Download

1 / 16
160 likes | 174 Views
This paper discusses a method for evaluating naturalness in conversational dialog systems, focusing on the LifeLike virtual avatar project. It explores the background of early conversational systems, ALICEbot, recent advances, and proposed evaluation frameworks like PARADISE. The approach emphasizes a balance of quantitative and qualitative measures, including task success, dialog performance, and human-like interaction indicators.

E N D
Towards a Method For Evaluating Naturalness in Conversational Dialog Systems Victor Hung, Miguel Elvir, Avelino Gonzalez & Ronald DeMara Intelligent Systems Laboratory University of Central Florida IEEE International Conference on Systems, Man, and Cybernetics San Antonio, Texas October 12, 2009
Agenda • Introduction • Background • Approach • Project LifeLike
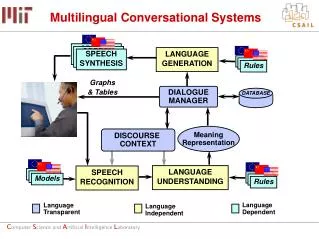
Introduction Interactive Conversation Agent Evaluation Cannot rely solely on quantitative methods Subjectivity in ‘naturalness’ No general method to judge how well a conversation agent performs Pivotal focus will be defining naturalness How well a chatbot can maintain a natural conversation flow LifeLike virtual avatar project as a backdrop Provide a suitable validation and verification method
Background: Early Systems Declarative knowledge to process data Explicitly defined rules Constrained knowledge Limited capacity to assess and adapt Goal-oriented and data-driven behavior ALICEbot
Background: Naturalness Automatic Speech Recognition Context retrieval experimentation Intelligent tutoring Adaptive Control of Thought Knowledge Acquisition agents Quality of the information received Conversation length metric ALICE-based bots
Background: Recent Advances Sentence-based template matching Simple conversational memory CMU’s Julia, Extempo’s Erin Interaction occurs in a reactive manner Wlodzislaw et al Development of cognitive modules and human interface realism Ontologies, concept description vectors, semantic memory models, CYC
Background: Recent Advances Becker and Wachsmuth Representation and actuation of coherent emotional states Lars et al Model for sustainable conversation Awareness of the human users and the conversation topics Relies on textual input similar to ELIZA Use of natural language processing for reasoning about human speech
Background: Conclusion Breadth of research using chatbots Focus on creating more sophisticated interpretative conversational modules Need exists for generalizable metrics Conversational agents widely experimented with, but it has been lacking a basic framework for universal performance comparison
Approach: Previous Approaches Mix of quantitative and qualitative measures Subjective matters employ human user questionnaire Semeraro et al’s bookstore chatbot 7 characteristics: impression, command, effectiveness, navigability, ability to learn, ability to aid, comprehension. Does not provide statistical conclusiveness General indicator of performance
Approach: Previous Approaches Shawar and Atwell’s universal chatbot evaluation system ALICE-based Afrikaans conversation agent Dialog efficiency Dialog quality: reasonable, weird but understandable, and nonsensical Users’ satisfaction, qualitatively measured Proper assessment is end result in how successfully it accomplishes its intended goals
Approach: Previous Approaches Evaluation of naturalness similar to general chatbot assessment Rzepka et al’s 1-to-10 scale metrics Naturalness degree Willing to continue a conversation degree Human judges used these measures to evaluate a conversation agent’s utterances No concrete baseline for naturalness Able to make relative measurements of naturalness between dialog agents
Approach: Chatbot Objectives Walker et al’s PARAdigm for DIalogue System Evaluation (PARADISE) Dialog performance relates to the experience of the interaction (means) Task success is concerned with the utility of the dialog exchange (ends) Objectives Better than other dialog system solutions Similar to a human-to-human (naturalness) interaction
Approach: Task Success Measure of goal satisfaction Attribute-value matrix Derived from PARADISE Expected vs. actual Task success (κ) computed as the percentage of correct responses
Approach: Performance Function Derived from PARADISE Total effectiveness Task success (κ) weighted by (α) Dialog costs (ci) weighted by (wi) Function (N) uses Z-score normalization Balance out (κ) and (ci)
Approach: Proposed System Task success Dialog costs Efficiency Resource consumption Quantitative Quality Actual conversational content Quantitative or qualitative