Download

1 / 25
250 likes | 409 Views
Trecul – Data Flow Processing using Hadoop and LLVM. David Blair. Agenda. Problem Statement Trecul User Level Overview Trecul Architecture and Design. Advertising Decision Solutions. The Akamai Advertising Network Full Funnel Approach Awareness Prospecting Remarketing

E N D
Trecul – Data Flow Processing using Hadoop and LLVM • David Blair
Agenda • Problem Statement • TreculUser Level Overview • Trecul Architecture and Design
Advertising Decision Solutions • The Akamai Advertising Network • Full Funnel Approach • Awareness • Prospecting • Remarketing • Data Coop • 500+ sites browse & buy data • 300m monthly active cookies • Data Collection • 600 Million Site Events per Day • 50 Million Impressions per Day
Making Data into Decisions Ad Serving and Data Collection Modeling Scoring Data Coop Attribution Billing
Problem Statement • Had a working system but much pain • Commerical Parallel RDBMS, MySQL, Perl • Functional Requirements • Natural partitioning key = User/Cookie • Most processing aligns with that key • Handling of structured data only (e.g. no text analysis) • Non Functional Requirements • Fault Tolerance • Performance/Cost • Must be deployable in Akamai network • Reach Goals • Ease of use • Ad-hoc queries
Hadoop to Rescue (Almost) • HDFS • Good enough performance • Hooks to customize data placement • Handles most single node failures • Map Reduce • Cluster and resource management • Partition parallel computing model • Shuffles for cases when we need it • Handles most single node failures • Mystery guest • Ad-hoc Java – anti-pattern • Hive or Pig – too slow for our needs • or …
Anatomy of a Trecul Program g = generate[output="'Hello World!' AS greeting", numRecords=1]; p = print[limit=10]; g -> p; d = devNull[]; p -> d;
Anatomy of a TreculProgram : Operators g =generate[output="'Hello World!' AS greeting", numRecords=1]; p = print[limit=10]; g -> p; d = devNull[]; p -> d;
Anatomy of a TreculProgram : Arguments g = generate[output="'Hello World!' AS greeting", numRecords=1]; p = print[limit=10]; g -> p; d = devNull[]; p -> d;
Anatomy of a TreculProgram : Arrows g = generate[output="'Hello World!' AS greeting", numRecords=1]; p = print[limit=10]; g-> p; d = devNull[]; p -> d;
Anatomy of a Trecul Program $ ads-df --file - << EOF > g = generate[output="'Hello World!' AS greeting", > numRecords=1]; > p = print[limit=10]; > g -> p; > d = devNull[]; > p -> d; > EOF Hello World! Streaming pipes & filters without threads or processes
Basic Trecul Map Reduce Program • m = map[format=“cre_date DATETIME, event_id INTEGER, greeting VARCHAR”]; • e = emit[key=“greeting”]; • g -> e; • r = reduce[]; • gb = group_by[sortKey=“greeting”, • output=“greeting, SUM(1) AS greeting_cnt”]; • r -> gb; • w = write[file=“hdfs://default:0/users/dblair/demo_mr”]; • gb-> w; • $ ads-df –-map map.tql –-reduce reduce.tql –-input /my/test/data
Example with branchingand merging group • r = read[file=“hdfs://default:0/foo”, • format=“akid CHAR(22), cre_date DATETIME, coop_id INTEGER”]; • c = copy[output=“akid”, output=“input.*”]; • r -> c; • g = group_by[sortKey=“akid”, • output=“akid, SUM(1) AS activity”]; • c -> g; • j = merge_join[leftKey=“akid”, rightKey=“akid”, where=“activity > 5”, output=“l.*”]; • c -> j; • g -> j; copy join read
Scope of Trecul • Aggregation • Hash Group By • Sort Group By • Hybrid Group By • Sort Running Total • Filter • Sort • Exernal sort • Supports presorted keys • Map Reduce Integration • Emit • Map • Reduce • MySQL Integration • Select • Insert • File IO • Read, write • Simple parser/printer • Local filesystem and HDFS • Bucketed mode • Merging • Hash Join & Merge Join • Inner, outer, semi, anti semi • Union All • Sorted Union • Switch Transformation Generate, Copy
Limits of Trecul • Relational Data • Primitive Types : INTEGER, BIGINT, DOUBLE PRECISION, DECIMAL, DATE, DATETIME, CHAR(N), VARCHAR • No container types : list, set, bag, map • No Unicode, no code page support • No Metadata management • ADS has special operators that encapsulate specific datasets • Formats may be stored in files • No optimizer • We write very complex queries • No barrier to construction of optimal plans • Predictable performance in production
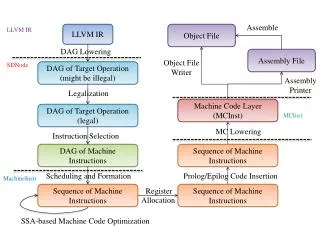
Trecul Architecture • C++, Linux • Expression Language • Parser • Semantic Analysis • Codegen • Operator Library • Dataflow Runtime • OS Services • Graph Semantic Analysis • Operator Scheduler • Harness Integration • Single Machine • Hadoop • MPI (experimental)
Trecul and LLVM • LLVM • Open source compiler and toolchain project • Used extensively by Apple and Google • Supports static and JIT compilation • http://www.llvm.org • TreculExpresssions • Transforms, predicates, aggregates • Expressions & data structures compiled using LLVM • Operators are parameterized with expressions • Most operator code + scheduler etc. statically compiled
Trecul Expression Compilation • R = read[file=“/home/dblair/example”, • format=“a INTEGER, b BIGINT, c DATE”]; • F = filter[where=“c >= CAST(‘2012-01-01’ AS DATE)”]; • R -> F; • G = group_by[hashKey=“c”, output=“c, SUM(a*b) AS s”]; • F -> G; • struct _R { int32_t a; int64_t b; date c; }; • Note: The use of pseudo-C is for illustration only; we transform Trecul directly to LLVM IR and then to machine code.
Trecul Expression Compilation • R = read[file=“/home/dblair/example”, • format=“a INTEGER, b BIGINT, c DATE”]; • F = filter[where=“c >= CAST(‘2012-01-01’ AS DATE)”]; • R -> F; • G = group_by[hashKey=“c”, output=“c, SUM(a*b) AS s”]; • F -> G; • struct _R { int32_t a; int64_t b; date c; }; • bool _F(_R * rec) { return rec->c >= date(1,1,2012); }
Trecul Expression Compilation • R = read[file=“/home/dblair/example”, • format=“a INTEGER, b BIGINT, c DATE”]; • F = filter[where=“c >= CAST(‘2012-01-01’ AS DATE)”]; • R -> F; • G = group_by[hashKey=“c”, output=“c, SUM(a*b) AS s”]; • F -> G; • struct _R { int32_t a; int64_t b; date c; }; • bool _F(_R * rec) { return rec->c >= date(1,1,2012); } • struct_G {date c; int64_t s; }; • void _G_init(_G * out, _R * in) { out->c = in->c; out->s = 0LL; } • void _G_upd(_G * out, _R * in) { out->s += in->a*in->b; }
Integration with Hadoop Executor Task JVM HDFS … Query Hadoop Pipes Compiler Executor Task JVM
Performance Testing • All tests performed on 82-node Hadoop cluster • 16 GB memory • 1 x 4 code SMT Xeon • 2 x 2TB 7200 RPM SATA disks • Two datasets in use • Site Events : cookie sorted; 2048 buckets; 640 GB; 100B rows • Impressions : cookie sorted; 2048 buckets; 700 GB; 17B rows • Buckets gzip compressed • Running Hadoop 0.21 and Hive 0.9.0 • Had to implement shim layer to get Hive to run on 0.21
Thanks! • https://github.com/akamai-tech/trecul