Download

1 / 19
190 likes | 283 Views
Implementing Associative Functions for ClearSpeed. Dr. Brian Sumner ClearSpeed Training Session Random Comments. Comments . Dr Brian Sumner used portions of the ClearSpeed Training slides, but also covered material not in the slides

E N D
Implementing Associative Functions for ClearSpeed Dr. Brian Sumner ClearSpeed Training Session Random Comments
Comments • Dr Brian Sumner used portions of the ClearSpeed Training slides, but also covered material not in the slides • Dr. Sumner projected online manuals on screen when covering material not in the slides. • My handwritten notes were based on the presentations that Dr. Sumner made, so material referenced may not always be in the slides. • I tried to identify the online references Dr. Sumner used, when possible. • More information may be available in my or Shannon’s handwritten slides on some topics.
Assembly Inserts • Allow low level instructions or highly optimized assembly routines to be targeted from Cn source code. • Uses simple passing of parameters between Cn and assembly code • Avoids paying function call costs, as assembly is executed inline. • Allows user defined assembler macro to be used as customized instruction.
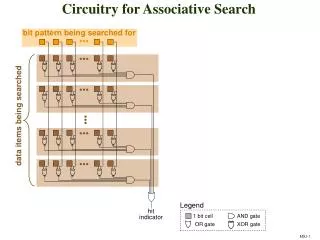
Reductions • Sum, product, min, max • Released reduction source • Not sure where these are located • Inefficient to go back to host. • Use swazzle and have one PE see all pieces. • Then have them to bring back into mono. • Mentioned async_function.h (??) and recommended bringing it into editor to see its code.
My Second Day Notes • On second day, Dr. Sumner seemed to focus in AM on implementing assoc. opns • Initially focused on some new instructions • Ref: CSX 600 Instruction Set Reference Manual mentioned initially • Move & Cast Instructions • mov • Integer divide expensive • Some cost a lot • Integer division can be replaced by multiples
Second Day - Instructions • Broadcast: • Mono register to poly broadcast • 2nd Method: Consolidated PIO • Breakover point 16-32 bytes • Shifts • Stick with constant shifts if possible • Bit operations usual. If can stick to smallest size on poly, come out better. • Compare mono value in loop, put in poly value and save time.
Second Day - Instructions (cont-2) • Use ANY or ALL mono-results • If all (cond), go to some other place • Back path – mono slower • Any/All are mono • Like to run mono ahead of poly since slower • ANY/ALL are not cheap instructions • Aside: Go to installation directory • Go to debugger • See asm code for ALL • asm directory has INC file
Second Day - Instructions (cont-3) • Code for “any.enable” • AEO means “All Enables Off” • Takes time to drain poly; must wait on semaphore • End of sqazzle movement can go into mono. • result_constant.ins gives some timings • andif.lt instruction • Used to turn on/off PE • if.cry instruction looks at status register
Second Day - Instructions (cont-4) • Lots of “if. “ commands • One cycle • Enable stack • Else – toggle the least significant bit of enable stack • Can branch on any predicate bit • pred.set • Pred.not
Second Day – Instructions (cont-4) • branch j.if.pred commands • Some nice instructions with low cycles • Load and store instructions • Can load 1-16 bits in powers of 2 in 6 cycles • Fld (poly with offset) • Forced. Works even if PE disabled • ID (mono with offset)
Second Day – Instructions (cont-5) • Swazzle Instruction • Swazzle.low to high • Swazzle.swap.odd.up • This lets you do reductions pretty easy • Swazzle.lowtohighX4 • Saves 3 cycles over x2 choice • Look at what is in library • Swazzle_functions directory • Look for swazzle_up (almost anything)
Building on Previous Background • Do “cd src” • cs_reduction • Use vi editor to look at instruction’s code • asm poly float • Just a move gets you the max • asm_poly float_cs_min(poly float x, poly float y) • Asm poly float_cs_swazzle_down_float • Next, look at sum reduce • mono float_cs_reduce_mono_sum_float(poly float a)
Building on Previous Background -2 • Use swap_odd_up to move data past • Could improve using swazzlex4 • Can build all partial sums as some PEs see everything that goes by. • Mono float_cs_reduce_more_max_float (poly float a) • Location (???) • Location/3.0-1.1 ?? /src/ • cs_reduction • A working version • Inline assembler
PickOne • Can implement using a min reduction • Find bit that is turned on • Can concatenate PE number with bit number. • Reddaway code – several calls to ANY • Concatenates PE number with bit number • asm poly float_cs_min(poly float x, poly float y) • Play with above code • Could also use mono_cs_reduce_mono_sum_float(poly float a) • Also play with this code
Miscellaneous Instructions • penum • Sets dst to be the PE number of the PE • Gets PE number that you are running on • thread.get • Normally not programming but one thread use. • cycles.get • Sets dst to be the cycle count of the processor • May need to wait for poly unit to have stopped • Mono can get way ahead of poly.
Miscellaneous Instructions - 2 • enable.get • Forced function – always run. • Sets dst to be enable status of PE, regardless of enable status • Strongly recommend using more than one thread, so recommend not use this. • Mutex.start • During multex section, no other thread can activate • Can keep I/O from interrupting.
End of Focus on Assoc. Opns • Dr Sumner went back into training slides at this point. To see where this fits in, the next two topics were • ClearSpeed Vector Math Library • Clear Speed Visual Profiler • However, some items mentioned seemed to still be related to implementing assoc. operations.
Possibly Related Comments • Have to initialize vector math library operations each time used. Could avoid by using a global variable. • Before compiling, source a file in install directory, e.g., using bashrc or cshrc. • More comments in my notes, if needed • ANY or ALL: Simulator 1 may be a bit faster
Possibly Related Comments -2 • Inline assemby function – must be careful not to abuse registers. • Performance evaluation: • Start with a paper estimate of how long it should take • FLOP rates • IPO rates • Work out by hand • Use cycle counter to tell if this is wrong. • Tells what cycle operation executed but not when poly fcns execute • Additional related comments on some topics in my notes, if needed.