Download
1 / 26
260 likes | 388 Views
Matching names in parallel. T. Hickey Access 2006 2006 October. Virtual International Authority File. Link national authority records Build on their authority work Move towards universal bibliographic control Allow national or regional variations in authorized forms to co-exist

E N D
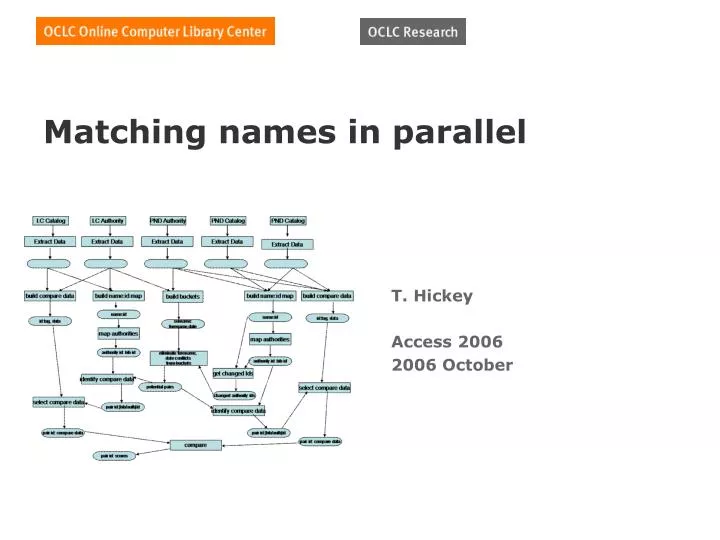
Matching names in parallel T. Hickey Access 2006 2006 October
Virtual International Authority File • Link national authority records • Build on their authority work • Move towards universal bibliographic control • Allow national or regional variations in authorized forms to co-exist • Support needs for variations in preferred language, script, and spelling • 10 million WorldCat records in non-English metadata
Matching Variations In the LCNAF and PND authority files: • Same name, same person • Same name, different people • Different names, same person • Missing person in one file
Different Same Name People Two Different People – One Name Adams, Mike • PND: a golfer • LCNAF: author of a Beatles collector's guide
Different Same Person Names One Person – Two Names • LCNAF: Morel, Pierre • PND: Morellus, Petrus
Bibliographic Record Enhanced Authority Derived Authority Authority Record Enhancing the Authorities
Strong Matching Attributes • A work (title) in common • Common control numbers (ISBN, ISSN, or LCCN) • Exact birth and death year • Joint authors • Name as subject
Weaker Attributes • Only one of birth/death date(s) (allows some variation) • Subject area of works (two levels) • Format (books, films, musical scores, etc.) • Language • Publisher • Partial title match • Date of publication • Country • Role (author, illustrator, composer, etc.) • Format (books, films, musical scores, etc.)
Computing it • Standard approach • Generate keys and data • Load information into a database • Index it • Extract fields needed • Map/Reduce approach • Split the database up • Run parallel jobs • Bring information together via map/reduce • Assemble information in stages
Map/Reduce • Two stages • Map • Read in source file (e.g. MARC-21) • Write out key + data • Reduce • Read in array of data for each unique key • Write out key + data
Overview of MapReduce Source: Dean & Ghemawat (Google)
Our Implementation • Written in Python • Uses ssh and XML-RPC for control and communication • Map/Reduce seems to add ~ 10% overhead • Ran an earlier implementation on a 48 cpu cluster • Current VIAF cluster is a 12 cpu cluster on 4 nodes • Running Linux and 64-bit Python
VIAF Matching Code • 17 modules • 1,100 lines of code • Plus • 600 lines configuration • 2,755 lines of tables embedded in code
build compare data build compare data build name:id map build name:id map name:id id:tag, data name:id id:tag, data map authorities map authorities authority id: bib id authority id: bib id PND Catalog PND Catalog LC Catalog LC Authority PND Authority Extract Data Extract Data Extract Data Extract Data Extract Data VIAF Data Flow build buckets surname: forename,date eliminate forename, date conflicts from buckets get changed Ids identify compare data potential pairs select compare data changed authority ids select compare data pair id:[bib/auth]id identify compare data pair id: compare data pair id:[bib/auth]id pair id: compare data compare pair id: scores
WorldCat Identities • Bring together all of WorldCat’s information about people • Name(s) • Works by and about • Subjects • Dates • Fiction/non-fiction • Roles • Co-authors • Add links • Wikipedia • Authority files
Statistics • Nearly 19 million different ‘identities’ in WorldCat • 80 million (nominally) controlled headings • The WorldCat Identity code is ~800 lines of Python in 4 modules (plus XSLT, CSS, etc.)
Identities Data Flow Cover Art WorldCat FRBR Audience Stage 1 NameInfo Citation Authorities Stage 3 Stage 2 NameInfo Citations Stage 4 Identities Wikipedia
Identities Stage 1Extract Data From WorldCat • Input: WorldCat (MARC-21) • Map output: • NameKey <nameInfo> • WorkID <citation> • Reduce output: • WorkID <best citation> • NameKey <cumulative nameInfo>
Identities Stage 2Extract Data From Authorities • Input: NACO Authorities file (MARC-21) • Map output • NameKey <authorityInfo> • XTos • XFroms • Reduce output • NameKey <authorityInfo, symetric xrefs>
Identities Stage 3Connect Citations with Names • Input • Stage 1 output • WorkID <by/about citation>’s • NameKey <nameInfo> • Map output • NameKey <nameInfo> • NameKey <topCitations>
Identities Stage 4Create Identities • Input • Authority info from stage 2 • Merged name info from stage 3 • Merged citations from stage 3 • Map output • Pass through • Reduce output • Pnkey <Identity Record>
Schedules • Identities • Up this year? • VIAF • Reload, rematch this year • Public service up early 2007
Conclusions • Our merged files (e.g. WorldCat) are really quite large • More processing power opens up new ways of manipulating and looking at our data • Parallel processing is the only way to obtain the cycles needed • Map-Reduce is an attractive way to do parallel processing • Forces decomposition • Scales well • Opens up new possibilities
Thank you T. Hickey VIAF.org http://errol.oclc.org/laf/n82-54463.html Access 2006 2006 October
















