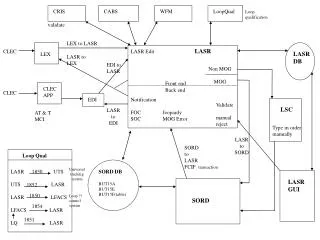
Download
1 / 20
220 likes | 379 Views
Using Lex. Introduction. When you write a lex specification, you create a set of patterns which lex matches against the input. Each time one of the patterns matches, the lex program invokes C code that you provide which does something with the matched text. Introduction (Cont’d).

E N D
Introduction • When you write a lex specification, you create a set of patterns which lex matches against the input. • Each time one of the patterns matches, the lex program invokes C code that you provide which does something with the matched text.
Introduction (Cont’d) • Lex itself doesn’t produce an executable program; instead it translates the lex specification into a file containing a C routine called yylex(). • Your program calls yylex()to run the lexer.
The format of regular expressions in lex • The notation is slightly different from that used in our text book.
Regular Expressions • Regular expressions used by Lex (See pages 28 and 29) . * [] ^ $ {} \ + ? | “…” / ()
Examples of Regular Expressions • [0-9] • [0-9]+ • [0-9]* • -?[0-9]+ • [0-9]*\.[0-9]+ • ([0-9]+)|([0-9]*\.[0-9]+) • -?(([0-9]+)|([0-9]*\.[0-9]+)) • [eE][-+]?[0-9]+ • -?(([0-9]+)|([0-9]*\.[0-9]+))([eE][-+]?[0-9]+)?)
The Structure of a Lex Program (Definition section) %% (Rules section) %% (User subroutines section)
Example 1-1: Word recognizer ch1-02.l %{ /* * this sample demonstrates (very) simple recognition: * a verb/not a verb. */ %} %% [\t ]+ /* ignore white space */ ; is | am | are | were | was | be | being | been | do | does | did | will | would | should | can | could | has | have | had | go { printf("%s: is a verb\n", yytext); } [a-zA-Z]+ { printf("%s: is not a verb\n", yytext); } .|\n { ECHO; /* normal default anyway */ } %% main() { yylex(); }
The definition section • Lex copies the material between “%{“ and “%}” directly to the generated C file, so you may write any valid C codes here
Rules section • Each rule is made up of two parts • A pattern • An action • E.g. [\t ]+ /* ignore white space */ ;
Rules section (Cont’d) • E.g. is | am | are | were | was | be | being | been | do | does | did | will | would | should | can | could | has | have | had | go { printf("%s: is a verb\n", yytext); }
Rules section (Cont’d) • E.g. [a-zA-Z]+ { printf("%s: is not a verb\n", yytext); } .|\n { ECHO; /* normal default anyway */ } • Lex had a set of simple disambiguating rules: • Lex patterns only match a given input character or string once • Lex executes the action for the longestpossible match for the current input
User subroutines section • It can consists of any legal C code • Lex copies it to the C file after the end of the Lex generated code %% main() { yylex(); }
Example 2-1 %% [\n\t ] ; -?(([0-9]+)|([0-9]*\.[0-9]+)([eE][-+]?[0-9]+)?) { printf("number\n"); } . ECHO; %% main() { yylex(); }
A Word Counting Program • The definition section %{ unsigned charCount = 0, wordCount = 0, lineCount = 0; %} word [^ \t\n]+ eol \n
A Word Counting Program (Cont’d) • The rules section {word} { wordCount++; charCount += yyleng; } {eol} { charCount++; lineCount++; } . charCount++;
A Word Counting Program (Cont’d) main(argc,argv) int argc; char **argv; { if (argc > 1) { FILE *file; file = fopen(argv[1], "r"); if (!file) { fprintf(stderr,"could not open %s\n",argv[1]); exit(1); } yyin = file; } yylex(); printf("%d %d %d\n",charCount, wordCount, lineCount); return 0; } • The user subroutines section
How to implement a scanner()? • We have to stop the yylex()when it recognizes a defined token. • Insert “return” at the end of your program • [a-zA-Z]+ { return 2; } • See scanner_example.l
%{ %} %% [\t ]+ /* ignore white space */ ; is | am | are | were | was | be | being | been | do | does | did | will | would | should | can | could | has | have | had | go { return 1; } [a-zA-Z]+ { return 2; } .|\n { /* normal default anyway */ } %% main() { int i; while ((i=yylex())!=0) { printf("return value is %d, token is %s\n", i,yytext); } printf("End of file\n"); }
How to implement multiple characters lookahead in lex? • Check lex_lookahead.l • DO10I=1,100 • DO10I=1.100