Download
1 / 2
20 likes | 135 Views
Project Title: A Merged Atmospheric Water Data Set from the A-Train Project team: Eric Fetzer ( Eric.J.Fetzer@jpl.nasa.gov ) and JPL colleagues. Project status: Year 1 & 2 complete – Delivered two data sets to CREW. Team co-authored ~20 peer-reviewed papers.

E N D
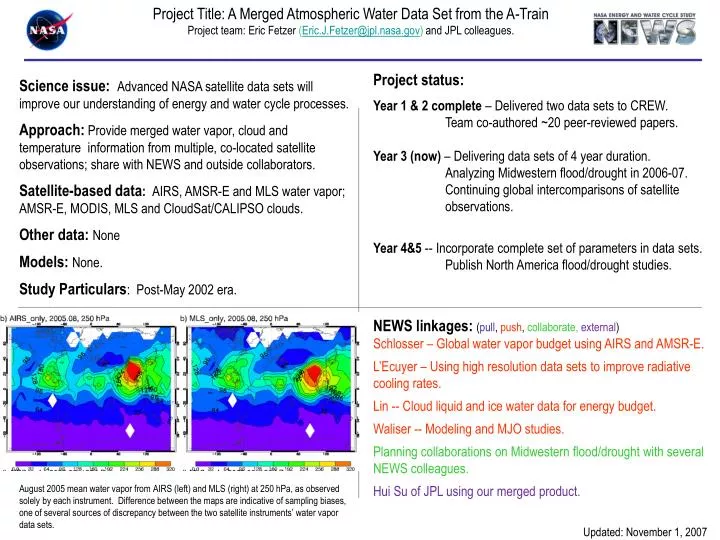
Project Title: A Merged Atmospheric Water Data Set from the A-Train Project team: Eric Fetzer (Eric.J.Fetzer@jpl.nasa.gov) and JPL colleagues. Project status: Year 1 & 2 complete – Delivered two data sets to CREW. Team co-authored ~20 peer-reviewed papers. Year 3 (now) – Delivering data sets of 4 year duration. Analyzing Midwestern flood/drought in 2006-07. Continuing global intercomparisons of satellite observations. Year 4&5 -- Incorporate complete set of parameters in data sets. Publish North America flood/drought studies. Science issue:Advanced NASA satellite data sets will improve our understanding of energy and water cycle processes. Approach: Provide merged water vapor, cloud and temperature information from multiple, co-located satellite observations; share with NEWS and outside collaborators. Satellite-based data: AIRS, AMSR-E and MLS water vapor; AMSR-E, MODIS, MLS and CloudSat/CALIPSO clouds. Other data: None Models: None. Study Particulars: Post-May 2002 era. NEWS linkages: (pull, push, collaborate, external) Schlosser – Global water vapor budget using AIRS and AMSR-E. L’Ecuyer – Using high resolution data sets to improve radiative cooling rates. Lin -- Cloud liquid and ice water data for energy budget. Waliser -- Modeling and MJO studies. Planning collaborations on Midwestern flood/drought with several NEWS colleagues. Hui Su of JPL using our merged product. August 2005 mean water vapor from AIRS (left) and MLS (right) at 250 hPa, as observed solely by each instrument. Difference between the maps are indicative of sampling biases, one of several sources of discrepancy between the two satellite instruments’ water vapor data sets. Updated: November 1, 2007
How important are error estimates? Modern satellite data sets are observationally unbiased, and their sampling biases can be well characterized. Example: the difference between these two figures is the worst-case disagreement between MLS and AIRS UTWV. Would effort be better spent getting models to agree?





















