Download
1 / 31
310 likes | 456 Views
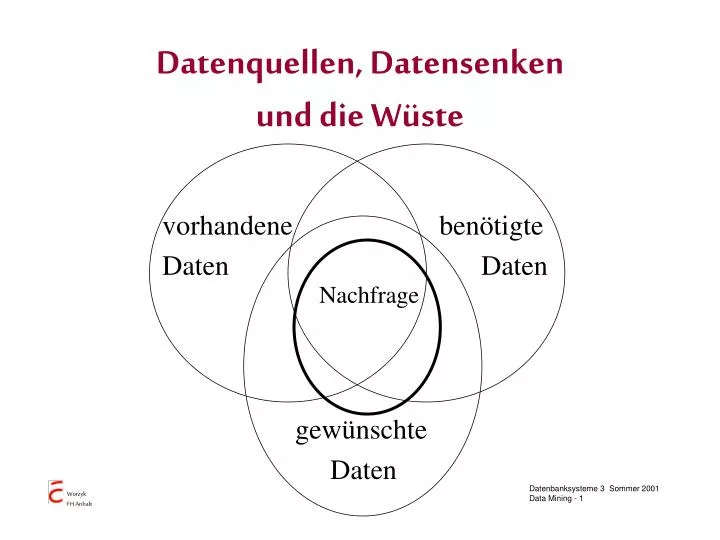
Datenquellen, Datensenken und die Wüste. vorhandene Daten. benötigte Daten. Nachfrage. gewünschte Daten. Informationsbedarf abhängig von der Aufgabe. Veränderlichkeit. Strukturiertheit. Definition Data Mining. Data Mining

E N D
Datenquellen, Datensenken und die Wüste vorhandene Daten benötigte Daten Nachfrage gewünschte Daten
Informationsbedarf abhängig von der Aufgabe Veränderlichkeit Strukturiertheit
DefinitionData Mining Data Mining „ is the nontrivial extraction of implicit, previous unknown and potentially useful information from data“ William J. Frawley Gregory Piatetsky-Shapiro,
Leistungsmerkmale • Hypothesenfreiheit • Automatisierte Vorhersage von Trends, Verhalten und Mustern • Automatisierte Aufdeckung unbekannter Strukturen • Zusatzkomponenten für Preprocessing und Ergebnisaufbereitung
Anwendungsbeispiele • Astronomie • Erdwissenschaften • Marketing • Investment • Betrugserkennung • Individualisierte Werbeanzeigen • Electronic Commerce • Datenschutz
Ansatz Tradi- tionell Hypothesen festlegen Methode entwickeln Datenbasis analysieren Ergebnisse verdichten Ergebnisse interpretieren Anwender Computer Experte Computer System Statistiker Anwender Data Mining Datenbasis analysieren Interessante Muster finden Ergebnisse interpretieren Anwender Data Mining System
DefinitionData Mining Data Mining „in databases is the non-trivial process of identifying valid, novel, potential useful, and ultimately understandable patterns in data“ William J. Frawley Gregory Piatetsky-Shapiro,
Information Daten (Semantik) sind aus Zeichen (Syntaktik) bestehende Abbilder der Wirklichkeit. Eine Nachricht (Semantik) ist eine Menge von Daten, die für ein Individuum eine inhaltliche Bedeutung hat. Information (Pragmatik) ist die Veränderung der verhaltenswirksamen Erkenntnis eines Individuums mittels einer Nachricht. Wissen ist der Gesamtbestand an verhaltenswirksamen Erkenntnissen eines Individuums.
Preprocessing Analyse Interpretation Validierung Data Mining Prozeßmodell Ext Daten OLTP Data Warehouse
Beteiligte am Data Mining Prozeß • Management • Vorgabe von Zielen • Wunsch nach hoch verdichteten und aussagekräftigen Ergebnissen • Fachabteilung • Aufträge für den Analysten • Fachliche Beratung • Validierung der Ergebnisse • Umsetzung der Ergebnisse • Analyst • Erstellen der Ergebnisse • Beurteilen der Analyseverfahren • Anforderungen an das Datenmodell
Datenschutz EU-Datenschutzrichtlinie besagt, dass die Verarbeitung von Daten, aus denen rassische oder ethnische Herkunft, politische Meinungen, religiöse und philosophische Überzeugungen oder die Gewerkschaftszugehörigkeit hervorgehen, sowie auch die Verarbeitungvon Daten über Gesundheit oder Sexualleben untersagt ist.
Prozeßmodell Data Warehouse
Data Warehouse Warum nicht die operationale Datenbank (OnLine Transaction Processing) ? • Zusätzliche Datenquellen • Hierarchische, objektorientierte Datenbanken • Files • Zusätzliche Indizes • Vergröberung und Verfeinerung • Anwenderfreundliche Abfragesprache
Antwortzeiten Antwortzeit sec. Zeit
OLTP - OLAP Trennung von OnLine Transaction Processing tägliche Routinebearbeitung der Daten Buchungen, Bestellungen, Erfassung von Meßergebnissen OnLine Analytical Processing sporadische oder regelmäßige Analyse der Daten Bearbeitung auf unterschiedlichen Rechnern
Datenübernahme • Regelmäßig durch Backup und Restore • OLAP-System kann als Backup genutzt werden • regelmäßiger neuer Aufbau der zusätzlichen Indizes • mittlere Aktualität • einmalige Übernahme der OLTP-Daten • einmaliger Aufbau der zusätzlichen Indizes • veraltete Daten • einmalige Übernahme aller relevanten Daten, dann Übernahme der Änderungen • automatischer Aufbau der zusätzlichen Indizes • beliebige Aktualität
Datenübernahme Wenn es irgendwie möglich ist, Datenbankfunktionalitäten für die Datenübernahme einsetzen und keine eigenen Programme erstellen. (kostet nur Zeit und Geld und ist fehleranfällig)
Datenübernahme Konsistenz: • Die Daten müssen in sich konsistent sein • im Verhältnis zu anderen Daten aus der gleichen Quelle • im Verhältnis zu Daten aus anderen Quellen • im Verhältnis zu den im Data Warehouse vorhandenen Daten
Datenübernahme Störungsfrei • Überwachung der regelmäßigen Datenübertragung • Überwachung des vorhandenen Speicherplatzes • performanter Aufbau der Indizes und der neuen Strukturen
Data Warehouse Extrem große Datenmengen -> neue Verfahren für Backup und Recovery -> riesige Tabellen (über mehrere Platten) -> Probleme beim Sortieren, Indizieren, Verbinden (Join)
Datenstruktur • Star - Schema • Snowflake - Schema • Starflake - Schema
Star Schema Kunde Lieferanten Verkaufs- transaktionen Ort Produkte Zeit Fakten Dimensionsdaten
Snowflake Schema Fakten Snowflake Dimensionsdaten Verkaufs- transaktionen Ort Produkte Art Zeit Region Woche Farbe Oster- verkauf SSV Monat
Starflake Schema Fakten Dimensionsdaten Snowflake Dimensionsdaten Lieferanten Kunde Verkaufs- transaktionen Ort Produkte Ort Art Zeit Region Produkte Zeit Farbe Woche Oster- verkauf SSV Monat
Mathetest • Wie sehen die zeitlichen Verläufe aus • Wie lange braucht der einzelnen Probant pro Frage • Welche Einträge sind plausibel • Welche Daten der Eltern sind plausibel? • Wie korrelieren die Antworten auf die Testfragen?
Tabellen ta_probant probant aufgaben_nr ergebnis_1 ergebnis_2 ergebnis_3 ergebnis_4 richtig datum ip_adresse ta_aufgaben aufgaben_nr augfaben_text loesung_1 loesung_2 loesung_3 loesung_4 kommentar_1 kommentar_2 kommentar_3 kommentar_4 richtige_loesung ta_mathetest_historie datum text ta_seite1 datum ip_adresse
Rohdaten 30.6.196017.4.19571 5 Apr 15 2000 1:28PM deeeeeeeee5 17 Apr 15 2000 1:29PM 24.03.195126.01.19481 7 Apr 15 2000 1:29PM 00.00.0000.00.0040 10 Apr 17 2000 4:07PM 15.11.195023.01.194814 1 Apr 18 2000 2:41PM 1409530805481 1 Jul 13 2000 4:34PM 29.7´5429.9´523 54 Sep 27 2000 8:20AM 01.01.0001.01.009 54 Sep 27 2000 2:05PM 20.05.195623.03.19531. 54 Oct 26 2000 9:54PM 1.1.19601.1.19601 2 Oct 30 2000 12:29PM ab0 3 Jan 10 2001 1:46PM ab0 54 Jan 11 2001 6:57PM
Aufgaben • Datenübernahme • Analyse der Zeiten zwischen zwei Einträgen der gleichen Probanten • Kippen der Tabelle (eine Zeile pro Probant) • Validierung der Einträge (wer ist ein ernsthafter Teilnehmer) • Bearbeiten der Geburtsdaten
Datenübertragung • In der Sybase-Datenbank anmelden • select auf die Tabellen • Ausgabe so formatieren, dass sie insert für die Zieldatenbank ergibt • Ausgabe in eine Datei speichern • In der Oracle-Datenbank anmelden • insert, dabei fortlaufende Nummer vergeben









