Download
1 / 14
140 likes | 248 Views
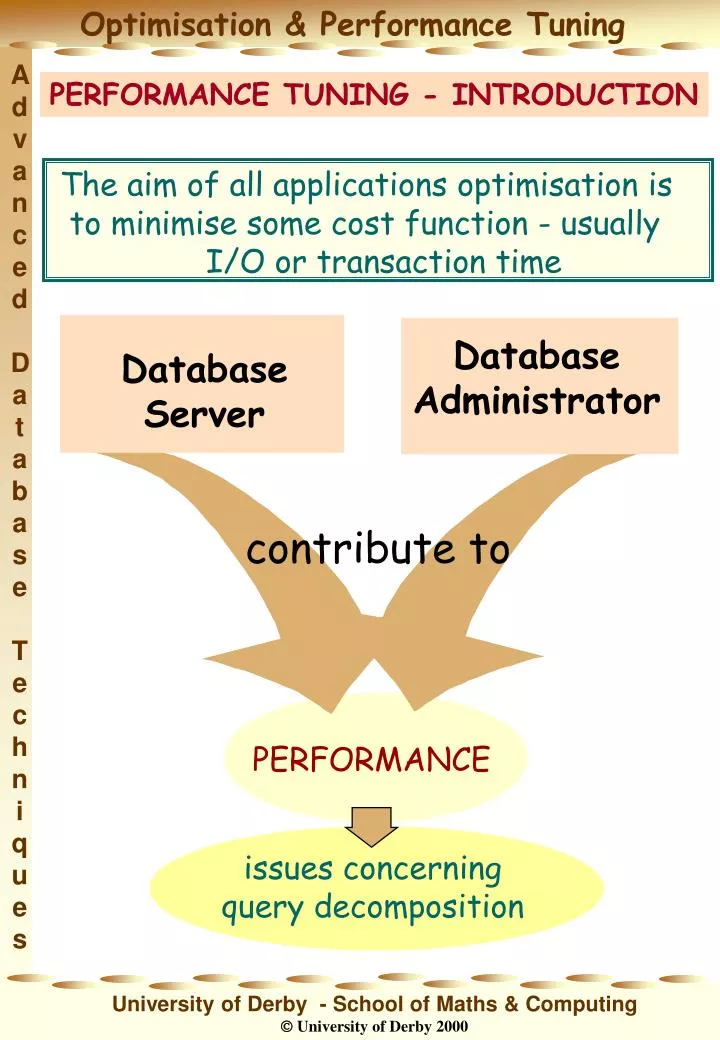
The aim of all applications optimisation is to minimise some cost function - usually I/O or transaction time. Database Server. PERFORMANCE TUNING - INTRODUCTION. Database Administrator. contribute to. PERFORMANCE. issues concerning query decomposition. database front-end.

E N D
The aim of all applications optimisation is to minimise some cost function - usually I/O or transaction time Database Server PERFORMANCE TUNING - INTRODUCTION Database Administrator contribute to PERFORMANCE issues concerning query decomposition
database front-end SERVER PROCEDURE FOR SATISFYING QUERY SQL Query Scan, Validate & Parse Query Precompiled Queries Query Modifier (Permits, Views, Integrities) Query Optimiser Query Execution Data Manipulation Facility Low-Level Data Requests
Relation Descriptions Incoming Query Column Descriptions Secondary Indices OPTIMISER Statistics Query Execution Plan Histograms THE QUERY OPTIMISER
Full Sort Merge Join Strategy Join Sort Sort Possible QEP for Joining Two Tables Join Sort Sort selection of tuples Proj-Rest Proj-Rest Base Table Base Table EXAMPLE JOINS 2 Tables - one of 100 rows - one of 10.000 rows (of which only 50 rows are to be selected)
Query Execution Plan Created to access the required data given the SQL statement at minimum cost Cost function is a combination of I/O’s required, CPU cycles consumed, together with memory and sort-merge requirements QEP is defined and control is passed to the runtime supervisor - the data manager then invokes the buffer manager - which calls on the services of the lowest level operating system - deciding how to share resources amongst multiple users
Implementation of the QEP - Indexing storage structure 5 different types of data organisation to be examined:- HEAPS INVERTED LIST ISAM (Indexed Sequential Access Method) B-tree (Binary Tree) Hashed
HEAPS Unordered set of rows New data added to end of file No direct access to individual row Adding data very efficient - no need to re-order pages or indices Seems crude - why use it? -good for applications requiring large volumes of data entry on-line followed by over-night batch reporting - no ad hoc queries
Inverted-Lists For every instance of the key value - store the RID of the records matching that value Example Table STREET_LIGHTS light_number,road_number,sector,road_name, control_type, wattage,etc. Inverted Index on ‘road-name’ Allestree Close RID1,RID4,RID10,RID12,RID15 ….. Bentley Brook RID201,IRD202,RID250,RID251,RID254 …... Kedleston Road RID151,RID152,RID154,….. NB List is maintained in sorted order The index page is read into main storage, probably only one I/O needed. RIDs then used to locate data pages. Therefore, efficient data retrieval in query like:- SELECT*FROM STREET_LIGHTS WHERE road_name=‘Bently Brook’
<=M > M Brubaker Cary Eagleton Allen Baker Bottorff Arly ISAM (or VSAM for ABM DB2) Indexed Sequential Access Method is based on primary key only. Therefore, need to select a key which will serve most of the likely requests of the user. In practice a compound key is often used.Disadvantage - Static - overflow can rapidly increase . INDEX PAGES <N < J < E < >BP =BP DATA PAGES OVERFLOW PAGES
Brubaker Cary Eagleton Allen Baker Bottorff B-Tree Leaf pages contain RIDs to the individual records. Data is returned in sorted order to the data buffer manager. Dynamic index - more balanced index than ISAM. More widely used. > M <=M INDEX PAGES <N < <J E LEAF PAGES Allen Baker Bottorff Brubaker Cary Eagleton DATA PAGES
Hash In hashed files the key value is directly related one-to-one with a physical address by means of a mathematical formula. Address=f (key-value) Advantage no index need be used - no index I/O required -therefore fast access Disadvantage large amounts of storage space may remain unused Hash index may be a possible choice for an evenly distributed key value table.
Data Storage Structures Data compressed is stored on disk in pages. A page is a unit of physical I/O typically containing many logical records each of which maps to a row in a database table. Each record is identified uniquely by a RID. RID for a record ‘x’ 20 4 page no offset to the location of a record pointer ‘P’ 20 record ‘x’ P free space
BEFORE AFTER 1 2 2 1 4 3 4 5 6 5 6 7 7 8 9 8 10 9 10 12 11 12 13 14 13 15 14 16 15 17 16 17 18 18 19 19 20 21 20 21 2% free space 5% free space Sort by primary key Unload Reload Database Re-organisation Utility Before and after of a single data page
Parallel Processing Parallel processing has been described as : “The key to high performance transaction and database processing” Use the paper on ‘Open Issues in Parallel Query Optimisation’ as a discussion document to test whether: “Parallel Processing offers the possibility of vastly improved performance where the database is very large or can be conveniently partitioned across different disks to reduce the overheads of communication.” Look at the topics: Share-Nothing and Share-memory architectures. Load-balancing, disk access problems, communications overheads. Application applicability - especially in respect of Object-oriented databases.