Download

1 / 43
430 likes | 563 Views
XJoin: A Reactively-Scheduled Pipelined Join Operator. IEEE Bulletin, 2000 by Tolga Urhan and Michael J. Franklin. Goal of XJoin. Efficiently evaluate equi-join in online query processing over distributed data sources Optimization objectives: Having small memory footprint

E N D
XJoin: A Reactively-Scheduled Pipelined Join Operator IEEE Bulletin, 2000 by Tolga Urhan and Michael J. Franklin CS561 - XJoin
Goal of XJoin • Efficiently evaluate equi-join in online query processing over distributed data sources • Optimization objectives: • Having small memory footprint • Fast initial result delivery • Hiding intermittent delays in data arrival CS561 - XJoin
Outline • Hash Join History • Motivation of XJoin • Challenges in Developing XJoin • Three Stages of XJoin • Preventing Duplicates • Experimental Results • Conclusion CS561 - XJoin
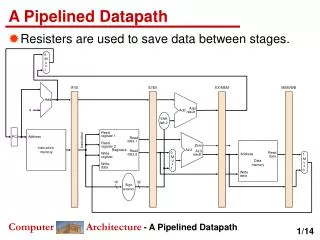
S tuple 1 key2 key1 key3 key4 Key5 R tuples R tuples R tuples R tuples R tuples S tuple 2 S tuple 3 S tuple 4 S tuple 5 Classic Hash Join • 2-phase: build and probe • Only one table is hashed in memory 2. Probe 1. Build CS561 - XJoin
Memory Disk Bucket i R tuples S tuple 1 Bucket n R tuples Bucket i+1 R tuples S tuple 2 Bucket n+1 R tuples Bucket i+2 R tuples S tuple 3 Bucket n+2 R tuples Bucket … R tuples S tuple 4 Bucket … R tuples Bucket j-1 R tuples S tuple … Bucket m-1 R tuples Bucket j R tuples Bucket m R tuples Hybrid Hash Join • One table is hashed both to disk and memory (partitions) • G. Graefe, “Query Evaluation Techniques for Large Databases”. ACM 1993. CS561 - XJoin
R tuple S tuple R tuple S tuple Key i Key n S tuples R tuples Key i+1 Key n+1 R tuples S tuples PROBE Key n+2 Key i+2 R tuples S tuples Key … Key … R tuples S tuples PROBE Key j-1 Key m-1 R tuples S tuples Key m Key j R tuples S tuples BUILD BUILD Symmetric Hash Join (Pipelined) • Both tables are hashed (both kept in main memory only) • A. Wilschut, P. M.G. Apers, “Dataflow Query Execution in a Parallel Main-Memory Environment”, DPD 1991. OUTPUT Source S CS561 - XJoin Source R
Problems of SHJ: • Rather memory intensive • Won’t work for large input streams. • Won’t allow for many joins to be processed in a pipeline (or even in parallel). CS561 - XJoin
New Problems in Online Query Processing over Distributed Data Sources • Unpredictable data access due to link congestion, load balances, etc. • Three classes of delays • Initial Delay: first tuple arrives from remote source more slowly than usual • Slow Delivery: data arrives at a constant, but slower than expected rate • Bursty Arrival: data arrives in a fluctuating manner CS561 - XJoin
Question: Why are delays undesirable? • Prolongs the time for first output • Slows the processing if wait for data to first be there before acting • If too fast, you want to avoid loosing any data • Waste time if you sit idle while no data is coming • Unpredictable, one single strategy won’t work CS561 - XJoin
Motivation of XJoin • Produce results incrementally when available • Tuples returned as soon as produced • Exploit available main memory as long as possible • Favor main-memory join when possible • Allow progress to be made when one or more sources experience delays by: • Background processing performed on previously received tuples so results are produced even when both inputs are stalled CS561 - XJoin
XJoin Design • Tuples are stored in partitions (Hash Join): • A memory-resident (m-r) portion • A disk-resident (d-r) portion CS561 - XJoin
Memory-resident partitions of source A Memory-resident partitions of source B 1 1 n n 1 k n . . . . . . . . . . . . . . . . . . M E M O R Y flush D I S K Tuple B Tuple A hash(Tuple A) = 1 hash(Tuple B) = n 1 . . . n 1 k n . . . . . . SOURCE-A Disk-residentpartitions of source A Disk-residentpartitions of source B SOURCE-B CS561 - XJoin
Challenges in Developing XJoin • Manage flow of tuples between memory and secondary storage (when and how to do it) • Control background processing when inputs are delayed (reactive scheduling idea) • Provide both quick initial result as well as good overall throughput • Ensure the full answer is produced • Ensure duplicate tuples are not produced CS561 - XJoin
XJoin Stages • XJoin proceeds in 3 stages (separate threads) M : M M : D D : D CS561 - XJoin
Output Partitions of source A Partitions of source B j i j i . . . . . . . . . . . . . . . . . . Insert Insert Probe Probe Tuple A Tuple B hash(record A) = i hash(record B) = j 1st Stage: Memory-to-Memory Join M E M O R Y SOURCE-A SOURCE-B CS561 - XJoin
1st Stage: Memory-to-Memory Join • Join processing continues as long as: • Memory permits, and • One of the inputs is producing tuples • If memory is full, one partition is picked to be flushed to disk and appended to end of disk-resident portion • If no new input, then stage 1 is blocked and stage 2 starts CS561 - XJoin
Why Stage 1? • In-memory operations are much faster and cheaper than on-disk operations • Thus this guarantees that results are produced as soon as possible. CS561 - XJoin
Question: • What does the 2nd Stage do? • When does the 2nd Stage start? • Hint: • What occurs when data input (tuples) are too large for memory? • Answer: • The 2nd Stage joins Memory-to-Disk • Occurs when both inputs are blocking CS561 - XJoin
Output i Partitions of source A Partitions of source B . . . . . . . . . . . . . . i . . . . . . . . . . . . . . M E M O R Y DPiA MPiB i D I S K i . . . . . . . . . . . . . . . . . . . . Partitions of source A Partitions of source B Stage 2 CS561 - XJoin
2nd Stage: Memory-to-Disk Join • Activated when 1st Stage is blocked • Performs 3 steps: • Choose partition according to throughput and size of partition from one source • Use tuples from d-r portion to probe m-r portion of other source and output matches, until d-r completely processed • Check if either input resumed producing tuples. If yes, resume 1st Stage. If no, choose another d-r portion and continue 2nd Stage. CS561 - XJoin
Controlling 2nd Stage • Cost of 2nd Stage is hidden when both inputs experience delays • Tradeoffs ? • What are the benefits of using second stage? • Produces results when input sources are stalled • Allows varying input rates • What is the disadvantage? • The second stage must complete a d-r portion before checking for new input (overhead) • To address tradeoff, use an activation threshold: • Pick a partition likely to produce many tuples right now CS561 - XJoin
3rd Stage: Disk-to-Disk Join • Clean-up stage • Assume that all data for both inputs has arrived • Assume that 1st and 2nd stage have completed • Why is this step necessary? • Completeness of answer: make sure that all result tuples are being produced. • Reason: some tuples in disk-resident portions may not have had chance to join each other. CS561 - XJoin
Preventing Duplicates • When could duplicates be produced? • Duplicates could be produced in both 2nd and 3rd stages which may perform overlapping work. • How to address it? • XJoin prevents duplicates with timestamps. • When address this? • During processing when trying to join two tuples. CS561 - XJoin
Time Stamping : Part 1 • 2 fields are added to each tuple: • Arrival TimeStamp (ATS) • Indicates time when tuple first arrived in memory • Departure TimeStamp (DTS) • Indicates time when tuple was flushed to disk • [ATS, DTS] indicates when tuple was in memory • When did two tuples get joined in 1st state? • If Tuple A’s DTS is within Tuple B’s [ATS, DTS] • Tuples that meet this overlap condition are not considered for joining at 2nd or 3rd stage CS561 - XJoin
ATS ATS DTS DTS Tuple A 102 234 Tuple A 102 234 Non-Overlapping Overlapping Tuple B2 Tuple B1 348 178 198 601 Detecting Tuples Joined in 1st Stage • Tuples joined in first stage • B1 arrived after A and before A was flushed to disk • Tuples not joined in first stage • B2 arrived after A and after A was flushed to disk CS561 - XJoin
Time Stamping : Part 2 • For each partition, keep track of : • ProbeTS: time when a 2nd stage probe was done • DTSlast: the DTS of last tuple of disk-resident portion • Several such probes may occur • Keep an ordered history of such probe descriptors • Meaning : • All tuples before and including at time DTSlast were joined in stage 2 with all tuples in main memory at time ProbeTS CS561 - XJoin
Detecting Tuples Joined in 2nd stage Partition 2 DTSlast ProbeTS ATS DTS Tuple A 100 200 20 340 350 550 700 900 overlap Partition 2 Tuple B 500 600 100 300 800 900 ATS DTS History list for corresponding partition. All A tuples in Partition 2 up to DTSlast 350, were joined with m-r tuples that arrived before Partition 2’s ProbeTS. CS561 - XJoin
Experiments • HHJ (Hybrid Hash Join) • XJoin (with 2nd stage and with caching) • XJoin (without 2nd stage) • XJoin (with aggressive usage of 2nd stage) CS561 - XJoin
Case 1: Slow NetworkBoth Sources Are Slow CS561 - XJoin
Case 1: Slow NetworkBoth Sources Are Slow (Bursty) • XJoin improves delivery time of initial answers -> interactive performance • The reactive background processing is an effective solution to exploit intermittent delays to keep continued output rates • Shows that 2nd stage is very useful if there is time for it CS561 - XJoin
Case 2: Fast NetworkBoth Sources Are Fast CS561 - XJoin
Case 2: Fast NetworkBoth Sources Are Fast • All XJoin variants deliver initial results earlier. • XJoin also can deliver the overall result in equal time to HHJ • HHJ delivers the 2nd half of the result faster than XJoin. • 2nd stage cannot be used too aggressively if new data is coming in continuously CS561 - XJoin
Conclusion • Can be conservative on space (small footprint) • Can produce initial result as early as possible • Can hide intermittent data delays • Can be used in conjunction with online query processing to manage data streams (limited) CS561 - XJoin
How to Further Optimize XJoin? • Resuming Stage 1 as soon as data arrives • Removing no-longer-joining tuples in timely manner • Other ideas ? … CS561 - XJoin
References • Urhan, Tolga and Franklin, Michael J. “XJoin: Getting Fast Answers From Slow and Bursty Networks.” • Urhan, Tolga and Franklin, Michael J. “XJoin: A Reactively-Scheduled Pipelined Join Operator.” • Hellerstein, Franklin, Chandrasekaran, Deshpande, Hildrum, Madden, Raman, and Shah. “Adaptive Query Processing: Technology in Evolution”. IEEE Data Engineering Bulletin, 2000. • Hellerstein and Avnur, Ron. “Eddies: Continuously Adaptive Query Processing.” • Babu and Wisdom, Jennifer. “Continuous Queries Over Data Streams”. CS561 - XJoin
Stream: New Query Context • Challenges faced by XJoin • Potentially unbounded growing join state • Indefinite delay of some join results • Solutions • Exploit semantic constraints to remove no-longer-joining data in timely manner • Constraints: • sliding window • punctuations CS561 - XJoin
Punctuation • Punctuation is predicate on stream elements that evaluates to false for every element followingthe punctuation. ID Name Age no more tuples for students whose age are less than or equal to 18! 9961234 Edward 17 9961235 Justin 19 9961238 Janet 18 * * (0, 18] 9961256 Anna 20 … CS561 - XJoin
An Example Open Stream item_id | seller_id | open_price | timestamp 1080 | jsmith | 130.00 | Nov-10-03 9:03:00 <1080, *, *, *> 1082 | melissa | 20.00 | Nov-10-03 9:10:00 <1082, *, *, *> … Query: For each item that has at least one bid, return its bid-increase value. Select O.item_id, Sum (B.bid_price - O.open_price) From Open O, Bid B Where O.item_id = B.item_id Group by O.item_id Bid Stream item_id | bidder_id | bid_price | timestamp 1080 | pclover | 175.00 | Nov-14-03 8:27:00 1082 | smartguy | 30.00 | Nov-14-03 8:30:00 1080 | richman | 177.00 | Nov-14-03 8:52:00 <1080, *, *, *> … Open Stream Joinitem_id Group-byitem_id(sum(…)) Out1 (item_id) Out2 (item_id, sum) Bid Stream No more bids for item 1080! CS561 - XJoin
PJoin Execution Logic 3 3 2 Join State (Memory-Resident Portion) State of Stream A (Sa) State of Stream B (Sb) Hash Table Hash Table Purge Cand. Pool Purge Cand. Pool 3 5 3 9 9 3 … … Punct. Set (PSa) Punct.Set (PSb) 1 3 <10 4 Hash(ta) = 1 Join State (Disk-Resident Portion) Hash Table Hash Table Tuple ta 3 5 9 3 5 … … Stream B Stream A CS561 - XJoin
PJoin Execution Logic Join State (Memory-Resident Portion) State of Stream A (Sa) State of Stream B (Sb) Hash Table Hash Table Purge Cand. Pool Purge Cand. Pool 3 5 3 9 9 … … Punct. Set (PSa) Punct.Set (PSb) 3 <10 Hash(pa) = 1 Join State (Disk-Resident Portion) Hash Table Hash Table Punctuation pa 3 5 9 3 5 … … Stream B Stream A CS561 - XJoin
PJoin vs. XJoin: Memory Overhead Tuple inter-arrival: 2 milliseconds Punctuation inter-arrival: 40 tuples/punctuation CS561 - XJoin
PJoin vs. XJoin: Tuple Output Rate Tuple inter-arrival: 2 milliseconds Punctuation inter-arrival: 30 tuples/punctuation CS561 - XJoin
Conclusion • Memory requirement for PJoin state almost insignificant compared to XJoin’s. • Increase in join state of XJoin leading to increasing probe cost, thus affecting tuple output rate. • Eager purge is best strategy for minimizing join state. • Lazy purge with appropriate purge threshold provides significant advantage in increasing tuple output rate. CS561 - XJoin