Download

1 / 33
330 likes | 456 Views
J ę zyk SQL (Structured Query Language) DDL (Data Definition Language ). Wykład S. Kozielski. J ę zyk SQL (Structured Query Language). 1974 IBM SEQUEL SQL standaryzacja: SQL – 86 SQL – 89 SQL – 92 (SQL - 2) SQL – 99 (SQL - 3) SQL – 2003.

E N D
Język SQL (Structured Query Language) DDL (Data Definition Language) Wykład S. Kozielski
Język SQL (Structured Query Language) 1974 IBM SEQUEL SQL standaryzacja: SQL – 86 SQL – 89 SQL – 92 (SQL - 2) SQL – 99 (SQL - 3) SQL – 2003
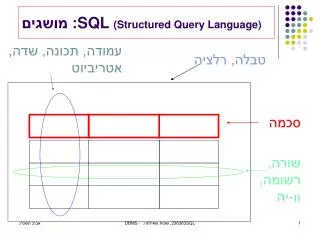
DDL (Data Definition Language) Tworzenie tablic CREATE TABLE <tablica> (<kolumna> <typ> [<ograniczenie kolumny>], ... [,<ograniczenie dodatkowe>])
Typy danych Typy znakowe: CHARACTER(n), CHAR(n): łańcuch n-znaków o stałej długości, VARCHAR(n): łańcuch znaków o zmiennej długości, LONG (LONG VARCHAR): łańcuch 2 GB
Typy numeryczne dokładne: NUMERIC(p,q) DECIMAL(p,q), DEC(p,q) INTEGER, INT SMALLINT przybliżone: FLOAT(p) REAL DOUBLE PRECISION
Typ Data i czas DATE : rrrr-mm-dd TIME : hh-mm-ss:ułamki sekund TIMESTAMP DATETIME INTERVAL
Inne typy BIT(n) – łańcuch n-bitów BYTE - łańcuch 8-bitów BOOLEAN – true/false MONEY SERIAL ...
Ograniczenia kolumny NOT NULL DEFAULT <wartość domyślna> UNIQUE CONSTRAINT <nazwa ogranicz.>] CHECK (<warunek>) więzy referencyjne
Ograniczenia dodatkowe [CONSTRAINT <nazwa ogranicz.>] CHECK (<warunek>) więzy referencyjne
Przykład: definiowanie tablicy o strukturze: uczniowie (nazwisko, wzrost, waga, klasa) create table uczniowie ( nazwisko varchar(15) not null, wzrost int constraint max_min check (wzrost > 70 and wzrost < 280), waga dec(5,2) check (waga < 180), klasa smallint);
Modyfikowanie struktury tablicy ALTER TABLE <tablica> ADD (<kolumna><typ>[<ogranicz. kolumny>]) ADD (<ograniczenie dodatkowe>) MODIFY (<kolumna><typ>[<ogran. kolumny>]) DROP <kolumna> DROP <ograniczenie dodatkowe> DROP CONSTRAINT <ograniczenie kolumny>
i_prac_nazw Pracownicy i_prac_nrz nazwisko wsk nrp nazwisko nrz nrz wsk Bukowy 1 Topolski 1 1 Grabski 2 Jabłoński 2 1 Jabłoński 3 Bukowy 1 2 Malina 4 Malina 3 2 Topolski 5 Grabski 2 3 Indeksy
Tworzenie indeksów CREATE [UNIQUE] INDEX <indeks> ON <tablica> (<kolumna>[ASC|DESC], …) Przykład create index i_prac_nazw on pracownicy(nazwisko);
Tworzenie perspektyw (widoków) CREATE VIEW <perspektywa> …
Usuwanie obiektów DROP TABLE <tablica> DROP INDEX <indeks> DROP VIEW <perspektywa>
Tworzenie perspektywCele tworzenia perspektyw:a) upraszczanie zapytań
Tworzenie perspektywCele tworzenia perspektyw:b) ograniczanie dostępu do tablic
Tworzenie perspektyw CREATE VIEW <perspektywa> [(<lista nazw kolumn>)] AS <instrukcja SELECT> [WITH CHECK OPTION]
Tworzenie przykładowej perspektywy zpwt create view zpwt (nrz, nazwa_z, nrpk_z, nrp, nazwisko, nrt, nazwa_t, nrpk_t, kwota) as select z.nrz, z.nazwa, z.nrpk, p.nrp, nazwisko, t.nrt, t.nazwa, t.nrpk, kwota from zespoły z, pracownicy p, wypłaty w, tematy t where z.nrz = p.nrz and p.nrp = w.nrp and w.nrt = t.nrt
Przykłady wykorzystania perspektywy zpwt select distinct nazwa_z from zpwt where nazwa_t = ‘Projekt sterownika’ select nazwa_z, nazwa_t, sum(kwota) from zpwt group by nazwa_z, nazwa_t
Wykorzystanie perspektyw do aktualizacji tablic Niedopuszczalne w definicji perspektyw: - fraza GROUP, - wyrażenia, funkcje agreg., DISTINCT na liście SELECT, - fraza UNION, - złączenia – z wyjątkami, np. SQL Server (o ile aktualizacja dotyczy 1 tablicy).
Rola frazy CHECK OPTION create view sekretariat_1 as select nrp, nazwisko, nrz from pracownicy where nrz = 1 with check option select * from sekretariat_1 insert into sekretariat_1 values (12,’Sosna’,1) insert into sekretariat_1 values (13,’Dębski’,2)
Więzy referencyjne – ochrona integralności bazy danych Klucze główne (PRIMARY KEY) Kolumna lub zestaw kolumn, których wartości jednoznacznie identyfikują każdy wiersz. Wymagania dla klucza głównego: - może być tylko 1 klucz główny w tablicy, - klucz główny musi mieć wartości unikalne i niepuste.
Zespoły (nrz, nazwa, nrpk) Pracownicy (nrp, nazwisko, nrz) Wypłaty (nrp, nrt, kwota) Tematy (nrt, nazwa, nrpk) Wskazanie kluczy głównych
Klucze obce (FOREIGN KEY) Kolumna lub zestaw kolumn, które tworzą logiczne powiązanie z kluczem głównym jakiejś tablicy (nadrzędnej) Wymagania dla kluczy obcych: - definicja klucza obcego musi odpowiadać definicji klucza głównego istniejącej już tablicy nadrzędnej, - niepustej wartości klucza obcego musi odpowiadać istniejąca wartość klucza głównego, - dopuszcza się wartości puste kluczy obcych.
Zespoły (nrz, nazwa, nrpk) Pracownicy (nrp, nazwisko, nrz) Wypłaty (nrp, nrt, kwota) Tematy (nrt, nazwa, nrpk) Wskazanie kluczy obcych
Ograniczenia na usuwanie wierszy - restrykcyjne (RESTRICT, NO ACTION) – usunięcie wiersza nadrzędnego nie jest możliwe, jeśli istnieją wiersze podrzędne (logicznie z nim powiązane), -z wstawianiem wartości pustych (SET NULL) – usunięcie wiersza nadrzędnego powoduje automatyczne wstawienie wartości pustych w miejsce kluczy obcych wierszy podrzędnych, - kaskadowe (CASCADE) – usunięcie wiersza nadrzędnego powoduje automatyczne usunięcie wierszy podrzędnych (logicznie z nim powiązanych).
Zespoły (nrz, nazwa, nrpk) set null Pracownicy (nrp, nazwisko, nrz) restrict Wypłaty (nrp, nrt, kwota) cascade Tematy (nrt, nazwa, nrpk) Nałożenie ograniczeń na usuwanie danych
Definiowanie więzów referencyjnych Klucz główny Ograniczenie kolumny: PRIMARY KEY Ograniczenie dodatkowe: PRIMARY KEY (<kolumna>, …)
Klucz obcy Ograniczenie kolumny: REFERENCES <tablica nadrzędna> [(<kolumna>)] b) Ograniczenie dodatkowe: FOREIGN KEY (<kolumna>, …) REFERENCES <tablica nadrzędna> [(<kolumna>, …)]
Ograniczenia na usuwanie i modyfikację wierszy ON DELETE { NO ACTION | RESTRICT | CASCADE | SET NULL | SET DEFAULT } ON UPDATE { NO ACTION | RESTRICT | CASCADE | SET NULL | SET DEFAULT }
create table zespoły (nrz int primary key, nazwa varchar(30), nrpk int); create table pracownicy (nrp int primary key, nazwisko varchar(20) not null,nrz int references zespoły on delete set null); create table tematy (nrt int primary key, nazwa varchar(50), nrpk int); create table wypłaty (nrp int references pracownicy, nrt int references tematy on delete cascade,kwota dec(8,2), primary key (nrp, nrt));
alter table zespoły add (foreign key(nrpk) references pracownicy on delete set null); alter table tematy add (foreign key(nrpk) references pracownicy on delete set null);