Download
1 / 1
10 likes | 491 Views
GPU Cluster for Scientific Computing Zhe Fan, Feng Qiu, Arie Kaufman, Suzanne Yoakum-Stover Center for Visual Computing and Department of Computer Science, Stony Brook University http://www.cs.sunysb.edu/ ~ vislab/projects/gpgpu/GPU_Cluster/GPU_Cluster.html and Large-Scale Simulation

E N D
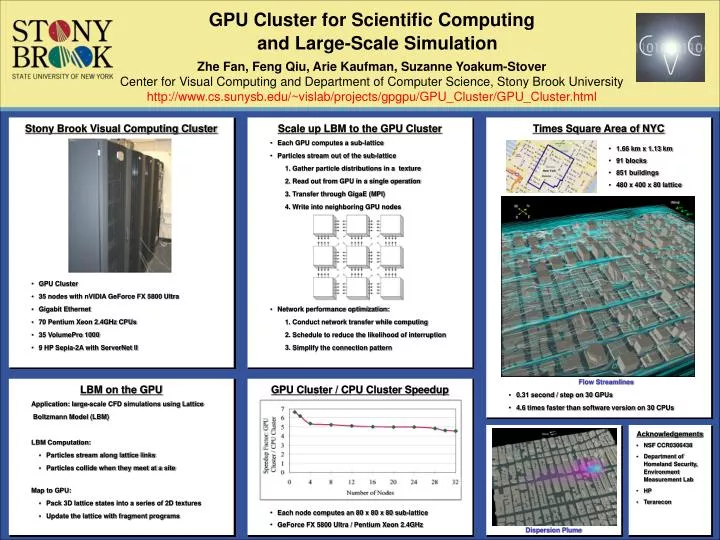
GPU Cluster for Scientific Computing Zhe Fan,Feng Qiu, Arie Kaufman,Suzanne Yoakum-Stover Center for Visual Computing and Department of Computer Science, Stony Brook University http://www.cs.sunysb.edu/~vislab/projects/gpgpu/GPU_Cluster/GPU_Cluster.html and Large-Scale Simulation • Stony Brook Visual Computing Cluster • GPU Cluster • 35 nodes with nVIDIA GeForce FX 5800 Ultra • Gigabit Ethernet • 70 Pentium Xeon 2.4GHz CPUs • 35 VolumePro 1000 • 9 HP Sepia-2A with ServerNet II • Scale up LBM to the GPU Cluster • Each GPU computes a sub-lattice • Particles stream out of the sub-lattice • Gather particle distributions in a texture • Read out from GPU in a single operation • Transfer through GigaE (MPI) • Write into neighboring GPU nodes • Network performance optimization: • Conduct network transfer while computing • Schedule to reduce the likelihood of interruption • Simplify the connection pattern • Times Square Area of NYC Flow Streamlines • 0.31 second / step on 30 GPUs • 4.6 times faster than software version on 30 CPUs • 1.66 km x 1.13 km • 91 blocks • 851 buildings • 480 x 400 x 80 lattice • LBM on the GPU Application: large-scale CFD simulations using Lattice Boltzmann Model (LBM) LBM Computation: • Particles stream along lattice links • Particles collide when they meet at a site Map to GPU: • Pack 3D lattice states into a series of 2D textures • Update the lattice with fragment programs • GPU Cluster / CPU Cluster Speedup • Each node computes an 80 x 80 x 80 sub-lattice • GeForce FX 5800 Ultra / Pentium Xeon 2.4GHz Dispersion Plume • Acknowledgements • NSF CCR0306438 • Department of Homeland Security, Environment Measurement Lab • HP • Terarecon






















