Download

1 / 52
520 likes | 664 Views
Aggregate features for relational data Claudia Perlich, Foster Provost. Pat Tressel 16-May-2005. Overview. Perlich and Provost provide... Hierarchy of aggregation methods Survey of existing aggregation methods New aggregation methods Concerned w/ supervised learning only

E N D
Aggregate features for relational dataClaudia Perlich, Foster Provost Pat Tressel 16-May-2005
Overview • Perlich and Provost provide... • Hierarchy of aggregation methods • Survey of existing aggregation methods • New aggregation methods • Concerned w/ supervised learning only • But much seems applicable to clustering
The issues… • Most classifiers use feature vectors • Individual features have fixed arity • No links to other objects • How do we get feature vectors from relational data? • Flatten it: • Joins • Aggregation • (Are feature vectors all there are?)
Joins • Why consider them? • Yield flat feature vectors • Preserve all the data • Why not use them? • They emphasize data with many references • Ok if that’s what we want • Not ok if sampling was skewed • Cascaded or transitive joins blow up
Joins • They emphasize data with many references: • Lots more Joes than there were before...
Joins • Why not use them? • What if we don’t know the references? • Try out everything with everything else • Cross product yields all combinations • Adds fictitious relationships • Combinatorial blowup
Joins • What if we don’t know the references?
Aggregates • Why use them? • Yield flat feature vectors • No blowup in number of tuples • Can group tuples in all related tables • Can keep as detailed stats as desired • Not just max, mean, etc. • Parametric dists from sufficient stats • Can apply tests for grouping • Choice of aggregates can be model-based • Better generalization • Include domain knowledge in model choice
Aggregates • Anything wrong with them? • Data is lost • Relational structure is lost • Influential individuals are lumped in • Doesn’t discover critical individuals • Dominates other data • Any choice of aggregates assumes a model • What if it’s wrong? • Adding new data can require calculations • But can avoid issue by keeping sufficient statistics
Taxonomy of aggregates • Why is this useful? • Promote deliberate use of aggregates • Point out gaps in current use of aggregates • Find appropriate techniques for each class • Based on “complexity” due to: • Relational structure • Cardinality of the relations (1:1, 1:n, m:n) • Feature extraction • Computing the aggregates • Class prediction
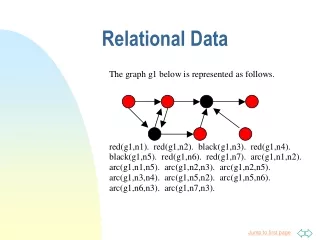
Taxonomy of aggregates • Formal statement of the task: • Notation (here and on following slides): • t, tuple (from “target” table T, with main features) • y, class (known per t if training) • Ψ, aggregation function • Φ, classification function • σ, select operation (where joins preserve t) • Ω, all tables; B, any other table, b in B • u, fields to be added to t from other tables • f, a field in u • More, that doesn’t fit on this slide
Taxonomy of aggregates • Formal statement of the task: • Notation (here and on following slides): • Caution! Simplified from what’s in the paper! • t, tuple (from “target” table T, with main features) • y, class (known per t if training) • Ψ, aggregation function • Φ, classification function • σ, select operation (where joins preserve t) • Ω, all tables; B, any other table, b a tuple in B • u, fields to be added to t from joined tables • f, a field in u • More, that doesn’t fit on this slide
Aggregation complexity • Simple • One field from one object type • Denoted by:
Aggregation complexity • Multi-dimensional • Multiple fields, one object type • Denoted by:
Aggregation complexity • Multi-type • Multiple object types • Denoted by:
Relational “concept” complexity • Propositional • No aggregation • Single tuple, 1-1 or n-1 joins • n-1 is just a shared object • Not relational per se – already flat
Relational “concept” complexity • Independent fields • Separate aggregation per field • Separate 1-n joins with T
Relational “concept” complexity • Dependent fields in same table • Multi-dimensional aggregation • Separate 1-n joins with T
Relational “concept” complexity • Dependent fields over multiple tables • Multi-type aggregation • Separate 1-n joins, still only with T
Relational “concept” complexity • Global • Any joins or combinations of fields • Multi-type aggregation • Multi-way joins • Joins among tables other than T
Current relational aggregation • First-order logic • Find clauses that directly predict the class • Ф is OR • Form binary features from tests • Logical and arithmetic tests • These go in the feature vector • Ф is any ordinary classifier
Current relational aggregation • The usual database aggregates • For numerical values: • mean, min, max, count, sum, etc. • For categorical values: • Most common value • Count per value
Current relational aggregation • Set distance • Two tuples, each with a set of related tuples • Distance metric between related fields • Euclidean for numerical data • Edit distance for categorical • Distance between sets is distance of closest pair
Proposed relational aggregation • Recall the point of this work: • Tuple t from table T is part of a feature vector • Want to augment w/ info from other tables • Info added to t must be consistent w/ values in t • Need to flatten the added info to yield one vector per tuple t • Use that to: • Train classifier given class y for t • Predict class y for t
Proposed relational aggregation • Outline of steps: • Do query to get more info u from other tables • Partition the results based on: • Main features t • Class y • Predicates on t • Extract distributions over results for fields in u • Get distribution for each partition • For now, limit to categorical fields • Suggest extension to numerical fields • Derive features from distributions
Do query to get info from other tables • Select • Based on the target table T • If training, known class y is included in T • Joins must preserve distinct values from T • Join on as much of T’s key as is present in other table • Maybe need to constrain other fields? • Not a problem for correctly normalized tables • Project • Include all of t • Append additional fields u from joined tables • Anything up to all fields from joins
Extract distributions • Partition query results various ways, e.g.: • Into cases per each t • For training, include the (known) class y in t • Also (if training) split per each class • Want this for class priors • Split per some (unspecifed) predicate c(t) • For each partition: • There is a bag of associated u tuples • Ignore the t part – already a flat vector • Split vertically to get bags of individual values per each field f in u • Note this breaks association between fields!
Distributions for categorical fields • Let categorical field be f with values fi • Form histogram for each partition • Count instances of each value fi of f in a bag • These are sufficient statistics for: • Distribution over fi values • Probability of each bag in the partition • Start with one per each tuple t and field f • Cft, (per-) case vector • Component Cft[i], count for fi
Distributions for categorical fields • Distribution of histograms per predicatec(t) and field f • Treat histogram counts as random variables • Regard c(t) true partition as a collection of histogram “samples” • Regard histograms as vectors of random variables, one per field value fi • Extract moments of these histogram count distributions • mean (sort of) – reference vector • variance (sort of) – variance vector
Distributions for categorical fields • Net histogram per predicate c(t), field f • c(t) partitions tuples t into two groups • Only histogram the c(t) true group • Could include ~c as a predicate if we want • Don’t re-count! • Already have histograms for each t and f – case reference vectors • Sum the case reference vectors columnwise • Call this a “reference vector”, Rfc • Proportional to average histogram over t for c(t) true (weighted by # samples per t)
Distributions for categorical fields • Variance of case histograms per predicatec(t) and field f • Define “variance vector”, Vfc • Columnwise sum of squares of case reference vectors / number of samples with c(t) true • Not an actual variance • Squared means not subtracted • Don’t care: • It’s indicative of the variance... • Throw in means-based features as well to give classifier full variance info
Distributions for categorical fields • What predicates might we use? • Unconditionally true, c(t) = true • Result is net distribution independent of t • Unconditional reference vector, R • Per class k, ck(t) = (t.y == k) • Class priors • Recall for training data, y is a field in t • Per class reference vector,
Distributions for categorical fields • Summary of notation • c(t), a predicate based on values in a tuple t • f, a categorical field from a join with T • fi, values of f • Rfc, reference vector • histogram over fi values in bag for c(t) true • Cft, case vector • histogram over fi values for t’s bag • R, unconditional reference vector • Vfc, variance vector • Columnwise average squared ref. vector • X[i], i th value in some ref. vector X
Distributions for numerical data • Same general idea – representative distributions per various partitions • Can use categorical techniques if we: • Bin the numerical values • Treat each bin as a categorical value
Feature extraction • Base features on ref. and variance vectors • Two kinds: • “Interesting” values • one value from case reference vector per t • same column in vector for all t • assorted options for choosing column • choices depend on predicate ref. vectors • Vector distances • distance between case ref. vector and predicate ref. vector • various distance metrics • More notation: acronym for each feature type
Feature extraction: “interesting” values • For a given c, f, select that fi which is... • MOC: Most common overall • argmaxiR[i] • Most common in each class • For binary class y • Positive is y = 1, Negative is y = 0 • MOP: argmaxiRft.y=1[i] • MON: argmaxiRft.y=0[i] • Most distinctive per class • Common in one class but not in other(s) • MOD: argmaxi |Rft.y=1[i] - Rft.y=0[i] | • MOM: argmaxi MOD / Vft.y=1[i] - Vft.y=0[i] • Normalizes for variance (sort of)
Feature extraction: vector distance • Distance btw given ref. vector & each case vector • Distance metrics • ED: Edit – not defined • Sum of abs. diffs, a.k.a. Manhattan dist? • Σi |C[i] – R[i] | • EU: Euclidean • √(C[i] T R[i] ), omit √ for speed • MA: Mahalanobis • √(C[i] TΣ-1 R[i] ), omit √ for speed • Σshould be covariance...of what? • CO: Cosine, 1- cos(angle btw vectors) • 1 - C[i] T R[i] / √ (|C[i] ||R[i] |)
Feature extraction: vector distance • Apply each metric w/ various ref. vectors • Acronym is metric w/ suffix for ref. vector • (No suffix): Unconditional ref. vector • P: per-class positive ref. vector, Rft.y=1 • N: per-class positive ref. vector, Rft.y=0 • D: difference between P and D distances • Alphabet soup, e.g. EUP, MAD,...
Feature extraction • Other features added for tests • Not part of their aggregation proposal • AH: “abstraction hierarchy” (?) • Pull into T all fields that are just “shared records” via n:1 references • AC: “autocorrelation” aggregation • For joins back into T, get other cases “linked to” each t • Fraction of positive cases among others
Learning • Find linked tables • Starting from T, do breadth-first walk of schema graph • Up to some max depth • Cap number of paths followed • For each path, know T is linked to last table in path • Extract aggregate fields • Pull in all fields of last table in path • Aggregate them (using new aggregates) per t • Append aggregates to t
Learning • Classifier • Pick 10 subsets each w/ 10 features • Random choice, weighted by “performance” • But there’s no classifier yet...so how do features predict class? • Build a decision tree for each feature set • Have class frequencies at leaves • Features might not completely distinguish classes • Class prediction: • Select class with higher frequency • Class probability estimation: • Average frequencies over trees
Tests • IPO data • 5 tables • Most fields in the “main” table, used as T • Other tables had key & one data field • Predicate on one field in T used as the class • Tested against: • First-order logic aggregation • Extract clauses using an ILP system • Append evaluated clauses to each t • Various ILP systems • Using just data in T • (Or T and AH features?)
Tests • IPO data • 5 tables w/ small, simple schema • Majority of fields were in the “main” table, i.e. T • The only numeric fields were in main table, so no aggregation of numeric features needed • Other tables had key & one data field • Max path length 2 to reach all tables, no recursion • Predicate on one field in T used as the class • Tested against: • First-order logic aggregation • Extract clauses using an ILP system • Append evaluated clauses to each t • Various ILP systems • Using just data in T (or T and AH features?)
Test results • See paper for numbers • Accuracy with aggregate features: • Up to 10% increase over only features from T • Depends on which and how many extra features used • Most predictive feature was in a separate table • Expect accuracy increase as more info available • Shows info was not destroyed by aggregation • Vector distance features better • Generalization
Interesting ideas (“I”) & benefits (“B”) • Taxonomy • I: Division into stages of aggregation • Slot in any procedure per stage • Estmate complexity per stage • B: Might get the discussion going • Aggregate features • I: Identifying a “main” table • Others get aggregated • I: Forming partitions to aggregate over • Using queries with joins to pull in other tables • Abstract partitioning based on predicate • I: Comparing case against reference histograms • I: Separate comparison method and reference
Interesting ideas (“I”) & benefits (“B”) • Learning • I: Decision tree tricks • Cut DT induction off short to get class freqs • Starve DT of features to improve generalization
Issues • Some worrying lapses... • Lacked standard terms for common concepts • “position i [of vector has] the number of instances of [ith value]”... -> histogram • “abstraction hierarchy” -> schema • “value order” -> enumeration • Defined (and emphasized) terms for trivial and commonly used things • Imprecise use of terms • “variance” for (something like) second moment • I’m not confident they know what Mahalanobis distance is • They say “left outer join” and show inner join symbol
Issues • Some worrying lapses... • Did not connect “reference vector” and “variance vector” to underlying statistics • Should relate to bag prior and field value conditional probability, not just “weighted” • Did not acknowledge loss of correlation info from splitting up joined u tuples in their features • Assumes fields are independent • Dependency was mentioned in the taxonomy • Fig 1 schema cannot support § 2 example query • Missing a necessary foreign key reference
Issues • Some worrying lapses... • Their formal statement of the task did not show aggregation as dependent on t • Needed for c(t) partitioning • Did not clearly distinguish when t did or did not contain class • No need to put it in there at all • No, the higher Gaussian moments are not all zero! • Only the odd ones are. Yeesh. • Correct reason we don’t need them is: all can be computed from mean and variance • Uuugly notation
Issues • Some worrying lapses... • Did not cite other uses of histograms or distributions extracted as features • “Spike-triggered average” / covariance / etc. • Used by: all neurobiology, neurocomputation • E.g.: de Ruyter van Steveninck & Bialek • “Response-conditional ensemble” • Used by: Our own Adrienne Fairhall & colleagues • E.g.: Aguera & Arcas, Fairhall, Bialek • “Event-triggered distribution” • Used by: me ☺ • E.g.: CSE528 project