Download

1 / 17
190 likes | 479 Views
Superscalar Pipelines. 11/24/08. Scalar Pipelines. A single k stage pipeline capable of executing at most one instruction per clock cycle. All instructions, regardless of type, traverse through the same set of pipeline stages.

E N D
Superscalar Pipelines 11/24/08
Scalar Pipelines • A single k stage pipeline capable of executing at most one instruction per clock cycle. • All instructions, regardless of type, traverse through the same set of pipeline stages. • Instructions advance through the pipeline stages in lockstep fashion. • Except when stalled an instructions remains in a stage for only one clock cycle and then advances to the next stage. • We have concentrated on scalar pipelines with only a brief look at superscalar pipeline. • We will now look at superscalar pipelines in more depth. • This material is based on chapter 4 of “Modern Processor Design Fundamentals of Superscalar Processors” by Shen and Lipasti.
Superscalar Pipelines • The natural descendants of scalar pipelines. • They consist of: • Parallel pipelines that are able to initiate the processing of multiple instructions in every machine cycle. • Diversified pipelines which consist of execution stage with different types of functional units. • They may be implemented as dynamic pipelines which change the execution order of execution of instructions without the reordering of instructions by the compiler. • Parallel, diversified, and dynamic pipeline will be discussed separately.
Parallel Pipelines • Degree of parallelism of a machine can be measured by the maximum number of instructions that can be concurrently in progress at any one time. • A k-stage pipeline can have k instructions concurrently resident in the machine. • The potential speedup is k. • Same as using k non-pipelined processors. • The pipeline requires much less hardware.
Scalar Pipeline Multiprocessor Superscalar Pipeline Temporal and Spatial Parallelism
For a width of s, the maximum speedup is sk. In this example, k = 6, s = 3. s is the number of parallel pipelines. k is the number of stages in each pipeline.
Parallel Pipeline Hardware • Considerably more complex than scalar pipeline. • Logic complexity of pipeline increases by s. • Interstage interconnections can increase by s2. If for example, an s x s crossbar switch is used to connect all s instruction buffers (IRs) from one stage to all s instruction buffers of the next stage. • The number of read and write ports on the GPR must be increased by a factor of s. • Additional I-cache and D-cache access ports must be provided.
The Pentium implemented two 486 pipelines, making it a superscalar processor. IF and D1 are double width. The last three stages split off to separate pipelines. There are some limitations on simultaneous operations that can be accommodated by the two branches. i.e. Both can not access the same line of the D-cache at the same time.
Diversified Pipelines • Hardware required to support different instructions types can vary significantly (Particularly in a CISC). • Scalar pipeline requires all diverse requirements be unified into a single pipeline resulting in inefficiencies. • Each instruction type has different requirements in the execution stages. • In parallel pipelines instead of using s identical pipes in an s-wide pipeline diversified pipes can be employed for different instruction types.
In this figure four execution pipes or functional units of different pipe depths are implemented. The RD stage dispatches instructions to a pipe based on the instruction type.
Advantages of diversified Execution Pipes • Each pipe can be customized for a particular instruction type. • Efficient hardware design. • Each instruction type incurs only the necessary latency and makes use of all stages of an execution pipe. • If all inter-instruction dependencies between different instruction types are resolved prior to dispatching then, then once the instructions are issued into the individual execution pipes, no further stalling can occur due to instructions in other pipes.
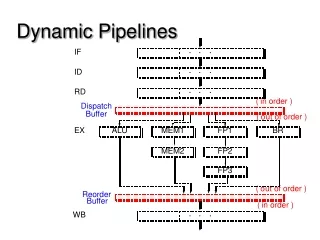
Dynamic Pipelines • Stalled instructions can be bypassed. • Eliminating the stall. • Causes instructions to be executed out of order. • After execution instructions are reordered into the proper completion sequence. • Much more complicated process than scalar pipelines.
Dynamic Pipelines • In any pipeline buffers (registers) are required between stages. • In the rigid scalar pipelines a single entry buffer is placed between each stage as shown in Figure 4.8 a. • Except when stalled, a new instruction enters the buffer on each clock. • All instructions enter and leave each buffer in the same order as the original code. • In a parallel pipeline multientry buffers are placed between each stage as shown in Figure 4.8 b. • If all instruction are required to advanced simultaneously a stall of one instruction stalls the entire buffer. • Dynamic pipelines help eliminate unnecessary stalling.
Buffers are required between pipeline stages. In (a) and (b) a stall at any stage stalls earlier stages. In (c), it is possible to push aside a stalled instruction. The buffers are much more complex in a dynamic pipeline.
Dispatch buffer is loaded with instructions and may dispatch the instructions out of order. The diverse functional units have different latencies. Instructions can finish execution out of order. To insure that exceptions can be handled according to the original program order, the instructions must be completed in the original program order. This makes possible precise exceptions