Download

1 / 54
560 likes | 763 Views
Advanced Statistics I. Xiayu (Stacy) Huang Bioinformatics Shared Resource Sanford | Burnham Medical Research Institute. Outline. Summary of Previous Talk Descriptive & inferential statistics T test Common statistical tests and Applications (Continue) One-way ANOVA

E N D
Advanced Statistics I Xiayu (Stacy) Huang Bioinformatics Shared Resource Sanford | Burnham Medical Research Institute
Outline • Summary of Previous Talk • Descriptive & inferential statistics • T test • Common statistical tests and Applications (Continue) • One-way ANOVA • Post hoc/multiple comparison tests • One-way ANOVA power analysis • Common data transformation methods
Why statistics is important to biologists? • Designing experiment • Analyzing biological data and understanding analysis results • Preparing manuscript and grant applications How many ??? How many replicates for my microarray exp??? Identifying outlier Normalization/transformation Statistical test, etc. DEGs No replicates=No statistics?
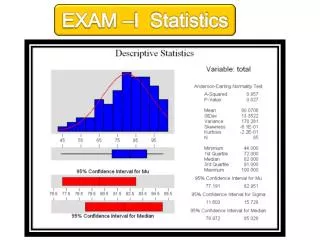
Summary of previous talk • Descriptive statistics • Measure of central tendency (mean, median, mode) • Measure of dispersion (standard deviation, range, etc). Previous ppt can be downloaded from http://bsrweb.burnham.org
Summary of previous talk • Inferential statistics • Null hypothesis (H0) and alternative hypothesis(Ha) • Type I and type II errors (aka. false positives and false negatives) • P-value (statistically significant if less than cut off α at 0.05 level) • Power (probability of detecting a true difference, 0.80) • T test • 3 types of t tests • T test can be performed in excel and Graphpad Prism • Power analysis of t test in G*Power new drug effect = old drug effect new drug effect ≠ or > old drug effect
Analysis of variance (ANOVA) Overview • History of ANOVA • Ronald Fisher proposed ANOVA in 1918 • His first application of ANOVA was published in 1921 • What does ANOVA do? • Comparing the means of 3 or more populations without knowing the exact difference between population means • Types of ANOVA • One-way and multi-way ANOVA (# of factors of interest) • Repeated measures ANOVA (repeated measurements on the same subject) • MANOVA (# of different measurements)
ANOVA Overview • How to decide which ANOVA to use? • How many different measurements? =>ANOVA or MANOVA • How many factors of interest? =>One-way or multi-way • Are there any repeated measures? => Repeated or not • Examples • 1: how the tumor size changes among three different mice genotypes within 7 weeks? (tumor volume measured every week) Measurements: factors: repeated measures: • 2: how the tumor size and body weight change among three different mice genotypes within 7 weeks? tumor size=>ANOVA genotype and time=>two-way Decision: two-way repeated ANOVA repeated Measurements: tumor size and body weight=>MANOVA Factors: genotype and time=>two-way Repeated measures: repeated Decision: two-way repeated MANOVA
ANOVA application in biology One-way ANOVA Two-way ANOVA One-way MANOVA Two-way repeated ANOVA
One-way ANOVA • One measurement, no repeats, one factor with multiple levels (“groups”) e.g. comparing the effect of three different drug treatments (control, drug A and drug B) on body weight • Measurement: body weight; Factor: treatment; Level: control, drug A and drug B • Hypothesis • H0: • Having no treatment effect • Ha:at least 1 population mean is different • Having treatment effect
One-way ANOVA • Basic idea • compares 2 types of variation to test equality of population means • Source of variation(error) Total variation (SS(Total)) Variation among treatments (SST) Variation within treatments (SSE) SS(total)=SST+SSE
One-way ANOVA • Source of variation group1 group2 group3 :Mean of group1; n1:sample size in group1 :Mean of group2; n2:sample size in group2 :Mean of group3; n3:sample size in group3 : overall mean of all the samples group1 group2 group3 variation among treatments total variation group1 group2 group3 variation within treatments
One-way ANOVA • F test statistic • F statistic is a ratio of two variations • variation among treatments/(k-1) • variation within treatments/(n-k) • k=number of populations, treatment groups, or levels • n=total sample size • Large F values indicating variation among treatments is significantly greater than variation within treatments and there is an treatment effect • P-value computed from F statistic F= = p
One-way ANOVA • Assumptions • Sampling should be independent and randomized. • Homogeneity of variance • Populations (for each condition) have equal variances • Check by Bartlett’s or Levene’s test • Normality • Populations (for each condition) are normally distributed • Check by normality test (such as Kolmogorov-Smirnov test) • Normal distribution=Gaussian distribution=>“bell-shaped” curve Note: equal sample size is preferred
One-way ANOVA example • Goal: determining whether there is a significant effect of different mice groups on their performance on rotarod. • Measurement: number of seconds staying on a rotarod
Statistical test decision tree Relationship between variables Two sample comparison One measurement Multiple sample comparison
Statistical test decision tree Number of measurement Number of factors
Variance check and ANOVA analysis in graphpad prism SST SSE SS(Total)
ANOVA analysis results of example data • Conclusion • There is at least one group of mice with different performance on rotarod than that of the other group of mice • Next • What are the exact differences between different groups? • Are groups 1 and 2 significantly different? Are groups 1 and 3 significantly different?
Post hoc/multiple comparison tests introduction • ANOVA does not differ groups from each other • Problem of doing multiple t tests • High combined false positive error rate • 6 multiple t tests will give 26% chance of having at least one false positive error • Multiple comparison tests • They are based on T test or F test by considering the number of comparisons and adjust the p-value obtained from regular T test • Pairwise comparisons • Pairwise comparisons are differences between any two population means. On k populations or groups, there are k(k-1)/2 possible pairwise comparisons
Post hoc/multiple comparison tests introduction • Error rate • Familywise error rate(FWER) • Probability of making at least one false positive among all the comparisons • --Example: 4 groups, #of all possible pairwise comparisons=4(4-1)/2=6 • if the allowed false positive rate for each comparison is 0.05, the probability of making at lease one false positive is 1-(1-0.05)6 =0.26 • control FWER at given α level such as 0.05 • False discovery rate (FDR) • Used for large data sets such as microarray • Probability of declared significant results that are actually false positives • --Example: If 1000 genes were declared to have statistical significance, and FDR=0.05, then 50 genes would be expected to be false positives • Control FDR at given α level such as 0.05
Common post hoc/multiple comparison tests • Fisher’s protected least significant difference(fisher’s LSD) • The first post hoc developed by Fisher to study pairwise comparisons • Assumptions: equal variances, normality, and significant F test results • Does not control FWER • Tukey’s test • Most popular post hoc and suitable for all pairwise comparisons (6 or more) • Assumptions: equal variances and normality • Control FWER and suitable for both equal and unequal sample size • Bonferroni test • Suitable for any set of preplanned comparison • αper comparison= α/total number of comparisons • Control FWER, too conservative in many situations
Common post hoc/multiple comparison tests • Benjamini-hochberg false discovery rate(FDR) • Proposed by Benjamini and Hochberg in 1995 • Four step procedures • Conduct m separate t-tests for m genes, each at common significance level 0.05 • Order p-value of m genes from smallest to largest • Find the largest K such that Pk ≤(k/m)*α • Declare genes 1…K are statistically significantly different between two comparing groups. • Less conservative than Bonferroni test and more powerful than familywise error rate
Post hoc /multiple comparison tests example • Goal: determining whether there is an overall significant difference of performance among the four mice groups and how the performance of each mice group is different from each other. • Measurement: number of seconds staying on a rotarod # of possible pairwise comparison: 4x(4-1)/2=6 Multiple comparison test: Tukey’s test(6 or more comparisons)
Post hoc /multiple comparison tests example • Goal: determining whether there is a statistically significant difference between WT and KO for a set of m=12 genes at FDR (Q)=0.05. Order by p-value in increasing order Find largest K Pk ≤ (k/m)Q Conclusion: two genes (SLU7 and LGI1 ) are statistically significant different between WT and KO among the 12 genes tested at FDR(Q)=0.05
Outline • Summary of Previous Talk • Descriptive & inferential statistics • T test • Common statistical tests and Applications (Continue) • One-way ANOVA • Post hoc/multiple comparison tests • One-way ANOVA power analysis • Common data transformation methods
Power analysis • Power depends on: • Sample size ( ) • Standard deviation ( or ) • Minimal detectable difference ( ) • False positive rate ( ) • What you can do with power analysis • Minimal sample size required • Minimal detectable difference or effect size • Power of the test effect size
Power analysis software/packages • G*Power (free!!!) • Optimal design (free!!!) • SPSS sample power • PASS • SAS proc power, Stata sampsi, etc • Mplus for more advanced/complicated analysis • Many free on-line programs • http://www.stat.uiowa.edu/~rlenth/Power/
One-way ANOVA power analysis in G*Power • Test family • F test • Statistical test • ANOVA, fixed effect, omnibus, one-way • Type of power analysis • Compute sample size-given α, power, and effect size • Input parameters • Effect size ( f ) • False positive rate ( ) • usually 0.05 • Minimum Power ( ) • usually 0.80 • Number of groups • Output parameters • Noncetrality parameter ( ) • Critical F • Degree of freedom • Total sample size • Actual power
One-way ANOVA sample size calculation • Goal: how many mice should I use so as to have an 80% of probability of detecting observed difference at the 0.05 level of significance?
One-way ANOVA sample size calculation in G*Power ANOVA analysis results
Outline • Summary of Previous Talk • Descriptive & inferential statistics • T test • Common statistical tests and Applications (Continue) • One-way ANOVA • Post hoc/multiple comparison tests • One-way ANOVA power analysis • Common data transformation methods
Data Transformation • Why? • Many biological variables do not follow normal distribution • How? • Applying a mathematical function on each observation • Performing statistical tests using transformed data • Interpreting results using back transformation • Common data transformation methods in biology • Log transformation • Square root transformation • Arcsine transformation • Reciprocal transformation
Log transformation • Usage • Convert a right skewed distribution into a symmetrical one • Applicable when there are unequal variances and standard deviations are proportional to the means • Mathematical function • Logarithms in any base are satisfactory • Back transformation:
Square root transformation • Usage • Applicable when the group variances are proportional to the means • Samples taken from Poisson distribution such as counting data • Mathematical function • Back transformation:
Arcsine transformation • Usage • Applicable when data (proportions or percentages) was taken from a binomial distribution • Mathematical function • Back transformation: • Shortcoming • Not good at the ends of the range (near 0 and 100%) • Adjustment needed when p near 0 and 100%
Choosing transformation methods based on data distribution Shape Figure Transformation Reverse J A 1/X Severe skew right B Log (X) Moderate skew right C sqrt (X)
Choosing transformation based on data distribution Shape Figure Transformation Moderate skew left D 1/sqrt(X) Severe skew left E -1/Log (X) J shape F -1/X
Data transformation example frequency weight Histogram
Choosing transformation based on data distribution Shape Figure Transformation Reverse J A 1/X Severe skew right B Log (X) Moderate skew right C sqrt (X)
Data transformation example frequency frequency log2_weight weight before transformation after transformation