Download

1 / 17
170 likes | 456 Views
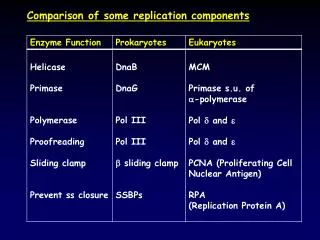
Erasure Coding vs. Replication: A Quantiative Comparison. Presented By Mr. P. H. Chan. Background . Authors: Hakim Weatherspoon and John D. Kubiatowicz from CS Division of UC Berkeley.

E N D
Erasure Coding vs. Replication: A Quantiative Comparison Presented By Mr. P. H. Chan
Background • Authors: Hakim Weatherspoon and John D. Kubiatowicz from CS Division of UC Berkeley. • They have launched a project called “Oceanstore”, a distributed, peer-to-peer storage server in about November 2000. • This paper compares Erasure coding with replication when applied on Oceanstore.
List of sections • Background • Introduction • System architecture of Oceanstore (very brief) • Availability • System Model • Comparisons (Bandwidth, storage, disk seek and MTTF) • Discussion
Introduction • For a peer to peer system, one crucial problem is reliability. • Erasure coding and Replications are two commonly used method to improve reliability of these system. • With these fault resilient algorithms and a repairing algorithms, the mean time to failure (MTTF) of the system will be increased.
Introduction • Generally speaking, we know that erasure code is better than replication. • What is improved? How much is improved? • Is it worthwhile to use erasure coding? • This paper gives a quantitative approach to evaluate the performance gain of erasure code over replication based on Oceanstore.
System Architecture • Data are divided in the unit of blocks. • Replication/Erasure coding is applied to code the blocks into “fragments”. • These fragments are distributed to the workstations in the system. • Fragments belongs to the same group of blocks will not be placed in the same workstation. • A central management server will constantly retrieve the fragments belongs to each data blocks.
System Architecture • If there are workstation broken down, some fragments will be missing. • The management server will reproduce the missing fragment and place it in other workstations. • (Assumption) A dead machine will be immediately replaced by a new, blank workstation. • The time period between the examinations of the same block group is called an “epoch”.
Availability • Probability to have a block available in the system.
Availability • With N = 1 million, M=10k. • Two replicas provide 0.99 availability. • Erasure coding at rate ½ (rate = original data / erasure coded data) gives 0.999999998 availability. • Erasure coding improves availability.
System Model • The Max. number of blocks in the system • MTTF of system and MTTF of block
System Model • The storage requirement • The bandwidth requirement
System Model • Number of disk seeks
System Model • Comparing the case of using erasure code and replication, we found that the ratio of disk seeks, storage and bandwidth requirement are all equal to R*r.
Comparisons • With each user writing data to the system at a rate 35MB/hr, b = 8kB, dbsz = 8kB, N=224 users, erepl = eerase = 4 months, and MTTFsystems = 1000 years, Number of replica need to sustain such MTTF is R = 22 and erasure code need r = ½ to have that MTTF. • Thus, R*r = 11.
Comparisons (find MTTFblock) • With R = 2, r = 32/64 and erepl = eerase = 4 months, MTTFblock of replication scheme is 74 years and that of erasure code is 1020 years. • (recall)
Discussion • This paper presented a quantitative approach to calculate the performance gain of using erasure code. • Mapping of erasure code to data require intensive CPU time. • System MTTF decrease significantly with increasing number of blocks.