Download

1 / 22
220 likes | 341 Views
K -MST -based clustering . Caiming Zhong Pasi Franti. Outline. Minimum spanning tree (MST) MST-based clustering K -MST K -MST-based clustering Fast approximate MST. MST MST-based clustering K -MST K -MST-based clustering Fast approximate MST. Minimum Spanning Tree. Spanning tree.

E N D
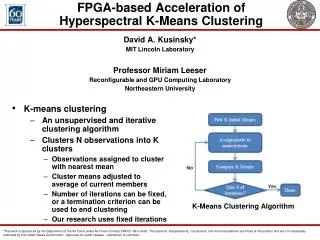
K-MST -based clustering Caiming Zhong Pasi Franti
Outline • Minimum spanning tree (MST) • MST-based clustering • K-MST • K-MST-based clustering • Fast approximate MST MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
Minimum Spanning Tree • Spanning tree Given graph MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST Spanning tree Non-Spanning tree
Minimum Spanning Tree • Minimize the sum of weights (Kruskal, Prim’s Algorithm) MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST Given graph G=(V,E) MST T
MST-based clustering • The most used Method1: removing long MST-edges MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
MST-based clustering • Removing long MST-edges doesn’t always work MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
MST-based clustering • The most used Method2: edge inconsistent Tree edge AB, whose weight W(AB) is significantly larger than the average of nearby edge weights on both sides of the edge AB, should be deleted. MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
K-MST • What is K-MST? • Let G = (V,E) denote the complete graph • Let MST1 denote the MST of G, and it is computed as MST1 = mst(V, E). • Then, MST2 denote the second round of MST of G, MST2 = mst(V, E- MST1). • MSTk = mst(V, E- MST1-…-MSTk-1). MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
K-MST • K-MST-based graph MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
K-MST • Typical clustering problems • Separated problems and touching problems. • Separated problems includes distance-separated problems and density-separated problems. MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
K-MST-based clustering • Definition of edge weight for separated problems MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
Three good features: (1) Weights of inter-cluster edges are quite larger than those of intra-cluster edges. (2) The inter-cluster edges are approximately equally distributed to T1 and T2. (3) Except inter- cluster edges, most of edges with large weights come from T2.
MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
K-MST-based clustering • Touching problems MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
Partition(cut1) and Partition(cut3) are similar ; Partition(cut2) and Partition(cut3) are similar .
Fast approximate MST (FAMST) • Traditional MST algorithms take O(N2) time, not favored by large data sets. • In practical application, generally FAMST has as same result as exact MST • Find a FAMST in O(N1.55) MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
Fast approximate MST (FAMST) • Scheme: Divide-and-Conquer MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
Fast approximate MST (FAMST) • Performance MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST
MST MST-based clustering K-MST K-MST-based clustering Fast approximate MST