Download

1 / 27
270 likes | 281 Views
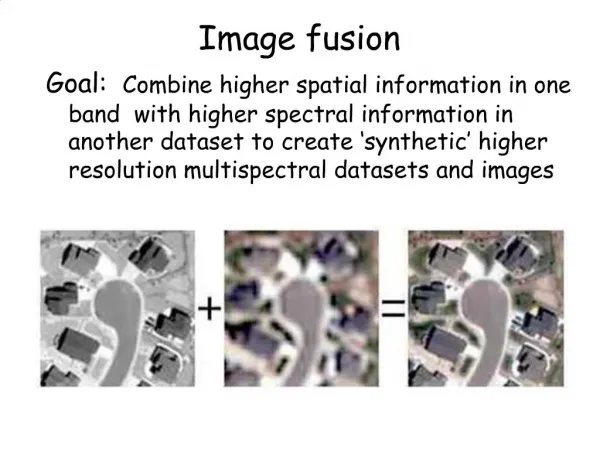
This paper presents a query-adaptive fusion strategy for image search and person re-identification, effectively combining different features to improve search results. It also introduces a reference set method for feature normalization, making the system resistant to the influence of bad features.

E N D
Query Adaptive Late Fusion for Image Search and Person Re-identification Liang Zheng, Shengjin Wang, Lu Tian, Fei He, Ziqiong Liu, and Qi Tian 2015-7-29
Outline Introduction Problem and Motivation Related Work Method Experiments and Comparisons Conclusions and Future Work
Introduction query Image Search query
query Introduction Cam-a database Cam-b Person Re-identification
Introduction • Some statements: • Color is a good feature • Statistically, color is a good feature on a certain dataset • Color is a good feature for a certain image • We want to use good features for every query image. × √ √
Introduction Rank list 1 Feature 1 Late Fusion Cosine distance with database images Pipeline Final rank list Query Feature 2 Rank list 2 …… …… Feature K Rank list K
Problem × Color √ Color √ For a given query image, we do not know whether features 1, 2, …, K are effective or not. Shape × Shape
Related Work Combining local and global features on index-level Co-indexing (Zhang et al, ICCV 2013, PAMI 2015) Globally similar images All features have fixed weights Inverted Index
Related Work Combine different features on the rank level Graph Fusion (Zhang et al, ECCV 2012, PAMI 2014) Feature 1 Feature 2 Feature 1 + Feature 2 All features have fixed weights
Method - Similarity Function For images q and d, their similarity score under feature i is. Their similarity function after fusion Kfeatures is, where wq(i) is the query-adaptive weight of feature for query .
Method - Motivation Good feature: L-shaped score curve Bad Feature: Flat score curve
Method Final score curve Original score curve Normalized score curve Step 1. Normalize the original score curves Step 2. Calculate the area under the normalized score curve. Small area -> good feature, vice versa. Step 3. Merge all the original score curves with Eq. 1. The query-adaptive weights negatively correlates with the area under the normalized score curve.
Method - Normalization Why normalization? For some features, the score curve may have a “high tail”, reflecting intrinsic property of a feature.
Method - Normalization Offline step a randomly selected query How to normalize? 1 million arbitrarily retrieved images from Flickr. Randomly select Q images as query. Search the database with these queries and K features. Each feature will have Q score curves Reference Set
Method - Normalization Online step Reference Set Given a query image, we have K original score curves For each original score curve Remember We have Q reference score curves We find the nearest reference score curve to the tail of the original score curve. We subtract the selected reference curve from the original curve. We linearly normalize the residual: max = 1, min = 0. After normalization, the area under the score curve is negatively related to the weight of the feature.
Method – similarity function • For images and , their similarity score under feature is . The similarity function after fusion all features is, • Where is the area under the normalized score curve for feature
Method - Normalization The impact of normalization We eliminate the influence of the tail For some features, the score curve may have a “high tail”
Method The impact of normalization
Experiments Datasets Features Good Features Bad Features
Experiments and Comparisons Good Features:BoW, HSV, CNN Bad Features:GIST, Random Normalizationvs No normalization
Experiments and Comparisons Good Features:BoW, HSV, CNN Bad Features:GIST, Random Ours vs Co-indexing (ICCV’13, PAMI’15)
Experiments and Comparisons We add as many as 20 random projection features to the system. Robustness to Bad Features
Experiments and Comparisons Time cost Comparison with state-of-the-arts
Experiments and Comparisons • Experiment settings on VIPeR dataset • We use a BoW representation – 5600 dim • For each local patch, we extract • 20-dim HS histogram • 11-dim Color Names (CN) • LBP • HOG Feature 1: HS BoW Feature 2: CN BoW Feature 3: LBP BoW Feature 4: HOG BoW Feature 5: eSDC (Zhao et al, CVPR 2013) Zheng et al, Person re-identification meets image search. arXiv preprint:1502.02171 (2015).
Experiments and Comparisons Results on VIPeR dataset
Conclusions A query-adaptive fusion strategy is proposed Bad features are down-weighted Good features are up-weighted Reference set is independent on the test image database Does not require extensive offline steps Works well when database changes Our method is resistant to bad features, so it enables “safe” search