Download
1 / 1
10 likes | 163 Views
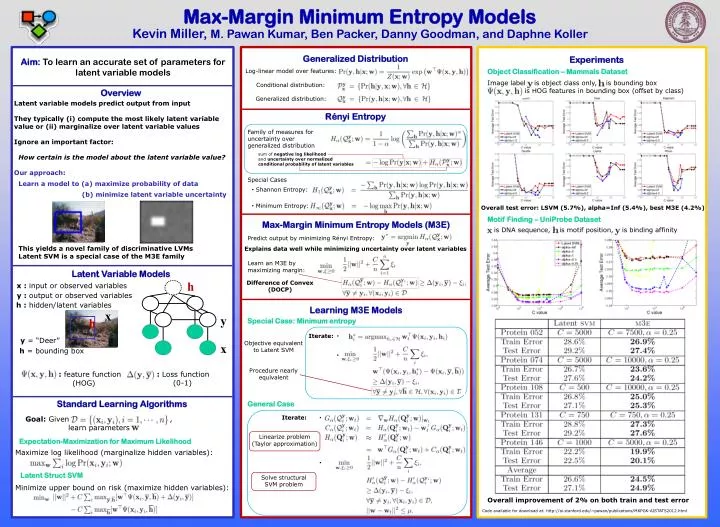
h. x. y. h. x. Max-Margin Minimum Entropy Models. Kevin Miller, M. Pawan Kumar, Ben Packer, Danny Goodman, and Daphne Koller . Generalized Distribution. Experiments. Aim: To learn an accurate set of parameters for latent variable models.

E N D
h x y h x Max-Margin Minimum Entropy Models Kevin Miller, M. Pawan Kumar, Ben Packer, Danny Goodman, and Daphne Koller Generalized Distribution Experiments Aim: To learn an accurate set of parameters for latent variable models Object Classification – Mammals Dataset Log-linear model over features: Image label y is object class only, h is bounding box is HOG features in bounding box (offset by class) Conditional distribution: Overview Generalized distribution: Latent variable models predict output from input They typically (i) compute the most likely latent variable value or (ii) marginalize over latent variable values Ignore an important factor: How certain is the model about the latent variable value? Our approach: Learn a model to (a) maximize probability of data (b) minimize latent variable uncertainty This yields a novel family of discriminative LVMs Latent SVM is a special case of the M3E family Rényi Entropy Family of measures for uncertainty over generalized distribution sum of negative log likelihood and uncertainty over normalized conditional probability of latent variables • Shannon Entropy: Special Cases • Minimum Entropy: Overall test error: LSVM (5.7%), alpha=Inf (5.4%), best M3E (4.2%) Motif Finding – UniProbe Dataset Max-Margin Minimum Entropy Models (M3E) x is DNA sequence, h is motif position, y is binding affinity Predict output by minimizing Rényi Entropy: Explains data well while minimizing uncertainty over latent variables Learn an M3E by maximizing margin: Latent Variable Models Difference of Convex (DOCP) x : input or observed variables y : output or observed variables h : hidden/latent variables Learning M3E Models Special Case: Minimum entropy Iterate: y = “Deer” Objective equivalent to Latent SVM Procedure nearly equivalent h = bounding box : Loss function (0-1) : feature function (HOG) Standard Learning Algorithms General Case Iterate: Goal: Given , learn parameters Linearize problem (Taylor approximation) Expectation-Maximization for Maximum Likelihood Maximize log likelihood (marginalize hidden variables): Latent Struct SVM Solve structural SVM problem Minimize upper bound on risk (maximize hidden variables): Overall improvement of 2% on both train and test error Code available for download at: http://ai.stanford.edu/~pawan/publications/MKPGK-AISTATS2012.html


















