Download

1 / 14
140 likes | 276 Views
Exploiting Multithreaded Architectures to Improve the Hash Join Operation. Layali Rashid , Wessam M. Hassanein, and Moustafa A. Hammad * The Advanced Computer Architecture Group @ U of C (ACAG) Department of Electrical and Computer Engineering

E N D
Exploiting Multithreaded Architectures to Improve the Hash Join Operation Layali Rashid, Wessam M. Hassanein, and Moustafa A. Hammad* The Advanced Computer Architecture Group @ U of C (ACAG) Department of Electrical and Computer Engineering *Department of Computer Science University of Calgary
MEDEA'08 University of Calgary 2/13 Outline • The SMT and the CMP Architectures • The Hash Join Database Operation • Motivation • Architecture-Aware Hash Join • Experimental Methodology • Timing and Memory Analysis • Conclusions
MEDEA'08 University of Calgary 3/13 The SMT and the CMP Architectures • Simultaneous Multithreading (SMT): multiple threads run simultaneously on a single processor. • Chip Multiprocessor (CMP): more than one processor are integrated on a single chip.
MEDEA'08 University of Calgary 4/13 The Hash Join Database Operation • The hash join process • The partition-based hash join algorithm
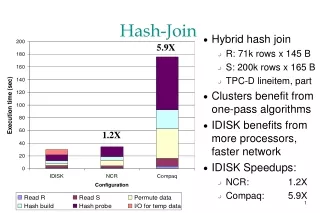
MEDEA'08 University of Calgary 5/13 Motivation Characterizing the Grace hash join on a multithreaded machine • Multithreaded architectures create new opportunities for improving essential DBMS’s operations. • Hash join is one of the most important operations in current commercial DBMSs. • The L2 cache load miss rate is a critical factor in main-memory hash join performance. • Therefore, we have two goals: • Utilize the multiple threads. • Decrease the L2 miss rate.
MEDEA'08 University of Calgary 6/13 Architecture-Aware Hash Join (AA_HJ) • The R-relation index partition phase • Tuples divided equally between threads, each thread has its own set of L2-cache size clusters. • The build and S-relation index partition phase • One thread builds a hash table from each key-range: • Other threads index partition the probe relation.
MEDEA'08 University of Calgary 7/13 Architecture-Aware Hash Join (cont’d) • The probe phase • The random accesses to any hash table whenever there is a search for a potential match are a challenge. • Threads probe hash tables with similar key range simultaneously to increase temporal and spatial locality.
MEDEA'08 University of Calgary 8/13 Experimental Methodology • We ran our algorithms on two machines with the following specifications:
MEDEA'08 University of Calgary 9/13 Experimental Methodology (cont’d) • All algorithms are implemented in C. • We employed the built-in OpenMP C/C++ library to manage parallelism. • For Machine 1 we had a 50MByte build relation and a 100MByte probe relation. • While for Machine 2 we had 250MByte build relation and 500MByte. • We used the Intel VTune Performance Analyzer for Linux 9.0 to collect the hardware events.
MEDEA'08 University of Calgary 10/13 AA_HJ Timing Results • We achieved speedups ranging from 2 to 4.6 compared to Grace hash join on Quad Intel Xeon Dual Core server (Machine 2). • Speedups for the Pentium 4 with HT ranges between 2.1 to 2.9 compared to Grace hash join. • PT: Copy-partitioning hash join • NPT: Non-partitioning hash join • Index PT: Index-partitioning hash join • 2, 4, 8, 12 or 16 is number of threads
MEDEA'08 University of Calgary 11/13 Memory-Analysis for Multithreaded AA_HJ • A decrease in L2 load miss rate is due to the cache-sized index partitioning, constructive cache sharing and Group Prefetching. • A minor increase in L1 data cache load miss rate from 1.5% to 4% on Machine 2.
MEDEA'08 University of Calgary 12/13 Conclusions • Revisiting the join implementation to take advantage of state-of-the-art hardware improvements is an important direction to boost the performance of DBMSs. • We emphasized pervious findings that the hash join is bound by the L2 miss rates, which range from 29% to 62%. • We proposed an Architecture-Aware Hash Join (AA_HJ) that relies on sharing critical structures between working threads at the cache level. • We find that AA_HJ decreases the L2 cache miss rate from 62% to 11%, and from 29% to 15% for tuple size = 20Bytes and 140Bytes, respectively.
MEDEA'08 University of Calgary Backup Time Breakdown Comparison (Machine 2)