Download

1 / 1
10 likes | 157 Views
Variational Algorithms for Marginal MAP. Qiang Liu Alexander Ihler Department of Computer Science, University of California, Irvine. Variational Approximations. Abstract.

E N D
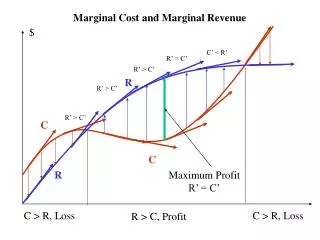
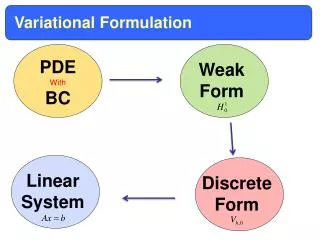
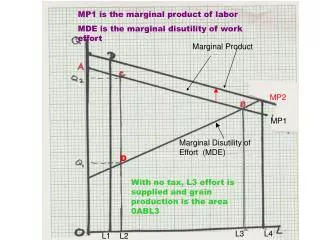
Variational Algorithms for Marginal MAP QiangLiu Alexander Ihler Department of Computer Science, University of California, Irvine Variational Approximations Abstract • Marginal MAP tasks seek an optimal configuration of the marginal distribution over a subset of variables. Marginal MAP can be computationally much harder than more common inference tasks. • We show • a general variational framework for marginal MAP problems • analogues to Bethe, tree-reweighted, & mean-field approximations • novel upper bounds via the tree-reweighted free energy • “mixed” message passing and CCCP-based solvers • conditions for global or local optimality of the solutions • close connections to EM and variational EM approaches • Bethe approximation (exact on A-B tree) • “Truncated” free energy max (B) sum (A) • Tree-reweighted approximation (convex comb. of A-B trees) • Dual in terms of edge appearances Variational Algorithms Graphical Models • Mixed-product message passing • start with “standard” weighted message passing • Generalize zero-temperature limit results of Weiss et al. (2007) • Apply limit directly to messages ( for Bethe, for TRW) • Graphical models: • Factors & exponential family form • Factors are associated with cliques of a graph G=(V,E) • Tasks: sum (A) max (B) A!A[B Sum- product B!B Max- product • Max-Inference • (MAP, MPE) B!A Match max and sum Harder max • Match updates interpretable as a “local” marginal MAP problem • Mixed marginals satisfy a reparameterization property • Fixed points are locally optimal (similar to max-product results) • Convergence can be an issue sum • Sum-Inference • (partition function, probability of evidence) • Mixed-Inference • (marginal MAP, MAP) • Double-loop algorithms • Decompose H into two parts H=H+ - H- & iteratively linearize H- • CCCP algorithm: take H+, H- to be convex • Can also take H+ to be the Bethe approximation (non-convex) • Iteratively solve sum-product and apply truncation correction • Mixed inference problems can be hard even in trees, since • A-B trees extend notion of efficient structure to mixed inference • Ensure graph structure remains a tree during inference • Two example sub-types: max sum Example from D. Koller and N. Friedman (2009) Connections to EM • Restrict to the mean-field like product subspace • Coordinate-wise updates = in the primal: “Type 1” “Type 2” Variational Form • Reformulate inference as a distributional optimization problem • Define and Experiments • Sum-Inference • Chain graphs • GA is a tree • TRW1: type-1 only • TRW2: ½ type-1, ½ type 2 • Bethe: most accurate • EM: stuck quickly (2-3 iter.) • Max-Inference This work • Mixed-Inference • Grid graphs • Attractive or mixed potentials • GA has cycles • Similar trends % correct solutions Energy relative error Sum-inference: Mixed-inference: (with equality when q=p) (with equality when q = p(A|B) 1(B=B*) or similar) Attractive Mixed