Download
1 / 1
• 10 likes • 147 Views
Grapheme-to-Phoneme Model Generation for Indo-European Languages Tim Schlippe, Sebastian Ochs, Tanja Schultz tim.schlippe@kit.edu. 1. Overview Motivation Quality of pronunciation dictionary is important for Speech Recognition

E N D
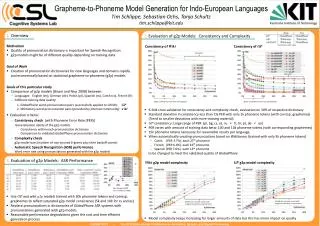
Grapheme-to-Phoneme Model Generation for Indo-European Languages Tim Schlippe, Sebastian Ochs, Tanja Schultz tim.schlippe@kit.edu • 1. Overview • Motivation • Quality ofpronunciationdictionaryisimportantfor Speech Recognition • g2p modelsmightbeof different qualitydepending on trainingdata • Goal of Work • Creationofpronunciationdictionariesfornewlanguagesanddomainsrapidlyandeconomicallybased on statisticalgrapheme-to-phoneme (g2p) models • Goals ofthisparticularstudy • Comparison of g2p models [Bisani and Ney, 2008] between: • Languages: English (en), German (de), Polish (pl), Spanish (es), Czech (cs), French (fr) • Different trainingdataquality: • 1. GlobalPhoneword-pronunciationpairs (successfullyappliedto LVCSR): GP • 2. Wiktionaryword-pronunciationpairs (providedby Internet community): wikt • Evaluation criteria: • Consistency check (with Phoneme Error Rate (PER)) • Generalizationabilityofthe g2p models • Consistencywithineachpronunciationdictionary • ComparisontovalidatedGlobalPhonepronunciationdictionary • Complexity check g2p model sizes (numberof non-pruned 6-grams plus theirbackoffscores) • Automatic Speech Recognition (ASR) performanceWord error rate usingpronunciationsgeneratedwiththe g2p models 2. Evaluation of g2p Models: ConsistencyandComplexity Consistency check setup. Consistency of Wikt Consistency of GP Saturation , Saturation Betterconsistencywithmoretrainingdata Betterconsistencywithmoretrainingdata • 6-fold cross validationforconsistencyandcomplexity check, evaluation on 30% ofrespectivedictionary • Standard deviation in consistencylessthan 1% PER withonly 1k phonemetokens (withcorresp. graphemes) • (Trend tosmaller deviations with more training material) • GPconsistency: Large rangeof PER (pl, bg, cs, es, ru < fr, hr, pt, de < en) • PER varieswithamountoftrainingdatabetw. 100 and 10k phonemetokens (withcorrespondinggraphemes) • 15k phonemetokensnecessaryforreasonableresults per language, • Whenautomaticallycreatingpronunciationsbased on Wiktionary(trained with only 5k phoneme tokens) • Czech (PER 3.7%): each 27th phoneme • French (PER 6.4%): each 16th phoneme • Spanish (PER 7.6%): each 13th phoneme • to be changed to meet the validated quality of GlobalPhone • Model complexitykeepsincreasingfor larger amountsofdata but thishasminorimpact on quality • 3. Evaluation of g2p Models: ASR Performance • Use GP and wiktg2p models trained with 30k phoneme tokens and corresp. graphemes to reflect saturated g2p model consistency (5k and 10k for cs and es) • Replace pronunciations in dictionaries of GlobalPhone ASR systems with pronunciations generated with g2p models • Reasonable performance degradations given the cost and time efficient generation process Wikt g2p model complexity GP g2p model complexity Rel. change in WER overconsistency (PER) Model sizeincreasecomeswithmaginalconsistencyimprovement Model sizeincreasecomeswithmaginalconsistencyimprovement ICASSP 2012 – The 37th International Conference on Acoustics, Speech, and Signal Processing





















