Download

1 / 45
540 likes | 1.01k Views
Matrix Differential Calculus. By Dr. Md. Nurul Haque Mollah, Professor, Dept. of Statistics, University of Rajshahi , Bangladesh. Outline. Differentiable Functions Classification of Functions and Variables for Derivatives Derivatives of Scalar Functions w. r. to Vector Variable

E N D
Matrix Differential Calculus By Dr. Md. Nurul Haque Mollah, Professor, Dept. of Statistics, University of Rajshahi, Bangladesh Dr. M. N. H. MOLLAH
Outline Differentiable Functions Classification of Functions and Variables for Derivatives Derivatives of Scalar Functions w. r. to Vector Variable Derivative of Scalar Functions w. r. to a Matrix Variable Derivatives of Vector Function w. r. to a Scalar Variable Derivatives of Vector Function w. r. to a Vector Variable Derivatives of Vector Function w. r. to a Matrix Variable Derivatives of Matrix Function w. r. to a Scalar Variable Derivatives of Matrix Function w. r. to a Vector Variable Derivatives of Matrix Function w. r. to a Matrix Variable Some Applications of Matrix Differential Calculus Dr. M. N. H. MOLLAH
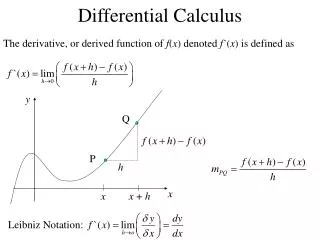
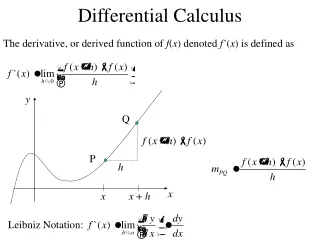
1. Differentiable Functions A real-valued function where is an open set is said to be continuously differentiable if the partial derivatives exist for each and are continuous functions of x over X. In this case we write over X. Generally, we write over Xif all partial derivatives of order p exist and are continuous as functions of xover X. If over Rn, we simply write If on X, the gradient of at a point is defined as Dr. M. N. H. MOLLAH
If over X, the Hessian of at x is defined to be the symmetric matrix having as the ijth element • If where then is represented by the column vector of its component functions as • If X is open, we can write on X if on X. Then the derivative of the vector function with respect to the vector variable x is defined by Dr. M. N. H. MOLLAH
If is real-valued functions of (x,y) where we write Dr. M. N. H. MOLLAH
If then • For and consider the function defined by Then if the chain rule of differentiation is stated as Dr. M. N. H. MOLLAH
2. Classification of Functions and Variables for Derivatives Let us consider scalar functions g, vector functions ƒ and matrix functions F. Each of these may depend on one real variable x, a vector of real variables x, or a matrix of real variables X. We thus obtain the classification of function and variables shown in the following Table. Dr. M. N. H. MOLLAH
Some Examples of Scalar, Vector and Matrix Functions Dr. M. N. H. MOLLAH
3. Derivatives of Scalar Functions w. r. to Vector Variable 3.1 Definition Consider a scalar valued function ‘g’ of ‘m’ variables g = g(x1, x2,…, xm) = g(x), where x = (x1, x2,…, xm)/. Assuming function g is differentiable, then its vector gradient with respect to x is the m-dimensional column vector of partial derivatives as follows Dr. M. N. H. MOLLAH
Consider the simple linear functional of xas where is a constant vector. Then the gradient of g is w. r. to x is given by Also we can write it as Because the gradient is constant (independent of x), the Hessian matrix of is zero. 3.2 Example 1 Dr. M. N. H. MOLLAH
Example 2 Consider the quadratic form where A=(aij) is a m x m square matrix. Then the gradient of g(x) w.r. to x is given by Dr. M. N. H. MOLLAH
Then the second- order gradient or Hessian matrix of g(x)=x/Ax w. r. to x becomes Dr. M. N. H. MOLLAH
3.3 Some useful rules for derivative of scalar functions w. r. to vectors For computing the gradients of products and quotients of functions, as well as of composite functions, the same rules apply as for ordinary functions of one variable. Thus The gradient of the composite function f(g(x)) can be generalized to any number of nested functions, giving the same chain rule of differentiation that is valid for functions if one variable. Dr. M. N. H. MOLLAH
3.3 Fundamental Rules for Matrix Differential Calculus Dr. M. N. H. MOLLAH
3.4 Some useful derivatives of scalar functions w. r. to a vector variable Dr. M. N. H. MOLLAH
Consider a scalar-valued function f of the elements of a matrix X=(xij) as f = f(X) = f(x11,x12,…xij,...,xmn) Assuming that function f is differentiable, then its matrix gradient with respect to X is the m×n matrix of partial derivatives as follows 4. Derivative of Scalar Functions w. r. to a Matrix Variable 4.1 Definition Dr. M. N. H. MOLLAH
4.2 Example 1 The trace of a matrix is a scalar function of the matrix elements. Let X=(xij)is an m x m square matrix whose trace is denoted by tr (X). Then Proof: The trace of X is defined by Taking the partial derivatives of tr (X) with respect to one of the elements, say xij, gives Dr. M. N. H. MOLLAH
Thus we get, Dr. M. N. H. MOLLAH
The determinant of a matrix is a scalar function of the matrix elements. Let X=(xij)is an m x m invertible square matrix whose determinant is denoted |X|. Then Proof: The inverse of a matrix X is obtained as where adj(X) is known as the adjoint matrix of X. It is defined by where Cij =(-1)i+jMij is the cofactor w. r. to xij and Mij is the minor w. r. to xij. 4.2 Example 2 Dr. M. N. H. MOLLAH
The minor Mij is obtained by first taking the (n-1) x (n-1) sub-matrix of X that remains when the i-th row and j-th column of X are removed, then computing the determinant of this sub-matrix. Thus the determinant |X| can be expressed in terms of the cofactors as follows Row i can be any row and the result is always the same. In the cofactors Cik none of the matrix elements of the i-th row appear, so the determinant is a linear function of these elements. Taking now a partial derivatives of |X| with respect to one of the elements, say xij, gives Dr. M. N. H. MOLLAH
Thus we get, This also implies that Dr. M. N. H. MOLLAH
4.3 Some useful derivatives of scalar functions w.r.to matrix Dr. M. N. H. MOLLAH
Derivatives of trace w.r.to matrix Dr. M. N. H. MOLLAH
Derivatives of determinants w.r.to matrix Dr. M. N. H. MOLLAH
5. Derivatives of Vector Function w. r. to a Scalar Variable 5.1 Definition Consider the vector valued function ‘f’ of a scalar variable x as f(x)=[f1(x) , f2(x) ,…, fn(x) ]/ Assuming function f is differentiable, then its scalar gradient with respect to x is the n-dimensional row vector of partial derivatives as follows Dr. M. N. H. MOLLAH
Let Then the gradient of f with respect to x is given by Also we can write it as 5.2 Example Dr. M. N. H. MOLLAH
6. Derivatives of Vector Function w. r. to a Vector Variable 6.1 Definition Consider the vector valued function ‘f’ of a vector variable x=(x1,x2, …, xm)/as f(x)= y =[y1= f1(x) , y2= f2(x) ,…, yn= fn(x) ]/ Assuming function f is differentiable, then its vector gradient with respect to x is the m×n matrix of partial derivatives as follows Dr. M. N. H. MOLLAH
Let Then the gradient of f(x) with respect to xis given by 6.2 Example Dr. M. N. H. MOLLAH
7. Derivatives of Vector Function w. r. to a Matrix Variable 7.1 Definition Consider the vector valued function ‘f’ of a matrix variable X=(xij)of order m×nas f(X)= y =[y1= f1(X) , y2= f2(X) ,…, yq= fq(X) ]/ Assuming that function f is differentiable, then its matrix gradient with respect to X is the mn×q matrix of partial derivatives as follows Dr. M. N. H. MOLLAH
Let Then the gradient of f(X) w. r. to matrix variable Xis given by 7.2 Example Dr. M. N. H. MOLLAH
8. Derivatives of Matrix Function w. r. to a Scalar Variable 8.1 Definition Consider the matrix valued function ‘F’ of a scalar variable xas F(x)= Y =[yij= fij(x)]m×n Assuming that function F is differentiable, then its scalar gradient with respect to the scalar x is the m×n order matrix of partial derivatives as follows Dr. M. N. H. MOLLAH
Let Then the gradient of F(x) w. r. to scalar variable x is given by 8.2 Example Dr. M. N. H. MOLLAH
9. Derivatives of Matrix Function w. r. to a Vector Variable 9.1 Definition Consider the matrix valued function ‘F’ of a vector variable x=(x1,x2,…,xm) as F(x)= Y =[yij= fij(x)]n×q Assuming that function F is differentiable, then its vector gradient with respect to the vector x is the m×nq order matrix of partial derivatives as follows Dr. M. N. H. MOLLAH
Let Then the gradient of F(x) w. r. to scalar variable x is given by 9.2 Example Dr. M. N. H. MOLLAH
Derivatives of Matrix Function w. r. to a Matrix Variable 10.1 Definition Consider the matrix valued function ‘F’ of a matrix variable X=(xij)m×pas F(X)= Y =[yij= fij(X)]n×q Assuming that function F is differentiable, then its matrix gradient with respect to the matrix X is the mp×nq order matrix of partial derivatives as follows Dr. M. N. H. MOLLAH
Let Then the gradient of F(X) w. r. to scalar variable X is given by 10.2 Example Dr. M. N. H. MOLLAH
Some important rules for matrix differentiation Dr. M. N. H. MOLLAH
Homework's Dr. M. N. H. MOLLAH
11. Some Applications of Matrix Differential Calculus • 1. Test of independence between functions • 2. Expansion of Tailor series • 3. Transformations of Multivariate Density functions • 4. Multiple integrations • 5. And so on. Dr. M. N. H. MOLLAH
Test of Independence A set of functions are said to be correlated ofeach other if their Jacobian is zero. That is Example: Show that the functions are not independent of one another. Show that Proof: So the functions are not independent. Dr. M. N. H. MOLLAH
In deriving some of the gradient type learning algorithms, we have to resort to Taylor series expansion of a function g(x) of a scalar variable x, (3.19) We can do a similar expansion for a function g(x)=g(x1, x2,…, xm) of m variables. We have (3.20) Where the derivatives are evaluated at the point x. The second term is the inner product of the gradient vector with the vector x-x, and the third term is a quadratic form with the symmetric Hassian matrix (∂2g / ∂x2).The truncation error depends on the distance |x-x|; the distance has to be small, if g(x)is approximated using only the first and second-order terms. Taylor series expansions of multivariate functions Dr. M. N. H. MOLLAH
The same expansion can be made for a scalar function of a matrix variable. The second order term already becomes complicated because the second order gradient is a four-dimension tensor. But we can easily extend the first order term in (3.20), the inner product of the gradient with the vector x-x to the matrix case. Remember that the vector inner product is define as For the matrix case, this must become the sum . Taylor series expansions of multivariate functions Dr. M. N. H. MOLLAH
This is the sum of the products of corresponding elements, just like in the vectorial inner product. This can be nicely presented in matrix form when we remember that for any two matrices, say A and B. With obvious notation. So, we have (3.21) for the first two terms in the Taylor series of a function g of a matrix variable. Taylor series expansions of multivariate functions Dr. M. N. H. MOLLAH