Download

1 / 30
300 likes | 427 Views
SST - Sequence Search Tree. weitere Form der Ähnlichkeitssuche. Franziska Brosy Seminar - Fortgeschrittene algorithmische Bioinformatik. Themenübersicht I. weitere Form der Ähnlichkeitssuche Idee von SST Grundlagen L1–Abstand k-means Clustering

E N D
SST - Sequence Search Tree weitere Form der Ähnlichkeitssuche Franziska Brosy Seminar - Fortgeschrittene algorithmische Bioinformatik
Themenübersicht I • weitere Form der Ähnlichkeitssuche • Idee von SST • Grundlagen • L1–Abstand • k-means Clustering • TSVQ – Tree-Structured Vector Quantization SST – Sequence Search Tree
ThemenübersichtII • SST–Algorithmus • Komplexitätsziel • Konstruktion des Indexbaumes • Suchphase • Testergebnis, Performanz • Fazit SST – Sequence Search Tree
Ähnlichkeitssuche • Ähnlichkeit 2er Strings per Scoringfunktion • Näherung: Welche Sequenzen haben wahrscheinlich einen hohen Ähnlichkeitsscore? • BLAST & Co. heuristische Algorithmen zum lokalen Alignment • BLAT schnell bei sehr ähnlichen Sequenzen • Wie gut ist das Ergebnis? • Charakterisierung durch Precision, Recall • Schwellwerte zum Steuern des Precision-Recall- Verhältnisses SST – Sequence Search Tree
weitere Form der Ähnlichkeitssuche • aber SST = nur Suche, kein Alignment • neu: statt Seeds, Seedverlängerung jetzt Bilden von Sequenzclustern, Erstellen tree-structured Index, Finden ähnliche Sequenzen in einem Cluster • Verwendung: large-scale sequencing, Filtermethode (True Negatives) SST – Sequence Search Tree
1. weitere Form der Ähnlichkeitssuche • 2. Idee von SST • 3. Grundlagen • L1–Abstand, k-means Clustering, TSVQ • 4. SST–Algorithmus • Komplexitätsziel, Baumkonstruktion, Suchphase • 5. Testergebnis, Performanz • 6. Fazit
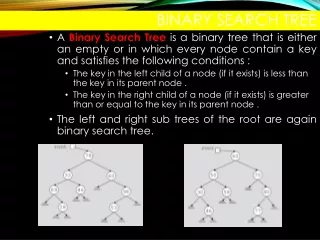
SST – die Idee • SST-Algorithmus durchsucht eine Datenbank (DNA-Sequenzen) nach near-exact Matches • Datenbank, Anfrage in Fenster fester Länge W • Fenster als 4k-dimensionale Vektoren • tree-structured Index über alle Fenster • suchen mit Hilfe des ts Index nach den nächsten Nachbarn der Anfragefenster SST – Sequence Search Tree
1. weitere Form der Ähnlichkeitssuche • 2. Idee von SST • 3. Grundlagen • L1–Abstand, k-means Clustering, TSVQ • 4. SST–Algorithmus • Komplexitätsziel, Baumkonstruktion, Suchphase • 5. Testergebnis, Performanz • 6. Fazit
L1-Abstand (Manhattan-Abstand) • Maß für die Ähnlichkeit zwischen zwei Objekten • hier: Objekte sind Vektoren V (später) SST – Sequence Search Tree
k-means Clustering • hard clustering Algorithmus • Cluster-Bildung anhand des Zentrums der Mehrheit seiner Komponenten (Vektoren) • zufällig gewählte Zentren, dann redefinieren • Initalcluster, Iterationen • 1) Vektor Cluster, 2) Neuberechnung der Centroide • Zentrum = Centroid = mean SST – Sequence Search Tree
k-means Cluster mit L1-Abstand • Zuordnung Vektoren zu Cluster: L1-Abstand • untere Schranke für Editabstand! (Ukkonen) L1(S,Q) edit(S,Q) mit L1(S,Q) = d • ges.: Sequenz Sq, geg.: Anfragesequenz Q L1(Sq,Q) > d edit(Sq,Q) > d Sq verwerfen • Suche im Editabstand-Raum auf Suche im L1-Abstand-Raum approximierbar SST – Sequence Search Tree
k-means Clustering am Beispiel SST – Sequence Search Tree
TSVQ I • Tree-Structured Vector Quantization • Algorithmus zum Erstellen des ts Index • sortiert (Sequenzen) topologisch, rekursiv hier: unter Verwendung k-means, L1-Abstand SST – Sequence Search Tree
TSVQ II • Art Nächste-Nachbarn-Suchalgorithmus • innere Knoten = Centroide • Kanten = Teilung in 2 Cluster • Blätter = NN zum Eingabevektor (Anfrage) • binärer Baum: binäre Tests an jedem Knoten • kann NN in finden, SST – Sequence Search Tree
1. weitere Form der Ähnlichkeitssuche • 2. Idee von SST • 3. Grundlagen • L1–Abstand, k-means Clustering, TSVQ • 4. SST–Algorithmus • Komplexitätsziel, Baumkonstruktion, Suchphase • 5. Testergebnis, Performanz • 6. Fazit
Komplexitätsziel • n – Größe der Datenbank • m – Länge der Anfragesequenz • AVG Konstruktion Index: • AVG Suche des Index: • k-means nicht immer • Baumtiefe nicht immer SST – Sequence Search Tree
Konstruktion Indexbaum • 3 Schritte, einmalig pro Datenbank (DB) • 1) DB-Partionierung mit Sliding Windows • 2) Abbilden der Fenster im Vektorraum • 3) Bilden tree-structured Index für DB-Fenster • anschließend: Suchphase SST – Sequence Search Tree
DB-Partionierung mit Sliding Windows • alle DB-Sequenzen in überlappende Fenster • feste Fensterlänge W • typische Werte 25 W 1000 • Überlappung durch Parameter • typische Werte 5 W/2 • Fensterposition Start: Ende: SST – Sequence Search Tree
DB-Partionierung am Beispiel Fensterlänge W = 6 Überlappungen = 2 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 j Start Ende 0 0 5 1 2 7 2 4 9 A A C C G G T T A C G T A C G T A A C C G G T T A C G T A C G T A A C C G G T T A C G T A C G T SST – Sequence Search Tree
pro Fenster/Sequenz ein Vektor mit: #Vorkommen jedes k-Tupels in der Sequenz zuerst Wahl Tupelgröße k (meist 2 k 10) DNA, 4 Elemente 4k Nukleotidentupel Vektordimensionen 4k Abbilden der Fenster im Vektorraum I SST – Sequence Search Tree
Abbilden der Fenster im Vektorraum II • Integerwert für alle k-Tupel SST – Sequence Search Tree
tree-structured Index für die DB-Fenster • jetzt nur noch: Finden nächste Nachbarn im Vektorraum • dazu: Konstruktion ts Index im Vektorraum • indem: rekursive binäre Partionierung • mittels: k-means Clustering, TSVQ • folglich: nächste Nachbarn als Set im Blatt • WENN: Baum balanciert, k-means O(n) • DANN: AVG Komplexität Baumkonstruktion O(n*log(n)) , n = Größe der DB SST – Sequence Search Tree
tree-structured Index für die DB-Fenster • jetzt nur noch: Finden nächste Nachbarn im Vektorraum • dazu: Konstruktion ts Index im Vektorraum • indem: rekursive binäre Partionierung • mittels: k-means Clustering, TSVQ • folglich: nächste Nachbarn als Set im Blatt • WENN: Baum balanciert, k-means O(n) • DANN: AVG Komplexität Baumkonstruktion O(n*log(n)) , n = Größe der DB SST – Sequence Search Tree
tree-structured Index für die DB-Fenster • jetzt nur noch: Finden nächste Nachbarn im Vektorraum • dazu: Konstruktion ts Index im Vektorraum • indem: rekursive binäre Partionierung • mittels: k-means Clustering, TSVQ • folglich: nächste Nachbarn als Set im Blatt • WENN: Baum balanciert, k-means O(n) • DANN: AVG Komplexität Baumkonstruktion O(n*log(n)) , n = Größe der DB SST – Sequence Search Tree
Suchphase • Anfrage in Fenster zerlegen, Vektoren berechnen • Suche über ts Index (Baum binär) • Beginn bei root • innere Knoten, root: je 2 Verzweigungen • Wahl: Zweig, dessen Centroid geringeren Abstand vom Anfragevektor hat • solange bis Blatt erreicht • Vektoren im Blatt = potentielles Ergebnis für die Anfrage SST – Sequence Search Tree
1. weitere Form der Ähnlichkeitssuche • 2. Idee von SST • 3. Grundlagen • L1–Abstand, k-means Clustering, TSVQ • 4. SST–Algorithmus • Komplexitätsziel, Baumkonstruktion, Suchphase • 5. Testergebnis, Performanz • 6. Fazit
Testergebnis • am Bsp.: Finden von Überlappungen bei Shotgun Assembling (1.5 MBasen) • nahezu 100%ige Spezifität • bei günstigen k, W, T (T - tolerierter Abstand (I,D,R)) keine Aussage über FN, Sensitivität?? SST – Sequence Search Tree
Performanz • Vergleich mit BLAST • am Bsp. mit 120 000 Sequenzen nach Statistik: • SST 9.3 bis 27 mal schneller als BLAST • verschieden Werte: je nach Anfragefenster, Überlappungen/Nichtüberlappungen • ohne Aussage über Konfiguration von BLAST • BLAST = Suche + Alignment, SST = nur Suche SST – Sequence Search Tree
1. weitere Form der Ähnlichkeitssuche • 2. Idee von SST • 3. Grundlagen • L1–Abstand, k-means Clustering, TSVQ • 4. SST–Algorithmus • Komplexitätsziel, Baumkonstruktion, Suchphase • 5. Testergebnis, Performanz • 6. Fazit
Fazit • SST findet recht viele nächste Nachbarn zu einer Anfragesequenz • gutes Herausfiltern von TN • Sequenzen nahe an Clustergrenze evtl. FN • FN ‘vermutlich‘ gering (Verwendung k-means), somit ‘geringe‘ Einbußen bei Sensitivität • schnelle Suche, bei günstiger Konfiguration • evtl. sogar in • kein Alignment SST – Sequence Search Tree