface (predicate) • are formed of grass sections[3] (predicate) • are square OR rectangular (predicate) • have different color tones (predicate) • [3]. Section(s) (WHAT) • TYPE: [0] • are cut from grass panels [from 2] (predicate) • are sewn OR glued OR attached together (predicate) • by a hook and loop attachment (HOW) • in a criss crossed way (HOW) • to create a checkered pattern (WHY) • create checkered pattern (predicate) • are assembled with ribbons OR fibers (predicate) • lying in different directions (HOW) • [4]. Ribbon(s) (WHAT) • TYPE: [2] • lie in different directions (predicate) • are fibrillated (predicate) • to remove the grain directions (WHY) • etc… Figure 5 – U.S. Patent 6,989,179 – “Synthetic grass sport surfaces”, Claims table (part of)
Proposed solution – Stage 3 • Creating claims once the table is complete is straightforward. • Here are some of the created claimsfrom the previously shown table: • A synthetic grass surface manufactured from synthetic grass panels. • A synthetic grass playing surface as defined in claim 1, wherein said synthetic grass panels are placed side by sideto form a continuous support surface. • A synthetic grass playing surface as defined in claim 2, wherein said synthetic grass panels are formed of synthetic grass sections. • Generated claims are compared against prior-art databaseto select only those claims describing potential novel art.
Problems Major obstacles that needed to be overcome were: • How to determine prior-art: • Concept classifier • Sentence Template Tool (NLP) • How to determine functional parts of a sentence: • Sentence Analyzer (NLP)
Figure 6 – Top-level scheme Patent description is processed by KEA and the Sentence template tool to extract relevant keywords (seeds). Seeds are compared against prior art contained in the database. NLP processing Claims table is created by analyzing sentences containing seeds. Generate new claims from the table.
Implementation of NLP parts • A subgroup of the research team began working on the NLP tools. • After extensive research we adopted the Stanford parseras the base tool for our work. (http://nlp.stanford.edu) • The parser analyzes single sentences.Its output is a tree structure showing types of words and sentence fragments. • It can also determine basic grammar relations. • Our plan: Use the first output to create the template tool, and both outputs to determine functional parts of a sentence.
Stanford parser – an example "One implementation of the snapshot copy process provides a two-table approach." (ROOT (S (NP (NP (CD One) (NN implementation)) (PP (IN of) (NP (DT the) (NN snapshot) (NN copy) (NN process)))) (VP (VBZ provides) (NP (DT a) (JJ two-table) (NN approach))) (. .))) num(implementation-2, One-1) nsubj(provides-8, implementation-2) det(process-7, the-4) nn(process-7, snapshot-5) nn(process-7, copy-6) prep_of(implementation-2, process-7) det(approach-11, a-9) amod(approach-11, two-10) dobj(provides-8, approach-11) Grammar relations can be used to determine main functional parts of sentences.
Sentence Template Tool • Motivation:In a single patent document authors often use the same sentence templates for describing various patent parts. • This tool allows the users to specify the sentence templates to find, and the parts they want extracted.
Sentence Template Tool • Example from the US patent No. 6,804,755 : FIG. 1 is a pictorial representation of a distributed data processing system in which the present invention may be implemented; FIG. 2 is a block diagram of a storage subsystem in accordance with a preferred embodiment of the present invention; . . .FIG. 10 is an exemplary block diagram of a multi-layer mapping table in accordance with a preferred embodiment of the present invention; FIG. 11 is an exemplary illustration of FlexRAID in accordance with the preferred embodiment of the present invention;. . . etc. • There are more than 20 sentences of the same structure in this patent description !
Sentence Template Tool • This sentence structure is typical for many patent descriptions, when the inventor is describing what the pictures represent. • Picture description sentences may contain important novel concepts. • Novel patents from already filed patents can be treated as prior art for the analyses of future patents.
Sentence Template Tool • For example: "FIG. 10 is an exemplary block diagram of a multi-layer mapping table in accordance with a preferred embodiment of the present invention." • The query that would return the underlined sentence partmight look like this: ”Fig” * ”is” * <NounPhrase><Preposition><?:NounPhrase>*<.> • We developed a comprehensive query syntax for comparing parsed sentence trees, similar to the one shown here.
Advantages • Frequently used queries can be stored for later use. • If this tool is to be used primarily within a company, people working for the company can be given the guidelineson how to describe certain parts of the patent to facilitate and make more efficient the use of this tool. • The key advantage of this approach is that it is much more accurate than statistical tools, because it is controlled by the humans.
An Unfortunate Turn . . . • Unfortunately, the funding for the project was not approved • Our goal now is to use the accumulated knowledgein a somewhat different direction!
Future plans • Use the results returned by Google, refine them by applying the semantic analysisand give immediate answers to user queries! • Users should be able to use the query syntax to specify not merely the keywords, but also require the terms to appear in a specified context, or ask specific questions.
Future plans • This kind of analysis requires an enormous amount of CPU time, and should therefore be performed only for specific searches: • Patents • Legal acts and documents • Newspaper and other archives • Deep internet search • etc.
Future plans • Possible solution: Each document should contain an additional metadata section, which would contain the parsed data from the plain text contained in it. • That way, documents that change rarelyshould be processed only once. • Additional storage costs should be outweighedby the increased search performance.
Future plans • Our idea is still in the first stage of development. • Further research is needed to explore the quality and feasibility of the proposed solution. • However, we expect to produce some interesting results .
CONCEPT MODELING: A Research Review Đorđe PopovićOgnjen ŠćekićVeljko Milutinovićpopajce@ptt.yuogi@cg.yuvm@etf.bg.ac.yu Thank you !