Download

1 / 21
210 likes | 228 Views
This study focuses on explicitly learning local shapes through experience in the game of Atari-Go. The research aims to teach a value for the goodness of each shape and incorporates multi-scale representations to facilitate rapid learning and fine differentiation. The results indicate that knowledge of local shapes can be easily interpreted and transferred to different board sizes, offering insights into global strategic concepts.

E N D
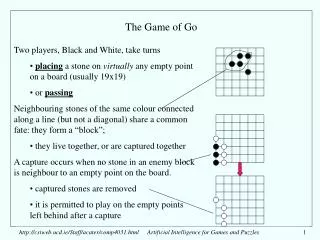
Reinforcement Learning of Local Shape in the Game of Atari-Go David Silver
Local shape • Local shape describes a pattern of stones • Corresponds to expert Go knowledge • Joseki (corner patterns) • Tesuji (tactical patterns) • Used extensively in current strongest programs • Pattern databases • Difficult to extract expert Go knowledge, and input into pattern databases • Focus of this work • Explicitly learn local shapes through experience • Learn a value for the goodness of each shape
Prior work • Supervised learning of local shapes • Local move prediction [Stoutamire, Werf] • Mimics strong play rather than learning to evaluate and understand positions • Reinforcement learning of neural networks • TD(0) [Schraudolph, Enzenberger] • Shape represented implicitly, difficult to interpret • Limited in scope by network architecture
Local shape features • Specifies configuration of stones within a rectangular window • Takes account of rotational, reflectional and colour inversion symmetries • Location dependent (LD) features • Specifies canonical position on board • Location invariant (LI) features • Can appear anywhere on board
Local shape features 2x2 LI feature 2x2 LD feature Position
Local shape features • All possible configurations enumerated • For each window size from 1x1 up to 3x3 • Both LI and LD shapes Numbers of features (active and total)
Partial ordering of local feature sets • There is a partial ordering > over the generality of local feature sets • Small windows > large windows • LI > LD
Value function • Reward of +1 for winning, 0 for losing • Value function estimates total expected reward from any position, i.e. the probability of winning • Move selection is done by 1-ply greedy search over value function • Value function is approximated by a single linear threshold unit • Local shape features are inputs to the LTU
Temporal difference learning • Update value of each position towards the new value after making a move • For tabular value function • V(st) = [r + V(st+1) - V(st)] • For linear threshold unit, assign credit to each active feature • = r + V(st+1) - V(st) • i = V(s)(1 - V(st))
Minimum liberty opponent • To evaluate a position s: • Find block of either colour with fewest liberties • Set colmin to colour of minimum liberty block • Set libmin to number of liberties • If both players have a block with l liberties, colmin is set to minimum liberty player • Evaluate position according to: • Select move with 1-ply greedy search
Training procedure • Random policy rarely beats minimum liberty player • So train against an improving opponent • Opponent plays some random moves, enough to win 50% of games • Random moves are reduced as agent improves • Eventually there are no random moves • Testing is always performed against full opponent (no random moves)
Results on 5x5 board • Different combinations of feature sets tried • Just one feature set F • All feature sets as or more general than F • All feature sets as or less general than F • Percentage wins during testing after 25,000 training games
Results on 5x5 board Single specified feature set, location invariant
Results on 5x5 board All feature sets as or more general than specified set
Board growing results • Board grown from 5x5 to 9x9 • Board size increased when winning 90% • Weights transferred from previous size • Percentage wins shown during training
Board growing • Local shape features have a direct interpretation • The same interpretation applies to different board sizes • So transfer knowledge from one board size to the next • Learn key concepts rapidly and extend to more difficult contexts
Example game • 7x7 board • Agent plays black • Minimum liberty opponent plays white • Agent has learned strategic concepts: • Keeping stones connected • Building territory • Controlling corners
Conclusions • Local shape knowledge can be explicitly learnt directly from experience • Multi-scale representation helps to learn quickly and provide fine differentiation • Knowledge is easily interpretable and can be transferred to different board sizes • The combined knowledge of local shape is sufficient to express global strategic concepts
Future work • Stronger opponents, real Go not Atari-Go • Learn shapes selectively rather than enumerating all possible shapes • Learn shapes to answer specific questions • Can black B4 be captured? • Can white connect A2 to D5? • Learn non-local shape: • Use connectivity relationships • Build hierarchies of shapes