Download
1 / 31
330 likes | 526 Views
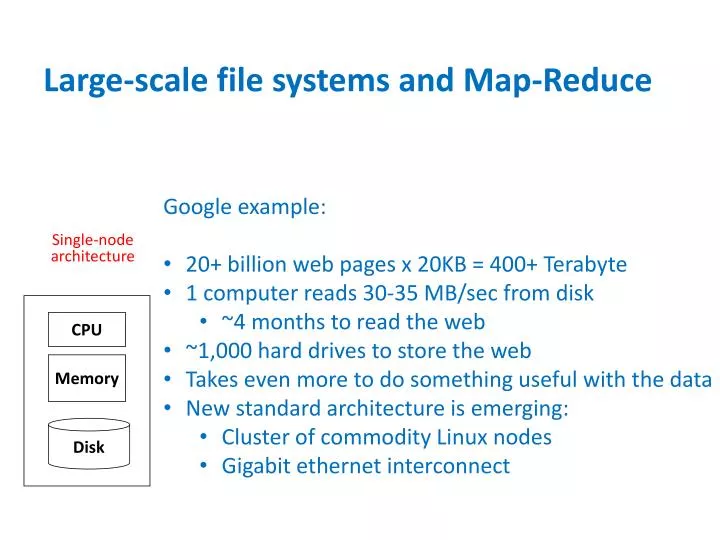
Large-scale file systems and Map-Reduce. Google example: 20+ billion web pages x 20KB = 400+ Terabyte 1 computer reads 30-35 MB/sec from disk ~4 months to read the web ~1,000 hard drives to store the web Takes even more to do something useful with the data

E N D
Large-scale file systems and Map-Reduce • Google example: • 20+ billion web pages x 20KB = 400+ Terabyte • 1 computer reads 30-35 MB/sec from disk • ~4 months to read the web • ~1,000 hard drives to store the web • Takes even more to do something useful with the data • New standard architecture is emerging: • Cluster of commodity Linux nodes • Gigabit ethernet interconnect CPU Single-node architecture Memory Disk
Distributed File Systems • Files are very large, read/append. • They are divided into chunks. • Typically 64MB to a chunk. • Chunks are replicated at several compute-nodes. • A master (possibly replicated) keeps track of all locations of all chunks.
Commodity clusters: compute nodes • Organized into racks. • Intra-rack connection typically gigabit speed. • Inter-rack connection faster by a small factor. • Recall that chunks are replicated Some implementations: • GFS (Google File System – proprietary). In Aug 2006 Google had ~450,000 machines • HDFS (Hadoop Distributed File System – open source). • CloudStore (Kosmix File System, open source).
File Chunks Replication Racks of Compute Nodes
Replication 3-way replication of files, with copies on different racks.
Map-Reduce • You write two functions, Map and Reduce. • They each have a special form to be explained. • System (e.g., Hadoop) creates a large number of tasks for each function. • Work is divided among tasks in a precise way.
Map-Reduce Algorithms • Map tasks convert inputs to key-value pairs. • “keys” are not necessarily unique. • Outputs of Map tasks are sorted by key, and each key is assigned to one Reduce task. • Reduce tasks combine values associated with a key.
Simple map-reduce example: Word Count • We have a large file of words, one word to a line • Count the number of times each distinct word appears in the file • Sample application: analyze web server logs to find popular URLs • Different scenarios: • Case 1: Entire file fits in main memory • Case 2: File too large for main mem, but all <word, count> pairs fit in main mem • Case 3: File on disk, too many distinct words to fit in memory
Word Count • Map task: For each line, e.g. CAT output (CAT,1) • Total output: (w1,1), (w1,1), …., (w1,1) • (w2,1), (w2,1), …., (w2,1) • …… • Hash each (w,1) to bucket h(w) in [0,r-1] • in local intermediate file. • r is the number of reducers • Master: Group by key: (w1,[1,1,…,1]), (w2,[1,1,…,1]), • ……… • Push group (w,[1,1,..,1]) to reducer h(w) • Reduce task: Read : (wi,[1,1,…,1]), (wi,[1,1,…,1]),… • (wj,[1,1,…,1]), (wj,[1,1,…,1]), … • …….. • Aggregate each (w,[1,1,…,1]) into (w,sum) • Output: : (wi,sumi), (wj,sumj), …. • into common output file • Since addition is commutative and associative • the map task could have sent : (w1,sum1), (w2,sum2), … • Reduce task would receive: (wi,sumi,1), (wi,sumi,2), … • (wj,sumj,1), (wj,sumj,2), … • and output (wi,sumi), (wj,sumj), ….
Partition Function • Inputs to map tasks are created by contiguous splits of input file • For reduce, we need to ensure that records with the same intermediate key end up at the same worker • System uses a default partition function e.g., hash(key) mod R • Sometimes useful to override • E.g., hash(hostname(URL)) mod R ensures URLs from a host end up in the same output file
Coordination • Master data structures • Task status: (idle, in-progress, completed) • Idle tasks get scheduled as workers become available • When a map task completes, it sends the master the location and sizes of its R intermediate files, one for each reducer • Master pushes this info to reducers • Master pings workers periodically to detect failures
Data flow • Input, final output are stored on a distributed file system • Scheduler tries to schedule map tasks “close” to physical storage location of input data • Intermediate results are stored on local FS of map and reduce workers • Output is often input to another map-reduce task • Master data structures • Task status: (idle, in-progress, completed) • Idle tasks get scheduled as workers become available • When a map task completes, it sends the master the location and sizes of its R intermediate files, one for each reducer • Master pushes this info to reducers • Master pings workers periodically to detect failures
Failures • Map worker failure • Map tasks completed or in-progress at worker are reset to idle (result sits locally at worker) • Reduce workers are notified when task is rescheduled on another worker • Reduce worker failure • Only in-progress tasks are reset to idle • Master failure • Map-reduce task is aborted and client is notified
How many Map and Reduce jobs? • M map tasks, R reduce tasks • Rule of thumb: • Make M and R much larger than the number of nodes in cluster • One DFS chunk per map is common • Improves dynamic load balancing and speeds recovery from worker failure • Usually R is smaller than M, because output is spread across R files
If vector doesn’t fit in main memory Divide matrix and vector into stripes: Each maptask gets a chunk of stripe iof the matrix and the entire stripe iof the vector and produces pairs Reduce task igets all pairs and produces pairs
Example: MAPPERS: REDUCERS:
Relational operators with map-reduce Selection Map task: If C(t) is true output pair (t,t) Reduce task: With input (t,t) output t Selection is not really suitable for map-reduce, everything could have been done in the map task
Relational operators with map-reduce Projection Map task: Let t’ be the projection of t. Output pair (t’,t’) Reduce task: With input (t’,[t’,t’,…,t’] ) output t’ Here the duplicate elimination is done by the reduce task
Relational operators with map-reduce • Union RS • Map task: for each tuple t of the chunk of R or S output (t, t) • Reduce task: input is (t,[t]) or (t,[t, t]). Output t • Intersection R S • Map task: for each tuple t of the chunk output (t,t) • Reduce task: if input is (t,[t,t]), output t • if input is (t,[t]) , output nothing • Difference R–S • Map task: for each tuple t of R output (t,R) • for each tuple t of S output (t,S) • Reduce task: if input is (t,[R]), output t • if input is (t,[R,S]) , output nothing
Joining by Map-Reduce • Suppose we want to compute • R(A,B) JOIN S(B,C), using k Reduce tasks. • I.e., find tuples with matching B-values. • R and S are each stored in a chunked file. • Use a hash function h from B-values to k buckets. • Bucket = Reduce task. • The Map tasks take chunks from R and S, and send: • Tuple R(a,b) to Reduce task h(b). • Key = b value = R(a,b). • Tuple S(b,c) to Reduce task h(b). • Key = b; value = S(b,c).
Map tasks send R(a,b) if h(b) = i All (a,b,c) such that h(b) = i, and (a,b) is in R, and (b,c) is in S. Map tasks send S(b,c) if h(b) = i Reduce task i • Key point: If R(a,b) joins with S(b,c), then both tuples are sent to Reduce task h(b). • Thus, their join (a,b,c) will be produced there and shipped to the output file.
Mapping tuples in joins Mapper for R(1,2) R(1,2) (2, (R,1)) Reducer for B = 2 (2, [(R,1), (R,4), (S,3)]) Mapper for R(4,2) R(4,2) (2, (R,4)) Mapper for S(2,3) S(2,3) (2, (S,3)) Reducer for B = 5 (5, [(S,6)]) Mapper for S(5,6) S(5,6) (5, (S,6))
Output of the Reducers Reducer for B = 2 (2, [(R,1), (R,4), (S,3)]) (1,2,3), (4,2,3) Reducer for B = 5 (5, [(S,6)])
Relational operators with map-reduce Grouping and aggregation: A,agg(B)(R(A,B,C)) Map task: for each tuple (a,b,c)output (a,b) Reduce task: if input is (a,[b1, b2, …,bn]), output (a,agg(b1, b2, …,bn)) for example (a, b1+b2+ …+bn)
Relational operators with map-reduce Three-Way Join • We shall consider a simple join of three relations, the natural join R(A,B) ⋈ S(B,C) ⋈ T(C,D). • One way: cascade of two 2-way joins, each implemented by map-reduce. • Fine, unless the 2-way joins produce large intermediate relations.
Another 3-Way Join • Reduce processes use hash values of entire S(B,C) tuples as key. • Choose a hash function h that maps B- and C-values to k buckets. • There are k2 Reduce processes, one for each (B-bucket, C-bucket) pair.
Job of the Reducers • Each reducer gets, for certain B-values b and C-values c : • All tuples from R with B = b, • All tuples from T with C = c, and • The tuple S(b,c) if it exists. • Thus it can create every tuple of the form (a, b, c, d) in the join.
Keys Values Mapping for 3-Way Join Aside: even normal map-reduce allows inputs to map to several key-value pairs. • We map each tuple S(b,c) to ((h(b), h(c)), (S, b, c)). • We map each R(a,b) tuple to ((h(b), y), (R, a, b)) for all y = 1, 2,…,k. • We map each T(c,d) tuple to ((x, h(c)), (T, c, d)) for all x = 1, 2,…,k.
T(c,d), where h(c)=3 S(b,c) where h(b)=1; h(c)=2 R(a,b), where h(b)=2 Assigning Tuples to Reducers h(c) = 0 1 2 3 h(b) = 0 1 2 3
DB = Mapper Mapper S(1,2) R(1,1) (1,1,(R,1)) (1,2,(R,1)) (1,2,(S,1,2)) ..etc R(1,1) S(1,1) T(1,1) R(2,1) S(1,1) T(1,1) R(2,1) S(1,1) T(1,2) R(1,1) S(1,1) T(1,2)






















