Download

1 / 30
300 likes | 475 Views
Building A Highly Accurate Mandarin Speech Recognizer. Mei-Yuh Hwang, Gang Peng, Wen Wang (SRI), Arlo Faria (ICSI), Mari Ostendorf, etc. Outline. Mandarin-specific modules: Word segmentation. Tonal phonetic pronunciations. Pronunciation look-up tools.

E N D
Building A Highly Accurate Mandarin Speech Recognizer Mei-Yuh Hwang, Gang Peng, Wen Wang (SRI), Arlo Faria (ICSI), Mari Ostendorf, etc.
Outline • Mandarin-specific modules: • Word segmentation. • Tonal phonetic pronunciations. • Pronunciation look-up tools. • Linguistic questions for CART state clustering. • Pitch features. • Mandarin-optimized acoustic segmenter.
Outline • Language independent techniques: • MPE training. • fMPE feature transform. • MLP feature front end. • System combination. • Jan-08 system • Future
Word segmentation and lexicon • Started from BBN 64K lexicon (originally from LDC 44K lexicon) • /g/ssli/data/mandarin-bn/external-sites/ • Added 20K new entries (especially names) from various sources. • First-pass: Longest-first match (LFM) word segmentation • Selected most frequent 60K words as our decoding lexicon. • UW ÇBBN = 46.8K • UW \ BBN = 13.6K (阿扁,马英九) • BBN \ UW = 17.3K (狼狈为奸,心慌意乱,北京烤鸭)
Word segmentation and lexicon • Train 3-gram. Treat OOV = @reject@ = garbage. • Second-pass: Re-segment training text with ML word segmentation. • /homes/mhwang/src/ngramseg/wseg/ngram –order 1 –lm <DARPA n-gram> • Output depends on (1) algorithm, (2) lexicon. • 记者-从中-国-国家计划委员会-有关部门-获悉 • 记者-从-中国-国家计划委员会-有关部门-获悉 • Re-train 3-gram, 4-gram, 5-gram. • Very minor perplexity improvement. Character accuracy from 74.42% (LFM) to 75.01% (ML) by NTU.
Lexicon and Perplexity • 1.2B words of training text. • qLMn: quick (highly pruned) n-gram
Two Tonal Phone Sets • 70 tonal phones from BBN originally, using IBM main-vowel idea: • Split Mandarin Final into vowel+coda to increase parameter sharing. • bang /b a NG/ • ban /b a N/ • {n,N},{y,Y},{w,Y} for unique syllabification • Silence for pauses and rejfor noises/garbage/foreign. • Introducing diphthongs and neutral tones for BC 79 tonal phones
Phone-81: Diphthongs for BC • Add diphthongs (4x4=16) for fast speech and modeling longer triphone context. • Maintain unique syllabification. • Syllable ending W and Y not needed anymore.
Phone-81: Frequent Neutral Tones • Neutral tones more common in conversation. • Neutral tones were not modeled. The 3rd tone was used as replacement. • Add 3 neutral tones for frequent chars.
Phone-81: Special CI Phones • Filled pauses (hmm, ah) common in BC. Add two CI phones for them. • Add CI /V/ for English.
Phone-81: Simplification of Other Phones • Now 72+14+3+3=92 phones, too many triphones to model. • Merge similar phones to reduce #triphones. I2 was modeled by I1, now i2. • 92 – (4x3–1) = 81 phones.
Different Phone Sets Pruned trigram, SI nonCW-PLP ML, on dev07 Indeed different error behaviors --- good for system combo.
Pronunciation Look-up Tools • SRC=/g/ssli/data/mandarin-bn/scripts/pron • $SRC/wlookup.pl: Look up pronunciations from a word dictionary, for Chinese and/or English words. • $SRC/eng2bbn.pl: Look up English word pronunciations in Mandarin phone set. • $SRC/standarnd-all.sc: P72 Single-char lexicon. First pronunciation = most common • $SRC/sc2bbn.pl: Look up Chinese word pronunciation from individual characters. • $SRC/pconvert.pl: convert a dict from one phone set to another • $SRC/RWTH/: RWTH-70 phone set (3rd phone set)
Pitch Features • Get_f0 to compute pitch for voiced segments. • Pass to graphtrack to reduce pitch halving/doubling problem • SPLINE interpolation for unvoiced regions. • Log, D, DD
silence noise Start / null End / null speech silence silence silence noise noise noise Start Start Start / / / null null null End End End / / / null null null speech speech speech Acoustic segmentation • Former segmenter, inherited from the English system, caused high deletion errors. It mis-classified some speech segments as noises. • Speech segment min duration 18*30=540ms=0.5s
noise silence Foreign Start / null End / null Mandarin 1 Mandarin 2 New Acoustic Segmenter • Allow shorter speech duration • Model Mandarin vs. Foreign (English) separately.
Improved Acoustic Segmentation Pruned trigram, SI nonCW-MLP MPE, on Eval06
Two Sets of Acoustic Models • MLP-model: • MFCC+pitch+MLP (32-dim) = 74-dim • CW Triphones with SD SAT feature transform • MPE trained • P72 • PLP-model: • PLP+pitch = 32-dim • CW Triphones with SD SAT feature transform • Followed by fMPE SI feature transform • MPE trained • P81
MLP Phoneme Posterior Features • One MLP to compute Tandem features with pitch+PLP input. 71 output units. • 20 MLPs to compute HATs features with 19 critical bands. 71 output units. • Combine Tandem and HATs posterior vectors into one 71-dim vector, valued [0..1]. • PCA(Log(71)) 32 • MFCC + pitch + MLP = 74-dim
(42x9)x15000x71 PLP (39x9) Pitch (3x9) Tandem Features [T1,T2,…,T71] • Input: 9 frames of PLP+pitch
MLP and Pitch Features nonCW ML, Hub4 Training, MLLR, LM2 on Eval04
HATS Features [H1,H2,…,H71] 51x60x71 (60*19)x8000x71 E1 E2 … E19
PLP Models with fMPE Transform • PLP model with fMPE transform to compete with MLP model. • Smaller ML-trained Gaussian posterior model: 3500x32 CW+SAT • 5 Neighboring frames of Gaussian posteriors. • M is 42 x (3500*32*5), ht is (3500*32*5)x1. • Ref: Zheng ICASSP 07 paper
Jan 08: RWTH Improvements • Using RWTH-70 phone set, converted from UW dictionary. • Using UW-ICSI MLP features. • On Dev07
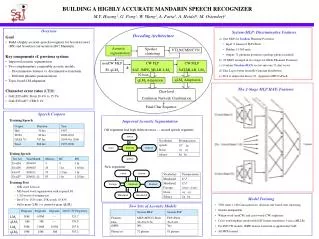
Jan-2008: Decoding Architecture • Manual acoustic segmentation. • Removing sub-segments. • Removing the ending of the first utterance when partially overlapped. • Gender-ID per utternace. • Auto speaker clustering per gender. • VTLN per speaker. • CMN/CVN per utterance.
Jan-2008 Decoding Architecture SI MLP nonCW qLM3 Aachen PLP-SA MLP-SA PLP CW SAT+fMPE MLLR, LM3 MLP CW SAT MLLR, LM3 Confusion Network Combination
Re-Test: Jan 2008 • Dev07 • PLP-SA-1: 10.2% • PLP-SA-2: 9.9% (very competitive to MLP-model after adaptation) • MLP-SA-2: 9.8% • {PLP-SA-2, MLP-SA-2}: 9.5% • RWTH: 9.9% (more sub errors, fewer del errors) • {RWTH, PLP-SA-2, MLP-SA-2}: 9.2% • Eval07-retest: 8.1% 7.3%
Future Work • Putting all words together, re-do word segmentation and re-select decoding lexicon. • Auto create new words using point-wise mutual information: • PMI(w1,w2) = log P(w1,w2)/{P(w1)P(w2)} • LM adaptation • Finer topics • Names • Has to coordinate with MT/NE