Download

1 / 1
10 likes | 116 Views
Evaluation of a Targeted-QSPR Based Pure Compound Property Prediction System. Mordechai Shacham , and Inga Paster, Dept. of Chem. Engng, Ben Gurion University of the Negev, Beer-Sheva, Israel Richard L. Rowley, Chem. Eng. Dept., Brigham Young University, Provo, UT

E N D
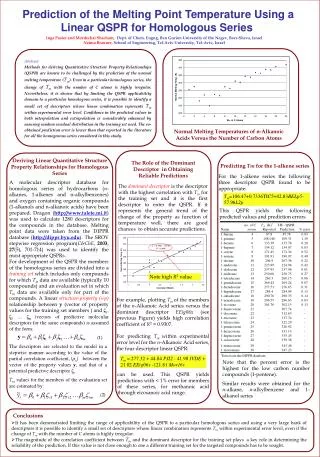
Evaluation of a Targeted-QSPR Based Pure Compound Property Prediction System Mordechai Shacham, and Inga Paster, Dept. of Chem. Engng, Ben Gurion University of the Negev, Beer-Sheva, Israel Richard L. Rowley, Chem. Eng. Dept., Brigham Young University, Provo, UT Neima Brauner and Gretah Tovarovski, School of Engineering, Tel-Aviv University, Tel-Aviv, Israel, Abstract The use of the DD – TQSPR (Dominant-Descriptor Targeted QSPR) method for the prediction of a wide variety of constant properties is considered. Prediction of a property (the target property) for a particular compound (the target compound) is carried out in two stages. The first stage involves the identification of a training set whose members are structurally related to the target compound(typically of around 10 compounds, for which target property data are available). The training set is selected from the target compound similarity group. The latter is identified by using a large database of molecular descriptors. The similarity between a potential predictive compound and the target compound is measured by the correlation coefficient between the vectors of their molecular descriptors. In the second stage of the DD TQSPR method, a Dominant Descriptor, which is collinear with the target property values for the members of the training set is identified and a linear relationship (the DD-TQSPR) between the DD and the target property values, is derived. Finally, the target compounds DD value is introduced into the linear equation in order to predict its target property. The use of the of the proposed technique is demonstrated by predicting 34 constant properties (available in the DIPPR database) for a target compound. Constant Properties Included in the DIPPR Database Property and Descriptor Databases A property and molecular descriptor database containing 1798 compounds for which 34 constant properties (source: DIPPR database http://dippr.byu.edu ) and 3224 descriptors (source: Dragon 5.5, http://www.talete.mi.it ) are available Most of the 3-D molecular structures were optimized in Gaussian 03 using B3LYP/6-311+G (3df, 2p), a density functional method with a large basis set. The rest were optimized using HF/6-31G*, a Hartree-Fock ab initio method with a medium-sized basis set. Similarity Group of n-hexyl mercaptan Prediction of Properties of n – hexyl mercaptan - Summary of Results for 34 Properties Immediate neighbors of the target in the homologous series Prediction of the NBT of n-hexyl mercaptan The ESpm01r is a 2D descriptor belonging to the "edje adjacency indices" group whose definition is: "Spectral moment 01 from edje adjacency matrix weighted by resonance integral". 1-hexanol is a leverage point and an outlier Prediction error for the target = 0.55% Attainable accuracy measures (independent of the target comp. property value) 1. DIPPR uncertainty values for the properties of the training set members ; 2. Average (Uavg) and maximal (Umax) DIPPR uncertainty values 3. Training Set Average Error (TSAE) = 0.51% Oxygen atom instead of sulfur Range of the number of the carbon atoms Improved Training Set. Obtained by using only stable (non-3D descriptors. No oxygen atom containing compounds - Property value (from DIPPR) p – No. of comps.in training set ζ - Descriptor Comments: 1. n-hexanol outlier; 2. Different odd even populations; 3. No data for target Conclusions • The prediction accuracy can be enhanced by refinement of the training set and not by increasing the number of the descriptors in the TQSPR. • Further research is required for deriving training set refinement algorithms for various properties and various groups of compounds. • The DD-TQSPR method was able to predict all 34 properties of the target compound within the experimental error level • The appropriate training set (similarity group) is dependent on the target property. • The TSAE (Training Set Average Error) has proven to be a good indicator for the appropriateness of the training set and the prediction accuracy. This criterion is independent of the target-compound properties. .