Download

1 / 15
150 likes | 264 Views
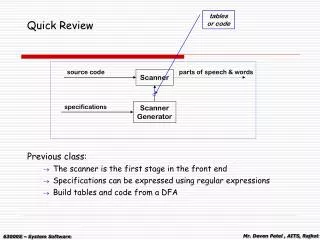
Quick Review of Apr 17 material. Multiple-Key Access There are good and bad ways to run queries on multiple single keys Indices on Multiple Attributes Combining two keys into a single concatenated attribute Grid files crude array with one dimension and linear scale for each attribute

E N D
Quick Review of Apr 17 material • Multiple-Key Access • There are good and bad ways to run queries on multiple single keys • Indices on Multiple Attributes • Combining two keys into a single concatenated attribute • Grid files • crude array with one dimension and linear scale for each attribute • more than one cell may point to a given bucket of values • array grid may be dynamically resized during use • Other alternatives are spatial databases: R-tree, quad-trees, k-d tree • Bitmap Indices • linear array of bits: bit j is set if tuple j has the attribute that this bitmap tracks (e.g., “Moonroof”: bit j is 1 if record j is a car with moonroof) • Queries are answered by combining several bitmaps using and, or, not
Today • HW #4: due Thursday April 24 (next class) • Questions: 12.11, 12.12, 12.13, 12.16 • No HW for next week • Today: • Start Chapter 13: Query Processing
Query Processing • SQL is good for humans, but not as an internal (machine) representation of how to calculate a result • Processing an SQL (or other) query requires these steps: • parsing and translation • turning the query into a useful internal representation in the extended relational algebra • optimization • manipulating the relational algebra query into the most efficient form (one that gets results the fastest) • evaluation • actually computing the results of the query
Query Processing Steps 1. parsing and translation • details of parsing are covered in other places (texts and courses on compilers). We’ve already covered SQL and relational algebra; translating between the two should be relatively familiar ground 2. optimization • This is the meat of chapter 13. How to figure out which plan, among many, is the best way to execute a query 3. evaluation • actually computing the results of the query is mostly mechanical (doesn’t require much cleverness) once a good plan is in place.
Query Processing Example • Initial query: select balance from account where balance<2500 • Two different relational algebra expressions could represent this query: • sel balance<2500(Pro balance(account)) • Pro balance( sel balance<2500(account)) • which choice is better? It depends upon metadata (data about the data) and what indices are available for use on these operations.
Query Processing Metadata • Cost parameters(some are easy to maintain; some are very hard -- this is statistical info maintained in the system’s catalog) • n(r ): number of tuples in relation r • b(r ): number of disk blocks containing tuples of relation r • s(r ): average size of a tuple of relation r • f(r ): blocking factor of r: how many tuples fit in a disk block • V(A,r): number of distinct values of attribute A in r. (V(A,r)=n(r ) if A is a candidate key) • SC(A,r): average selectivity cardinality factor for attribute A of r. Equivalent to n(r )/V(A,r). (1 if A is a key) • min(A,r): minimum value of attribute A in r • max(A,r): maximum value of attribute A in r
Query Processing Metadata (2) • Cost parameters are used in two important computations: • I/O cost of an operation • the size of the result • In the following examination we’ll find it useful to differentiate three important operations: • Selection (search) for equality (R.A1=c) • Selection (search) for inequality (R.A1>c) (range queries) • Projection on attribute A1
Selection for Equality (no indices) • Selection (search) for equality (R.A1=c) • cost (sequential search on a sorted relation) = b(r )/2 average unsuccessful b(r )/2 + SC(A1,r) -1 average successful • cost (binary search on a sorted relation) = log b(r ) average unsuccessful log b(r ) + SC(A1,r) -1 average successful • size of the result n(select(R.A1=c)) = SC(A1,r) = n(r )/V(A1,r)
Selection for Inequality (no indices) • Selection (search) for inequality (R.A1>c) • cost (file unsorted) = b(r ) • cost (file sorted on A1) = b(r )/2 + b(r )/2 (if we assume that half the tuples qualify) b(r ) in general (regardless of the number of tuples that qualify. Why?) • size of the result = depends upon the query; unpredictable
Projection on A1 • Projection on attribute A1 • cost = b(r ) • size of the result n(Pro(R,A1)) = V(A1,r)
Selection (Indexed Scan) for Equality Primary Index on key: cost = (height+1) unsuccessful cost = (height+1) +1 successful Primary (clustering) Index on non-key: cost = (height+1) + SC(A1,r)/f(r ) all tuples with the same value are clustered Secondary Index cost = (height+1) + SC(A1,r) tuples with the same value are scattered
Selection (Indexed Scan) for Inequality Primary Index on key: search for first value and then pick tuples >= value cost = (height+1) +1+ size of the result (in disk pages) = height+2 + n(r ) * (max(A,r)-c)/(max(A,r)-min(A,r))/f(r ) Primary (clustering) Index on non-key: cost as above (all tuples with the same value are clustered) Secondary (non-clustering) Index cost = (height+1) +B-treeLeaves/2 + size of result (in tuples) = height+1 + B-treeLeaves/2 + n(r ) * (max(A,r)-c)/(max(A,r)-min(A,r))
Complex Selections • Conjunction (select where theta1 and theta2) (s1 = # of tuples satisfying selection condition theta1) combined SC = (s1/n(r )) * (s2/n(r )) = s1*s2/n(r )2 assuming independence of predicates • Disjunction (select where theta1 or theta2) combined SC = 1 - (1 - s1/n(r )) * (1 - s2/n(r )) = s1/n(r )) + s2/n(r ) - s1*s2/n(r )2 • Negation (select where not theta1) n(! Theta1) = n(r ) - n(Theta1)
Complex Selections with Indices GOAL: apply the most restrictive condition first and combined use of multiple indices to reduce the intermediate results as early as possible • Why? No index will be available on intermediate results! • Conjunctive selection using one index B: • select using B and then apply remaining predicates on intermediate results • Conjunctive selection using a composite key index (R.A1, R.A2): • create a composite key or range from the query values and search directly (range search on the first attribute (MSB of the composite key) only) • Conjunctive selection using two indices B1 and B2: • search each separately and intersect the tuple identifiers (TIDs) • Disjunctive selection using two indices B1 and B2: • search each separately and union the tuple identifiers (TIDs)