Download

1 / 15
170 likes | 331 Views
Planning experiments in genomics and transcriptomics. Daniel Hurley. Introduction: some general thoughts. Here we will talk about general principles for planning experiments

E N D
Planning experiments in genomics and transcriptomics Daniel Hurley
Introduction: some general thoughts • Here we will talk about general principles for planning experiments • These apply to both exploratory experiments (e.g. sequencing and de novo assembly of an uncharacterised organism) and comparative ‘analysis of variation’ experiments • Important because genomics and transcriptomics can be bewildering: many different data types, many different standards • Discussion before the experiment begins is the best choice for a good outcome
Planning: what to think about • Define an experimental question • Consider your sample input • Think about variance and replication • Get a clear idea of outputs • Consider pilot and follow-up experiments
Defining an experimental question • If you have a clear idea of what you want to do • The project will probably involve people from different domains of knowledge • Invest time in communication
Defining an experimental question • If you don’t have a specific question in mind • Come and discuss opportunities associated with different technologies
Consider your sample • Different technologies will require different quantities and types of sample • Guidelines can be worked around, but every manipulation introduces artifacts in the data
Outputs are what matter • Tools change very quickly • A bioinformatician’s job is to help you make sense of tools, data formats, technologies • Aim to understand the outputs from an experiment in detail before you do the experiment
Design: variance and replication • How many replicates is ‘enough’ for a comparative experiment? • The short answer is ‘it depends’ • On your estimate of effect strength • On the signal-to-noise ratio of the detector • On the amount of variance within conditions • Three observations is the minimum to (usefully) define a distribution • Choose your replication strategy to capture the variance that interests you… • …and correct for the variance that doesn’t
Design: variance and p-values • The more variance within a condition… • Precise interpretation of a p-value is complex • But it’s uncontroversial (I think!) to say that it’s a proxy measure of the weight of evidence against a null hypothesis • Multiple testing hypothesis problem: we are more likely to see what looks like an interesting result due to chance alone • Can correct for this using false discovery rate assessment and control P-values capture this intuition in a numeric and rankable form. • The less convincing a result (= less evidence against the null hypothesis)
Data: when do you believe the results? I’m sceptical • Skeptical Hippo says “multiple hypothesis testing is very important” • T-tests work fine for realtime RT-PCR, or a chi-square test, or Fisher’s Exact Test • For high-throughput comparative experiments, there are more sophisticated approaches for modelling difference and adjusting for multiple hypothesis testing • The Bonferroni correction is often too conservative • Benjamini-Hochberg FDR is a pragmatic approach for exploratory bioinformatics • Various ways of doing this in RNAseq data, but no one clear approach or piece of software
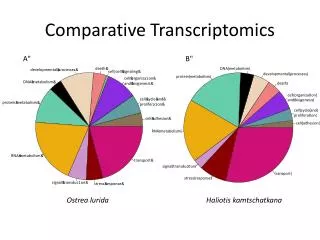
Data visualisation High-altitude views of the data Each tool represents data in a different way, and all tell us something important
Summary: what to do • Spend time defining your experimental question so it’s clear to everyone involved • Get advice on technology, experimental design, and research outputs • Choose replication and conditions which capture the variance that interests you, and correct for the variance that doesn’t • Be conservative about the number of different questions you ask at once; consider pilot and follow-up experiments • Keep returning to your data. Actively look for as many ways as possible to visualise similarity and difference within the data
Fin Any questions?