Download

1 / 31
310 likes | 349 Views
Explore parsing in programming languages, symbol tables, abstract syntax trees, and data structures for symbol tables and ASTs.

E N D
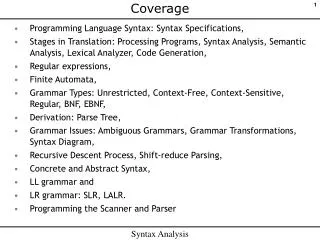
3. Phase 2 : Syntax Analysis Part I • Parsing. • The symbol table. • The abstract syntax tree. • Representing statements & expressions. • Recursive descent parsing. • A bit of theory.
Parsing • Given a grammar and a particular sequence of symbols, either : • Find how that sequence might be derived from the sentence symbol by using the productions of the grammar. • Or, show that the sequence could not be derived from the sentence symbol and therefore is not a sentence. • In programming language terms, for ‘sentence’ read ‘source program’ and for ‘sequence’ read ‘contents of the file being parsed’. • The parser reads the file and checks that the contents could be derived from the production rules. If not it produces compile time error messages.
Parsing II • If the source program is syntactically correct then parsing produces : • Symbol table (ST) from the declarations. • Abstract syntax tree (AST) from the statements. • If the source program is syntactically incorrect then parsing produces : • Error messages. • ST and AST data structures and error messages declared in syner.h in phase 2 unit directory : /usr/users/staff/aosc/cm049icp/phase2
The Symbol Table • A data structure recording all the user defined symbols (i.e. identifiers) declared in the program. • Either a variable sized array or a linked list. • No variable sized arrays in C++ so we’ve got to use a linked list. • C++ does have dynamic arrays but they are not variable sized. • Each (user defined) identifier is stored in a struct with elements for its name, type and other things as desired. • Used to determine what identifiers refer to during syntax analysis and code generation.
The Symbol Table II • For a real language the ST is a sequence of frames, one per subprogram. • Frame : Conceptually, a sequence of entries, one per variable / constant. • C-- has no subprograms so the ST is simply a sequence of entries. • Example C-- source : const string s = “Hello” ; int n = 0 ; bool b ; { ... }
ident : “b” type : BOOLDATA constFlag : false initialise : NULL address : 0 next : ident : “n” type : INTDATA constFlag : false initialise : address : 0 next : 0 ident : “s” type : STRINGDATA constFlag : true initialise : address : 0 next : NULL “Hello” Symbol Table Entries • Schematic diagram : Stored in reverse of declaration order.
C++ Data Structures For The Symbol Table • In syner.h : enum DataType { VOIDDATA, BOOLDATA, STRINGDATA, INTDATA } ; struct SymTab { string ident ; DataType type ; bool constflag ; Factor *initialise ; int address ; SymTab *next ; } ; struct Factor { ... // Later. } ;
if > = = b 6 x 0 y x The Abstract Syntax Tree • An abstract representation of the program. • An n-ary tree. • Example C-- source : if (b > 6) x = 0 ; else y = x ; • Of course it’s nowhere near as simple as this diagram suggests.
C++ Data Structures For The Abstract Syntax Tree • In syner.h : enum StatType { NULLST, ASSIGNST, IFST, WHILEST, CINST, COUTST } ; struct AST { StatType tag ; AssignSt *assignst ; IfSt *ifst ; WhileSt *whilest ; CinSt *cinst ; CoutSt *coust ; AST *next ; } ;
tag : ASSIGNST next : assignst : tag : COUTST next : NULL coutst : AST for x = 23 + 4 AST for cout << x Schematic Diagram Of An Abstract Syntax Tree Built in reverse order. Must then be reversed. • Example C-- program : void main() { x = 23 + 4 ; cout << x ; } Unused fields set to NULL.
target expr AST for y + z * 34 ST entry for x Assignment Statements • Example C-- source : x = y + z * 34 ; • C++ data structure : struct AssignSt { SymTab *target ; Expression *expr ; } ; • The Expression data structure is quite complicated. • Must handle arbitrary expressions. • Later.
if Statements • Example C-- source : if (a > b) { cout << a ; } else { cout << b ; } ; • C++ data structure : struct IfSt { Expression *condition ; AST *thenstats ; AST *elsestats ; int elselabel ; int endlabel ; } ; The { and } are obligatory in C--. So is the ;. elselabel and endlabel are used in code generation.
AST for a > b condition : thenstats : elsestats : elselabel : 0 thenlabel : 0 AST for cout << a AST for cout << b if Statements II • Schematic diagram :
while Statements • Example C-- source : while (a > 0) { a = a - 1 ; cout << a ; } ; • C++ data structure : struct WhileSt { Expression *condition ; AST *stats ; int startlabel ; int endlabel ; } ; The { and } are obligatory in C--. So is the ;. startlabel and endlabel are used in code generation.
AST for a > 0 condition : stats : startlabel : 0 endlabel : 0 AST for a = a - 1 ; cout << a ; while statements II • Schematic diagram :
cin statements • Example C-- source : cin >> a ; • C++ data structure : struct CinSt { SymTab *invar ; } ; • Schematic diagram : a must be an intvariable in C--. Symbol table entry for a. invar :
Symbol table entry for a. outvar : cout statements • Example C-- source : cout >> a ; • C++ data structure : struct CoutSt { SymTab *outvar ; } ; • Schematic diagram : a must be an int variable or constant or a string constant in C--.
Expressions • C-- syntax : expression ::= basic_exp [ rel_op basic_exp ] basic_exp ::= term { add_op basic_exp } term ::= factor {mul_op term } factor ::= literal | identifier | ‘(‘ expression ‘)’ | ‘!’ factor • Example expressions : 22 + 4 < b z != y a !true
Expressions II • In syner.h : struct Expression { BasicExp *be1 ; string relOp ; BasicExp *be2 ; } ; struct BasicExp { Term *term ; string addOp ; BasicExp *bexp ; } ; struct Term { Factor *fact ; string mulOp ; Term *term ; } Unused fields set to ““ or NULL as appropriate.
Factors • In syner.h : struct Factor { bool literal ; // Tag field DataType type ; // Type field string litBool ; // Boolean literal string litString ; // String literal int litInt ; // Integer literal SymTab *ident ; // Identifier Expression *bexp ; // Bracket expression Factor *nFactor ; // Negated factor } ; • Literal is short for literal constant. • Note that C-- does not allow negative integer literals. • Makes things a lot simpler. • Unused fields are ignored. • Set to ““ or 0 or NULL as appropriate.
be1 : relOp : ““ be2 : NULL term : addOp : ““ bexp : NULL fact : mulOp : ““ term : NULL literal : true type : intData litBool : ““ litString : ““ litInt : 42 ident : NULL bexp : NULLnFactor : NULL Example Expressions • Example C-- expression : 42 • Schematic diagram :
be1 : * relOp : “<“ be2 : term : addOp : ““ bexp : NULL fact : mulOp : ““ term : NULL literal : false type : intData litBool : ““ litString : ““ litInt : 0 ident : bexp : NULLnFactor : NULL Symbol table entry for a Example Expressions II * as from be1 on last slide. • Example C-- expression : 42 < a • Schematic diagram :
Recursive Descent Parsing • Notice that the AST is a recursive data structure. • Definition : for recursion see recursion. • This is necessary because C-- has a recursive syntax : • while and if statements may include other statements. • Expressions include basic expressions which include terms which include factors which include expressions. • The simplest way to syntax analyse a recursive syntax is via a method known as recursive descent syntax analysis. • Usually called recursive descent parsing although technically parsing is syntax analysis plus lexical analysis.
Recursive Descent Parsing II • In a recursive descent parser we write a subprogram to recognise each of the different syntactic constructs. • One subprogram per production rule (more or less). • Each analysis subprogram calls the lexAnal to get tokens as required. • Each analysis subprogram may call other functions to recognise component syntactic constructs. • synStatement will call synAssign, synIf, synWhile etc. • synIf and synWhile will call synStatementrecursively. • Lots more on how to do recursive descent parsing in the next lecture.
Chomsky Grammars • Noam Chomsky is an American linguist (among other things). • Chomsky’s theories about the syntactic structure of languages are very popular with Computists. • Much less popular with Linguists. • Chomsky identified 4 types of grammar. • Increasing levels of restrictions on the production rules. • In a Chomsky type 0 grammar all production rules are of the form A ::= alpha where A is a non-empty string of non-terminal symbols and alpha is a string of terminal and/or non-terminal symbols. • Type 0 is the most general type of grammar. • Often called free grammars. • Natural language grammars.
Chomsky Grammars II • A Chomsky type 1 grammar contains only production rules of the form beta A gamma ::= beta alpha gamma where A is a single non-terminal symbol and alpha, beta and gamma are strings of terminal and/or non-terminal symbols. • i.e. each production replaces a single non-terminal symbol in a particular context. • Often called context-sensitive grammars.
Chomsky Grammars III • A Chomsky type 2 grammar contains only production rules of the form A ::= alpha where A is a single non-terminal symbol and alpha is a string of terminal and/or non-terminal symbols. • Often called context-free grammars. • A Chomsky type 3 grammar contains only production rules of the forms A ::= a and A ::= bB in which A and B are single non-terminal symbols and a and b are single terminal symbols. • Often called regular-expression grammars.
Programming Languages And Chomsky Grammars • In programming languages the syntax of statements, expressions etc. is defined by a type 2 grammar. • Syntax analysis works on type 2 grammars. • Type 3 grammars are used to define the micro-syntaxof lexical items such as identifiers, literals and strings. • Lexical analysis works on type 3 grammars. • Note that a type 3 grammar is also a type 2 grammar. • A type 2 grammar is also a type 1 grammar. • A type 1 grammar is also a type 0 grammar. • In general type 0 grammars cannot be analysed by a computer. • The other 3 types can be analysed by a computer.
Backtracking • Consider the following grammar : S ::= ‘c’ A ‘d’ A ::= ‘a’ ‘b’ | ‘a’ • Suppose the input sequence is “cad”. • Parser consumes ‘c’. • Chooses first alternative for A and consumes ‘a’. • Parser now looking for a ‘b’ which is not present. • Parser must backtrack and try the second alternative for A. • Parser consumes ‘a’. • Parser consumes ‘d’. • Backtracking is inefficient and makes the parser more complex to write.
Predictive Parsing • It is reasonably straightforward to construct a grammar which can be parsed without backtracking. • Simplest type is the LL(1) grammar : • An LL(1) grammar can be parsed by reading the input left to right. • At each step the leftmost derivation is produced. • Only the leftmost non-terminal in the sequence is replaced. • Which production rule should be used at each step can be uniquely determined from the tokens already consumed, the current input token and a peek at the next input token. • 1 token lookahead. • C-- has an LL(1) grammar. • Ideal for recursive descent predictive parsing.
Summary • Syntax analysis : determining whether or not a file contains a syntactically correct program. • Recursive descent parsing : One subprogram to syntax analyse each (major) syntactic construct. • Symbol table holds information about user defined identifiers for use in syntax analysis and code generation. • Abstract syntax tree holds an abstract representation of the statements for use in syntax analysis and code generation. • Chomsky grammars are used to define the syntax of programming languages. • C-- has an LL(1) Chomsky type 2 grammar.