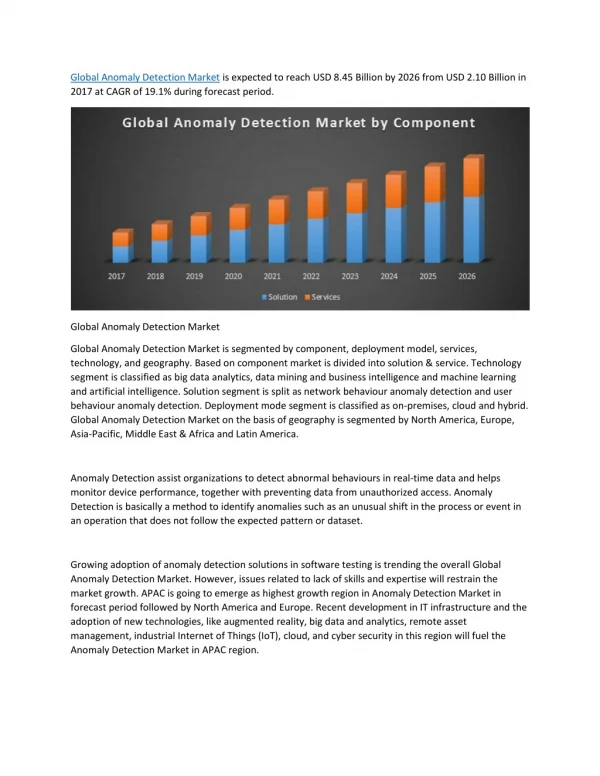
Download

1 / 32
320 likes | 339 Views
Develop machine learning approach to detect anomalies in large multivariate electronic systems, predict future performance, mitigate false alarms, and identify intermittent faults. Utilize one-class-classification for absence of negative data.

E N D
Anomaly Detection Through a Bayesian SVM Vasilis A. Sotiris AMSC 664 Final Presentation May 6th 2008 Advisor: Dr. Michael Pecht University of Maryland College Park, MD 20783
Objectives • Develop an algorithm to detect anomalies in electronic systems (large multivariate datasets) • Perform detection in the absence of negative class data – One – Class Classification • Predict future system performance • Develop application toolbox – CALCEsvm to implement a proof of concept on simulated and real data: • Simulated degradation • Lockheed Martin Data-set AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Motivation • With increasing functional complexity of on-board autonomous systems, there is an increasing demand for system level: • Health assessment, • Fault diagnostics • Failure prognostics • This is of special importance for analyzing intermittent failures, some of the most common failure modes in today’s electronics • There is a need for efficient and reliable prognostics for electronic systems using algorithms that can: • fuse sensor data, • discriminate false alarms from actual failures • correlate faults with relevant system events • and reduce redundant processing elements which are subject to common mode failures AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Algorithm Objectives • Develop a machine learning approach to: • detect anomalies in large multivariate systems • detect anomalies in the absence of reliable failure data • Mitigate false alarms and intermittent faults and failures • Predict future system performance x2 Distribution of fault/failure data Fault Space ? Distribution of training data x1 AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Data Setup • Data is collected at times Ti from a multivariate distribution of random variables x1i…xmi • x’s are the system covariates • Xi’s are independent random vectors • Class {-1,+1} • Class probability = p(class|X) estimate given X AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
[R] Sample Observation x xR xM [M] Data Decomposition (Models) • Extract features from the data by constructing lower dimensional models • X – training data Rnxm • Singular Value Decomposition (SVD) • With H project data onto [M] and [R] models • k: number of principal components (k=2) • xM: the projection of x onto the model space [M] • xR: projection of x onto the residual space [R] AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
F2 x2 x2 D(x) F1 F3 x1 x1 -1 +1 Two Class Support Vector Machines D(x) Solution Mapping F Feature Space Input Space Input Space • Given: nonlinearly separable labeled data xiwith labels yi {+1,-1} • Solve linear optimization problem to find w and b in the feature space • Form a nonlinear decision function my mapping back to the input space • The result is that we can obtain a decision boundary on the given training set and use it to classify new observations AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
x2 Negative Class M w D(x)=0 x1 Positive Class Two Class Support Vector Machines • Interested in a function that best separates two classes of data • The margin M=2/||w|| can be maximized by minimizing ||w|| • the learning problem is stated as: • subject to: • The classifier function D(x) is constructed with appropriate w and b (distance origin to D(x)) AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
min! Two Class Support Vector Machines • Lagrangian function: • Instead of minimizing LPw.r.t. to w and b, minimize LDw.r.t to α where H is the Hessian Matrix, Hi j = yi yj xiT xj a=[a1,…,an] and p is a unit vector KKT conditions AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Two Class Support Vector Machines • In the nonlinear case use kernel function F centered at each x • Form the same optimization problem where • Argument: the resulting function D(x) is the best classifier for the given training set x2 D(x)=-1 Distribution of fault/failure data D(x)=0 D(x)=+1 Support Vectors Distribution of training data x1 AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Bayesian Interpretation of D(x) • The classification y {-1.+1} for any x, is equivalent to asking p(Y=+1 | X=x) > ? < p(Y=-1 | X=x) • An optimal classifier yMAP maximizes the conditional probability: • Quadratic optimization problem D(x) • It can be shown that D(x) is the maximum a posteriori (MAP) solution to P(Y=y|X=x) P(class|data), and therefore the optimal classifier of the given two classes if if AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
xi x2 x1 One Class Training • In the absence of negative class data (fault or failure information), a one-class-classification approach is used • X=(X1, X2) ~ bivariate distribution • Likelihood of positive class L=p(X=xi|y=+1) • Class label y (-1,+1) • Use the margin of this likelihood to construct the negative class L X1 X2 AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
1 # samplesin R total # Samples volume (R) fR(x) = Nonparametric Likelihood Estimation • If the probability that any data point xi falls into the kth bin is r, then the probability of a set of data {x1,…,xm} falling into the kth bin is given by a binomial distribution: • Total sample size: n • Number of samples in kth bin: m • Region defined by bin: R • MLE of r • Density estimate AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
3 1 2 1 2 3 x Estimate likelihood: Gaussian kernel j • The volume of R: • For uniform kernel the number of data m in R: • Kernel function: f • Points xiwhich are close to the sample point x receive higher weight • Resulting density fj(x) is smooth • The bandwidth h is selected according to a nearest neighbor algorithm • Each bin R contains kn data AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
P( X11= x1,…,X1n= xn| y1,…yn= +1 ) t Negative Class [N] x1 x1n+2 x1n+1 Estimate of Negative Class • The negative class is estimated based on the likelihood of the positive class (training data) • A threshold t is used to estimate the likelihood ratio of positive to negative class probability for the given training data • A 1D cross-section of the density illustrates the idea of the threshold ratio: Positive Negative AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
D(x) as a Sufficient Statistic • D(x) can be used as a sufficient statistic to classify data point x • Argument: since D(x) is the optimal classifier, posterior class probabilities are related to data’s distance to D(x)=0 • These probabilities can be modeled by a logistic distribution, centered at D(x)=0 D(x) AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Posterior Class Probability • The positive posterior class probabilityis given by: • Use D(x) as the sufficient statistic for the classification of xi, by replacing aiby D(xi) • Simplify • Get MLE for parameters A and B logistic distribution where AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Joint Probability Model • Interested in P = P(Y|XM,XR), the joint probability of classification given two models: • XM: model space [M] • XR: residual space [R] • Assume XM, XR independent • After some algebra get the joint positive and negative posterior class probabilities P(+) and P(-): AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Case Studies • Simulated degradation • Lockheed Martin Dataset AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Case Study I –Simulated Degradation • Given: • Simulated correlated data • X1 = gamma, X2 = student t, X3 = beta • Degradation modeling • Period of healthy data • Three successive periods of increasingly larger changes in the mean for each parameter • Expecting a posterior classification probability to reflect these four periods accordingly • First with a probability close to 1 • For the three successive a decreasing trend x1 Observation AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Case Study I Results – Simulated Degradation • Results: a plot of the joint positive classification probability P1 P2 P4 P3 AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Case Study II – Lockheed Martin Data (Known Faulty Periods) • Given: Data set from Lockheed martin • Type of data: server data, unknown parameters • Multivariate, 22 parameters, 2741 observations • Healthy period (T): observations 0 - 800 • Fault periods: observations F1: 912 – 1040, F2: 1092 – 1106, F3: 1593 - 1651 • Training data constructed with sample from period T, with size n=140 • Goal: • Detect onset of known faulty periods without the knowledge of “unhealthy” system characteristics AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Case Study II - Results Period F1 Period F2 Period T 912 800 AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Comparison Metrics of Code Accuracy (LibSVM vs CALCEsvm) • An established and commercially used C++ SVM software (LibSVM) was used to test the accuracy of the code • LibSVM features used: two class SVM • does not include classification probabilities for one class SVM • Input to LibSVM: • Positive class: same training data • Negative class: estimated negative class data from CALCEsvm • Metrics: detection accuracy: • The count of correct classifications based on two categories: • Classification label y • Correct classification probability estimate AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Detection Accuracy LibSVM vs CALCEsvm (Case Study 1 – Degradation Simulation) • Description of test: • Period 1 should be captured with a probability estimate ranging from 80% to 100% positive class • Period 2 equivalently between 70% and 85% • Period 3 between 30% and 70% • Period 4 between 0 and 40% • Based on just the class index, the detection accuracy for both algorithms was almost identical • Based on ranges of probabilities LibSVM performs better in determining the early stages where the system is healthy, but performs worse is detecting degradation in comparison to CALCEsvm P1 P2 P3 P4 P1 P2 P3 P4 AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Detection Accuracy LibSVM vs CALCEsvm (Case Study 2 – Lockheed Data) • Description of test: • The acceptable probability estimate for a correct positive classification should lie between 80 and 100% • Similarly the acceptable probability estimate for a negative classification should not exceed 40% • Based on the class index, both LibSVM and CALCEsvm perfrom almost identically, with small improved performance for CALCEsvm • Based on acceptable probability estimates, • LibSVM: • does a poor job at identifying the healthy state between each successive faulty period • Has a much better performance at detecting the anomalies • CALCEsvm: • Seems to perform overall much better, and identifies correctly both base on index and acceptable probability ranges the faulty and healthy periods in the data AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Summary • For the given data, and on some additional data sets the CALCEsvm algorithm has accomplished the objective • Detected the time events for known anomalies • Identified trends of degradation • Comparison of its performance accuracy to LibSVM is at first hand good! AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Backups AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Dual Form of Lagrangian Function • Dual form of the Lagrangian function, for the optimization problem in LD space through KKT conditions: subject to: AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Karush-Kuhn-Tucker (KKT) Conditions • Optimal solution (w*, b*, α*) exists if and only if KKT conditions are satisfied. In other words, KKT conditions are necessary and sufficient to solve w, b and α in a convex problem AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Posterior Class Probability • Interested in finding the maximum likelihood estimates for parameters A and B • The classification probability of a set of test data X={x1,…,xk}, into c={1,0} is given by a product Bernoulli distribution • Where pi is the probability of classification when c=1 (y=+1) and 1-pi is the probability of classification when c=0 (refers to class y=-1) AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM
Posterior Class Probability • Maximize the likelihood of correct classification y for each xi (MLE): • Determine parameters AMLE and BMLE from maximum likelihood equation (above) • Use AMLE and BMLE to compute p(i)MLE in • Where piMLE is the • maximum likelihood estimator of the posterior class probability pi (due to the invariance property of the MLE) • best estimate for the classification probability of each xi • Currently implemented is: AMSC 664 Final Presentation - Anomaly Detection Through a Bayesian SVM