Download

1 / 48
480 likes | 544 Views
Adverse Event Reporting at FDA, Data Base Evaluation and Signal Generation. Robert T. O’Neill, Ph.D. Director, Office of Biostatistics, CDER, FDA. Presented at the DIMACS Working Group Disease and Adverse Event Reporting, Surveillance, and Analysis

E N D
Adverse Event Reporting at FDA,Data Base Evaluation and Signal Generation Robert T. O’Neill, Ph.D. Director, Office of Biostatistics, CDER, FDA Presented at the DIMACS Working Group Disease and Adverse Event Reporting, Surveillance, and Analysis October 16, 17, 18, 2002; Piscataway, New Jersey
Outline of Talk • The ADR reporting regulations • The information collected on a report form • The data base, its structure and size • The uses of the data base over the years • Current signal generation approaches - the data mining application • Concluding remarks
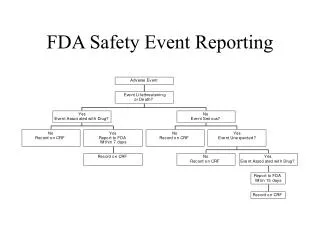
Overview • Adverse Event Reporting System (AERS) • Report Sources • Data Entry Process • AERS Electronic Submissions (Esub) • Production Program • E-sub Entry Process • MedDRA Coding
Adverse Event Reporting System (AERS) Database • Database Origin 1969 • SRS until 11/1/97 ; changed to AERS • 3.0 million reports in database • All SRS data migrated into AERS • Contains Drug and "Therapeutic" Biologic Reports • exception = vaccines VAERS 1-800-822-7967
Adverse Event Reporting SystemSource of Reports • Health Professionals, Consumers / Patients • Voluntary : Direct to FDA and/or to Manufacturer • Manufacturers: Regulations for Postmarketing Reporting
Current Guidance on Postmarketing Safety Reporting (Summary) • 1992 Reporting Guideline • 1997 Reporting Guidance: Clarification of What to Report • 1998 ANPR for e-sub • 2001 Draft Reporting Guidance (3/12/2001) • 2001 E-sub Reporting of Expedited and Periodic ICSRs (11/29/2001)
Despite limitations, it is our primary window on the real world • What happens in the “real” world very different from world of clinical trials • Different populations • Comorbidities • Coprescribing • Off-label use • Rare events
AERS AERS Functionality • Data Entry • MedDRA Coding • Routing • Safety Evaluation • Inbox • Searches • Reports • Interface with Third-Party Tools • AutoCode (MedDRA) • RetrievalWare (images)
AERS Esub ProgramHistory • Over 4 years • Pilot, then production. • PhRMA Electronic Regulatory Submission (ERS) Working Group • PhRMA eADR Task Force • E*Prompt Initiative • Regular meetings between FDA and Industry held to review status, address issues, share lessons learned
Adverse Event Reporting SystemProcessing MEDWATCH forms • Goal: Electronically Receive Expedited and Periodic ISRs • Docket 92S-0251 • As of 10/2000, able to receive electronic 15-day reports • Paper Reports • Scanned upon arrival • Data entered • Electronic and Paper Reports • Coded in MedDRA
Electronic Submission of Postmarketing ADR Reports • MedDRA coding 3500A • Narrative searched with Autocoder • MedDRA coding E-sub • Narrative searched with Autocoder • Enabled: companies accept their terms
AERS Esub ProgramAdditional Information • www.fda.gov/cder (CDER) • www.fda.gov/cder/aers/regs.htm (AERS) • Reporting regulations, guidances, and updates • www.fda.gov/cder/aerssub (PILOT) • aersesub@cder.fda.gov (EMAIL) • www.fda.gov/cder/present (CDER PRESENTATIONS)
AERS Esub ProgramAdditional Information(cont’d) • www.fda.gov (FDA) • www.fda.gov/oc/electronicsubmissions/interfaq.htm (GATEWAY) • Draft Trading Partner Agreement, Frequently Asked Questions (FAQs) for FDA’s ESTRI gateway • edigateway@oc.fda.gov (EMAIL) • www.fda.gov/medwatch/report/mfg.htm (MEDWATCH) • Reporting regulations, guidances, and updates
AERS Esub ProgramAdditional Information(cont’d) • www.ich.org (ICH home page) • www.fda.gov/cder/m2/default.htm(M2) • ICH ICSR DTD 2.0 • www.meddramsso.com (MedDRA MSSO) • http://www.ifpma.org/pdfifpma/M2step4.PDF • ICH ICSR DTD 2.1 • http://www.ifpma.org/pdfifpma/e2bm.pdf • New E2BM changes • http://www.ifpma.org/pdfifpma/E2BErrata.pdf • Feb 5, 2001 E2BM editorial changes
AERS Users FDA Contractor Compliance AERS FOIA Safety Evaluators
Uses of AERS • Safety Signal Detection • Creation of Case Profiles • who is getting the drug • who is running into trouble • Hypothesis Generation for Further Study • Signals of Name Confusion
Other references • C. Anello and R. O’Neill. 1998, Postmarketing Surveillance of New Drugs and Assessment of Risk, p 3450-3457; Vol 4 ,Encylopedia of Biostatistics, Eds. Armitage and Colton, John Wiley and Sons • Describes many of the approaches to spontaneous reporting over the last 30 years
Related work on signal generation and modeling • Finney , 1971, WHO • O’Neill ,1988 • Anello and O’Neill, 1997 -Overview • Tsong, 1995; adjustments using external drug use data; compared to other drugs • Compared to previous time periods • Norwood and Sampson, 1988 • Praus, Schindel, Fescharek, and Schwarz, 1993 • Bate et al. , 1998; Bayes,
References • O’Neill and Szarfman, 1999; The American Statistician , Vol 53, No 3; 190-195 Discussion of W. DuMouchel’s article on Bayesian Data Mining in Large Frequency Tables, With an Application to the FDA Spontaneous Reporting System (same issue)
Recent Post-marketing signaling strategies : Estimating associations needing follow-up • Bayesian data mining • Visual graphics • Pattern recognition
The structure and content of FDA’s database: some known features impacting model development • SRS began in late 1960’s (over 1.6 million reports) • Reports of suspected drug-adverse event associations submitted to FDA by health care providers (voluntary, regulations) • Dynamic data base; new drugs, reports being added continuously ( 250,000 per year) • Early warning system of potential safety problems • Content of each report • Drugs (multiple) • Adverse events (multiple) • Demographics (gender,age, other covariates)
The structure and content of FDA’s database: some known features impacting model development • Quality and completeness of a report is variable, across reports and manufacturers • Serious/non-serious - known/unknown • Time sensitive - 15 days • Coding of adverse events (COSTART) determines one dimension of table - about 1300 terms • Accuracy of coding / interpretation
The DuMouchel Model and its Assumptions • Large two-dimensional table of size M (drugs) x N (ADR events) containing cross classified frequency counts - sparse • Baseline model assumes independence of rows and columns - yields expected counts • Ratios of observed / expected counts are modeled as mixture of two, two parameter gamma’s with a mixing proportion P • Bayesian estimation strategy shrinks estimates in some cells • Scores associated with Bayes estimates used to identify those cells which deviate excessively from expectation under null model • Confounding for gender and chronological time controlled by stratification
The Model and its Assumptions • Model validation for signal generation • Goodness of fit • ‘higher than expected’ counts informative of true drug-event concerns • Evaluating Sensitivity and Specificity of signals • Known drug-event associations appearing in a label or identified by previous analysis of the data base; use of negative controls where no association is known to be present • Earlier identification in time of known drug-event association
Finding “Interestingly Large” Cell Counts in a Massive Frequency Table • Large Two-Way Table with Possibly Millions of Cells • Rows and Columns May Have Thousands of Categories • Most Cells Are Empty, even though N.. Is very Large • “Bayesian Data Mining in Large Frequency Tables” • The American Statistician (1999) (with Discussion) • Analyzed SRS Database with 1398 Drugs and 952 AE Codes • Nij= Count of Reports Containing Drug i and Event j • Only 386K out of 1331K Cells Have Nij > 0 • 174 Drug-Event Combinations Have Nij > 1000 • Naïve Baseline Frequencies Eij = Ni. N.j / N.. • Extension to Stratification: Sum Independence Frequencies Defined Separately over Strata Based on Age, Sex, etc.
Associations of Items in Lists • “Market Basket” Data from Transaction Databases • Tabulating Sets of Items from a Universe of K Items • Supermarket Scanner Data—Sets of Items Bought • Medical Reports—Drug Exposures and Symptoms • Sparse Representation—Record Items Present • Pijk= Prob(Xi= 1, Xj = 1, Xk = 1), (i < j < k) • Marginal Counts and Probabilities: Ni ,Nij , Nijk , …Pi , Pij , Pijk • Conditional Probabilities: Prob( Xi| Xj , Xk) = Pijk /Pjk , etc. • Pi Small, but SiPi (= Expected # Items/Transaction) >> 1 • Search for “Interestingly Frequent” Item Sets • Item Sets Consisting of One Drug and One Event Reduce to the GPS Modeling Problem
Definitions of Interesting Item Sets • Data Mining Literature: Find All (a, b) Associations • E.g., Find all Sets (Xi , Xj , Xk) Having Prob( Xi | Xj , Xk) > a & Prob(Xi , Xj , Xk) > b • Complete Search Based on Proportions in Dataset, with No Statistical Modeling • Note that a Triple (Xi , Xj , Xk) Can Qualify even if Xi Is Independent of (Xj ,Xk)! • We Use Joint P’s, Not Conditional P’s, and Bayesian Model • E.g., Find all (i, j, k): Prob(lijk = Pijk/pijk > l0| Data) > d • pijk are Baseline Values • Based on Independence or some other Null Hypothesis
Empirical Bayes Shrinkage Estimates • Compute Posterior Geometric Mean (L) and 5th Percentile (l.05) of Ratios • lij = Pij /pij , lijk = Pijk /pijk , lijkl = Pijkl /pijkl , etc. • Baseline Probs p Based on Within-Strata Independence • Prior Distributions of ls Are Mixtures of Two Conjugate Gamma Distributions • Prior Hyperparameters Estimated by MLE from Observed Negative Binomial Regression • EB Calculations Are Compute-Intensive, but merely Counting Itemsets Is More So • Conditioning on Nijk > n* Eases Burden of Both Counting and EB Estimation • We Choose Smaller n* than in Market Basket Literature
The rationale for stratification on gender and chronological time intervals • New drugs added to data base over time • Temporal trends in drug usage and exposure • Temporal trends in reporting independent of drug: publicity, Weber effect • Some drugs associated with gender-specific exposure • Some adverse events associated with gender independent of drug usage • Primary data-mining objective: are signals the same or different according to gender (confounding and effect modification) • A concern: number of strata, sparseness, balance between stratification and sensitivity/specificity of signals
The control group and the issue of ‘compared to what?’ • Signal strategies compare • a drug with itself from prior time periods • with other drugs and events • with external data sources of relative drug usage and exposure • Total frequency count for a drug is used as a relative surrogate for external denominator of exposure; for ease of use, quick and efficient; • Analogy to case-control design where cases are specific ADR term, controls are other terms, and outcomes are presence or absence of exposure to a specific drug.
Other metrics useful in identifying unusually large cell deviations • Relative rate • P-value type metric- overly influenced by sample size • Shrinkage estimates for rare events potentially problematic • Incorporation of a prior distribution on some drugs and/or events for which previous information is available - e.g. Liver events or pre-market signals
Interpreting the empirical Bayes scores and their rankings: the Role of visual graphics(Ana Szarfman) • Four examples of spatial maps that reduce the scores to patterns and user friendly graphs and help to interpret many signals collectively • All maps are produced with CrossGraphs and have drill down capability to get to the data behind the plots
Example 1A spatial map showing the “signal scores” for the most frequently reported events (rows) and drugs (columns) in the database by the intensity of the empirical Bayes signal score (blue color is a stronger signal than purple)
Example 2Spatial map showing ‘fingerprints’ of signal scores allowing one to visually compare the complexity of patterns for different drugs and events and to identify positive or negative co-occurrences
Example 3Cumulative scores and numbers of reports according to the year when the signal was first detected for selected drugs
Example 4Differences in paired male-female signal scores for a specific adverse event across drugs with events reported (red means females greater, green means males greater)
Why consider data mining approaches • Screening a lot of data, with multiple exposures and multiple outcomes • Soon becomes difficult to identify patterns • The need for a systematic approach • There is some structure to the FDA data base, even though data quality may be questionable
Two applications • Special population analysis • Pediatrics • Two or more item associations • Drug interactions • Syndromes (combining ADR terms)
Pediatric stratifications (age 16 and younger) • Neonates • Infants • Children • Adolescents • Gender
Item Association • Outcomes • Drug exposures - suspect and others • Events • Covariates • Confounders • Uncertainties of information in each field • dosage, formulation, timing, acute/chronic exposure • Multiplicities of dimensions
Why apply to pediatrics ? • Vulnerable populations for which labeling is poor and directions for use is minimal - a set up for safety concerns • Little comparative clinical trial experience to evaluate effects of • Metabolic differences, use of drugs is different, less is known about dosing, use with food, formalations and interactions Gender differences of interest
Challenges in the future • More real time data analysis • More interactivity • Linkage with other data bases • Quality control strategies • Apply to active rather than passive systems where non-reporting is not an issue