Download
1 / 83
1.01k likes | 2.57k Views
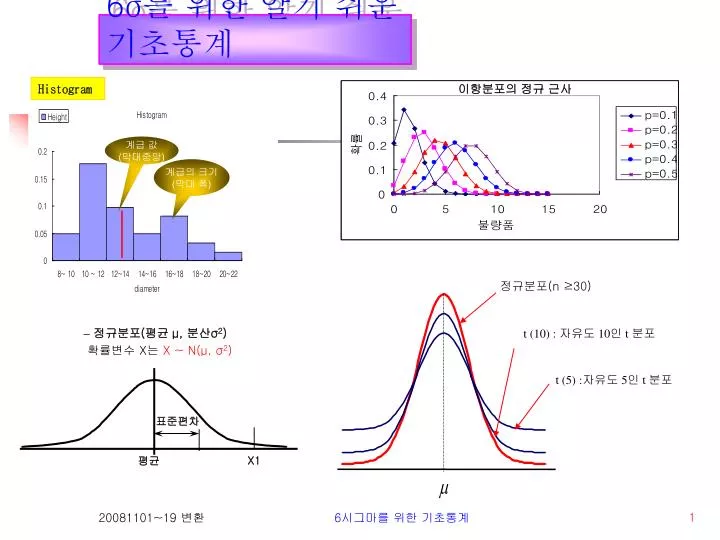
Histogram. 이항분포의 정규 근사. 계급 값 ( 막대중앙 ). 계급의 크기 ( 막대 폭 ). 정규분포 (n ≥30). – 정규분포 ( 평균 μ, 분산 σ 2 ) 확률변수 X 는 X ~ N(μ, σ 2 ). t (10) : 자유도 10 인 t 분포. t (5) : 자유도 5 인 t 분포. 표준편차. X1. 평균. 6 σ 를 위한 알기 쉬운 기초통계. 목차. 1. 통계학 (Statistics) 이란 ? 2. 기술통계 (Descriptive Statistic) 란 ?

E N D
Histogram 이항분포의 정규 근사 계급 값 (막대중앙) 계급의 크기 (막대 폭) 정규분포(n ≥30) –정규분포(평균 μ, 분산σ2) 확률변수 X는 X ~ N(μ, σ2) t (10) : 자유도 10인 t 분포 t (5) :자유도 5인 t 분포 표준편차 X1 평균 6σ를 위한 알기 쉬운 기초통계 6시그마를 위한 기초통계
목차 1. 통계학(Statistics)이란? 2. 기술통계(Descriptive Statistic)란? 3. 데이터(Data)란? 4. 확률분포(Probability Distribution) 5. 추정(Inference) 6. 검정(Testing) 7. 두 모집단의 비교 8. 상관분석 (Correlation) 9. 분산분석(ANOVA) 10. 질적 자료분석 11. 자료출처 6시그마를 위한 기초통계
통계학이란? • 통계학의 정의 통계학은 특별한 의도나 목적을 가지고 조사 연구할 때 1. 자료의 수집방법뿐만 아니라 2. 측정된 자료를 정리하여 정보화하고 3. 그러한 정보를 바탕으로 의사결정을 하는데 있어서 과학적이고 효율적인 방법을 연구 개발하는 학문이다. • 통계학의 분류 • 기술 통계학 관찰대상 전체에서 얻어진 자료를 평균, 분산 등의 요약 통계량이나 여러 가지 그래프를 이용하여 체계적으로 정리 요약하여 자료에 대한 전반적인 특성을 파악하는 통계 기술이다. • 추측 통계학 표본을 관찰함으로써 얻어진 자료를 이용하여 확률이론에 의해 모집단의 특성을 추론하거나 미래를 예측하는 것이 목적이다 6시그마를 위한 기초통계
통계학의 구분과 내용 6시그마를 위한 기초통계
통계학의 기본용어 • 통계학의 기본 용어 - 모집단(Population) • 우리가 알고자 하는 관심의 대상이 되는 전체의 집합 • 유한 모집단 • 무한 모집단 - 표본(Samples) • 모집단에서 조사 대상으로 채택된 일부 - 모수(parameter) • 모집단의 특성을 나타내는 척도로 보통 평균과 표준편차 등이 많이 사용됨 - 통계량(Statistics) • 모수에 대응하는 표본의 특성을 나타내는 척도로 보통 산술평균과 • 표준편차가 많이 사용됨 6시그마를 위한 기초통계
기술통계란? X1 , X2 , …, Xn 모집단(Population) 표본 (Sample) 표본추출 모평균() 모표준편차() 모분산(²) 모비율(p) 표본평균(X) 표본표준편차(S) 표본분산(V) 표본비율(p) 통계적 추론 모집단 분포의 특징을 나타내는 대표 값 : 모 수(Parameter) • 추정(점/구간, Estimation) • 가설 검정(Hypothesis Test) 표본 분포의 특징을 나타내는 대표 값 : 통계량(Statistic) • 기술통계는 Data를 표와 그림으로 표현하는 방법이고 통계적 추론은 Data를 통해 모집단의 특성을 일반화하는 방법입니다. 6시그마를 위한 기초통계
Data와 처리과정 DATA란 무엇인가? (1) 입론(立論)의 기초가 되는 자료 (2) 관찰에서 획득한 사실 • 데이터는 일반적으로 임의의 집단을 대표하는 표본을 통해 수집된다. 데이터 처리 데이터 (Data) 품질 데이터 관리 절차 2. DATA 수집 1. DATA 정의 3. DATA처리 및 표현 참고) 편향(Bias)된 데이터로 도출되는 결론의 문제 • Data는 변동(Variance)를 표현하는 중요한 수단입니다. 정보 (Information) 6시그마를 위한 기초통계
Data의 수집 • Basic Ideas for Collecting Data(데이터 수집을 위한 기본 아이디어) 1. 데이터 수집하는 방법 1) Observational study (관측연구) EX) 두 약 중 어느것이 인간의 어떤 병을 통제하는데 효과적인가? a. 관심 있는 현상을 관찰 EX) 담배가 폐암을 유발하는가? b. Process에 영향을 주지 않음 2) Designed( controlled) experiment (실험연구) - Key process 변수를 통제함으로써 process가 영향을 줄때 data가 얻어짐 3) Sample survey (표본조사) - Key issue : 실험의 결과로서 일어나는 data에 의한 의사 결정을 하고자 함 6시그마를 위한 기초통계
2. 데이터 이용 방법 1) 기술통계학 (Descriptive statistics) - Enumerative study • 자료를 수집하고 정리하여 도표나 표를 만들거나 요약하여 대표 값, • 표본의 크기 등을 다루는 분야 - 방대한 자료집합의 특징을 쉽게 알 수 있게 함 2) 추측통계학 (Inferential statistics) - Analytical study - 회귀분석, 상관분석, 분산분석, 범주형 자료분석, 시계열분석 Data의 이용방법 6시그마를 위한 기초통계
연구의 유형 Type of Studies (연구의 유형) 1. 대부분의 실험계획은 Analytical studies 임 - 통계적 모형을 설정하고 또한 설정된 모형이 합리적인 여부를 평가하며 자료로부터 얻어지는 정보에 근거해 미지의 특성에 대한 결론을 내리고 미래에 일어날 현상에 대한 예측을 함 2. 최종 상품 출시 Testing은 Enumerative study임 - 오직 제품의 특성을 나타내기 위한 시도이기 때문 3. Analytical study에 어떠한 통계적 방법을 적용할 지에 주의 바람 기본적 통계 용어 1) 모집단 (Population) : 주어진 문제에 있어서 관심이 있는 모든 가능한 개체의 집단 2) 표본 (Sample) : 관찰 가능한 모집단의 일부분 6시그마를 위한 기초통계
Data란? 6시그마를 위한 기초통계
Data와 변수 1. 통계 용어의 정리 Data : 모집단으로부터 얻은 표본으로부터 얻은 어떠한 관심 있는 현상의 실제 관측치 EX) 2개의 다른 시약 처리에 의한 2개 표본 환자 집단의 증세 호전 시간 한 공장 라인에서 랜덤하게 뽑힌 20개의 샘플에서 발견된 불량품의 수 변수(Variable) : 측정단위 사이에 변화하는 특성을 보여주는 것 통계학의 목적 : Data를 의미 있게 표현(Description)하고 요약(Summary)하는 것 2. 변수의 종류 - 질적 변수(Qualitative Variables) EX) 남녀, 6학년 학생의 반, 혈압 등급(고, 중, 저) - 양적 변수(Quantitative Variables) 1) 이산형(Discrete) : 정해진 수량으로 표현되어 지는 변수 – Ordinal(Categorical) EX) 초등학교 학년, 마라톤의 순위 2) 연속형(Continuous) : 주어진 범위 내에서의 가능한 모든 실수 값을 가지는 변수 EX) 이율, 시간 3. Random표본 표본은 모집단을 대표한다는 가정이 되어야 한다. 이 표본은 모집단에서 랜덤하게 추출되었다는 Idea는 많은 통계적 이론의 기초가 되고 있다. 6시그마를 위한 기초통계
측정 가능·불가능 데이터 • 측정가능 데이터/ 측정 불가 데이터 (앙케트) - 측정 가능 데이터 (수량 데이터) • 당신의 나이는 ? ( 세) • 한 달에 구입하는 생수는 ? ( 개) • 몸무게, 온도, 100m 달리기 기록, 키를 잴 때 • 눈금과 눈금 사이 간격이 균등 - 측정 불가 데이터 (카테고리 데이터) • 통계학을 읽고 난 느낌은 ? 1. 매우 재미있다 2.재미있다 3.보통이다. 4.재미없다 5.매우 재미없다 (실무에서 수량데이터로 취급하는 경우가 있음) • 출신지, 날씨, 혈액형 • 급과 급사이의 간격이 균등하지 않음 6시그마를 위한 기초통계
Data의 표현방법 2. 빈도 표(Frequency table) 3. 히스토그램(Histogram) Class Interval Frequency Relative Frequency Height 계급 계급 값 (막대중앙) 08 – 10 3 0.097 0.049 10 – 12 11 0.355 0.177 계급의 크기(막대 폭) 12 – 14 6 0.193 0.097 14 – 16 3 0.097 0.049 16 – 18 5 0.161 0.081 18 – 20 2 0.065 0.032 20 - 22 1 0.032 0.016 31 1.000 Frequency Relative frequency = (상대도수) Total # of observations in sample Height = Relative frequency / Width Data의 표현: 데이터의 전체적인 분위기를 파악함 1. 표현의 목적 : 표본의 정보를 요약하여 보여주는 것 6시그마를 위한 기초통계
기타 표현방법 HOURS Stem-and-Leaf Plot Frequency Stem & Leaf 34.00 0 . 0000011111112222222223333333444444 27.00 0 . 555555555666666666777777888 17.00 1 . 00000000000022244 8.00 1 . 55555566 3.00 2 . 000 5.00 Extremes (>=25) Stem width: 10 Each leaf: 1 case(s) 4. Box plot 5. 줄기와 잎 그림 (Stem-and-leaf plot) 그 외의 방법들 6시그마를 위한 기초통계
Data의 표현 시 고려할 점 6. Data 표현에 있어서의 고려하여야 할 점 ex) 히스토그램의 예에서 7. Data 표현을 통해 관심있게 보아야 할 점 1) 대칭성 (Symmetry) 대칭(Symmetric) Rightly skewed Leftly skewed 2) 봉우리(Modality) 단봉(Unimodal) 양봉(Bimodal) 3) 이상치(Outlier) 같은 Data 임에도 불구하고 결과를 임의로 변질시킬 위험이 있다. 6시그마를 위한 기초통계
기술통계 기술 통계(Descriptive Statistic) 위치 모수(Location parameter) : 평균, 중앙값, 최빈 값 측정 모수(Scale parameter) : 분산, 표준편차 1. 중심의 측정 (Measure of center) 평균(Mean, average) : 중앙값(Median) : n개의 데이터를 크기 순으로 나열했을 때 n이 홀수이면 중앙에 위치하는 값이고, 짝수이면 중앙에 위치한 2개의 데이터를 평균한다. 최빈 값(Mode) : 반복되어 가장 많이 나타나는 측정치 EX) 1, 3, 5, 5, 8, 8, 9, 9, 9, 10, 11 Mean = (1+3+5+5+8+8+9+9+9+10+11)/11 = 7.090909 Median = 8 Mode = 9 2. 산포의 측정 (Measure of spread) 표본 분산 (Sample variance) : √S² 표본 편차 (Standard deviation) : 데이터의 가장 큰 값(MAX) –데이터의 가장 작은 값(MIN) 범위 (Range) : 6시그마를 위한 기초통계
통계적 추론 1. 모수 (Parameter) : 모집단의 특성치 = 모집단의 평균 = 모집단의 분산 2. 추정치 (Estimator) : 모집단에 대응되는 표본의 특성치 = 표본집단의 평균의 추정치 = 표본집단의 분산의 추정치 들의 평균 = 의 분산 = n 이 증가할수록 값은 작아짐 표본의 수가 증가할수록 더 정확한 추정치를 얻을 수 있다. 변동계수 (Coefficient of variation, CV) 서로 다른 평균과 표준편차를 갖는 여러 자료의 상대적인 변동 혹은 산포를 측정하기 위해각 자료의 평균과 표준편차를 동시에 고려한 계수 CV= (비율) 또는 *100 (PERCENT) 선형추가 모형 (Linear additive model) : 표본추출 등의 문제 등으로 발생한 오차 표준편차는 이 오차의 추정치이다. 은 의 추정 값이다. 통계적 추론 (Statistical Inference) 6시그마를 위한 기초통계
확률분포 6시그마를 위한 기초통계
확률분포의 구분 계수형 (이산형 확률 분포) 계량형 (연속형 확률 분포) 이항 분포 포아송 분포 정규 분포 지수 분포 감마 분포 t 분포 초기하 분포 와이블 분포 분포 F 분포 확률분포의 구분 신뢰성 데이터는 와이블 분포를 따르는 경우가 많다. 6시그마를 위한 기초통계
이산형 확률분포와 정규분포 근사(Approximately) 1. 이항분포의 정규 근사 이항 분포 (불량품) np≥5 n(1-p)≥5 1 0.8 dpu=0.1 dpu=1.0 0.6 p < 0.1 n > 50 확률 dpu=2.0 2. 포아송 분포의 정규 근사 정규 분포 0.4 dpu=2.5 dpu=4.0 0.2 0 0 5 10 15 20 평균≥5 결점수 포아송 분포 (결점수) 6시그마를 위한 기초통계
정규분포(Normal Distribution) 99.7% of data are within 3 standard deviations of the mean 95% within 2 standard deviations 68% within 1 standard deviation 0.340 0.340 0.024 0.024 0.001 0.001 0.135 0.135 - 3 - 2 - + +2 +3 6시그마를 위한 기초통계
표준정규분포(Standard Normal Distribution) 변환 –정규분포(평균 μ, 분산σ2) 확률변수 X는 X ~ N(μ, σ2) 정규분포 표준편차 X1 평균 Z 변환 –표준정규분포(평균0, 표준편차1) 확률변수 Z은 Z ~ N(0,1) ? Z 표준정규분포 1 Z 0 ※ 표준정규분포 및 확률밀도함수에서 넓이=비율=확률 6시그마를 위한 기초통계
표준정규분포 변환 6시그마를 위한 기초통계
표본분포(Sample Distribution):t-분포 정규분포(n ≥30) t (10) : 자유도 10인 t 분포 t (5) :자유도 5인 t 분포 − t-분포는 정규분포보다 더 넓게 퍼져 있고, 꼬리부분이 더 평평함. − 평균을 중심으로 대칭이고, 종 모양을 띄고 있어 정규분포와 형태가 유사함. −표본크기가 커질수록 분포가 중심부근에서 점점 뾰족해 지고, 표본의 크기가 30이상이면 정규분포가 거의 같아짐. 6시그마를 위한 기초통계
표본분포 : χ²(카이제곱)분포 –카이제곱 분포는 표본분산 s2과 관련된 분포임. –확률 변수 가 각각 표준정규 분포 N(0,1)을 따르고, 서로 독립일 때 그들 제곱합 l I 은 자유도 k 인 카이 제곱분포 χ2(k)를 따른다. –모집단 분산 추론에 카이제곱분포 를 이용한다 6시그마를 위한 기초통계
표본분포 : F 분포 –F-분포는 두 정규모집단의 분산을 비교하기 위한 추론에 주로 사용. –확률 변수 χ12과 χ22가 각각 자유도 ν1(분자의 자유도)과 ν2(분모의 자유도)인 카이 제곱분포를 따르며 서로 독립이라고 할 때, 통계량 는 자유도 (ν1, ν2)인 F-분포(ν1, ν2)를 따른다. 6시그마를 위한 기초통계
대표적 확률분포 요약 6시그마를 위한 기초통계
확률분포 (Probability Distribution) 6시그마를 위한 기초통계
이산확률분포(Discrete Probability Distribution) 1. 이항 분포 (Binomial distribution) 1) Bernoulli의 확률 분포 Bernoulli의 실행 : 두 가지 실행 가능한 결과 EX) 성공, 실패 성공의 확률이 p이라면 실패의 확률은 q=1-p 2) 이항 분포 : n개의 Bernoulli확률 변수로 이루어짐 EX) 완구 완제품 중 34개를 무작위로 뽑아내어서 불량률이 17%일 때 몇 개의 불량품이 나오는지 조사 : 이항 분포 함수 2. 포아송 분포 (Poisson distribution) 단위시간이나 공간에서의 희귀사건의 발생건수의 분포 EX) 1898년 프러시아 기마병중에서 말에 차여 사망한 숫자 : 포아송 분포 함수 Ⅰ. 이산확률분포 6시그마를 위한 기초통계
연속확률분포(Probability Distribution) 1. 정규 분포 (Normal Density Distribution) 통계학에 있어서 중추적인 역할을 하는 분포 1) 평균을 중심으로 좌우대칭의 종 모양의 분포 2) 평균 = 중앙값 = 최빈값 3) 평균은 분포의 중심위치를 결정하고, 분산은 분포의 모양을 결정 4) = 0.683 = 0.99 = 0.95 = 0.997 = 0.954 : 정규 분포 함수 1.-1 표준 정규 분포 (Standard Normal Distribution) 평균이 0이고 분산이 1인 정규 분포 : 표준 정규 분포 함수 표 준 화 : 정규분포를 변환을 통해 표준 정규 분포로 표현 EX) Ⅱ. 연속확률분포(Continous Probability Distribution) 6시그마를 위한 기초통계
연속확률분포(Probability Distribution) 1.-2 이항분포의 정규근사 에 대해 n이 충분이 크고 p가 0 또는 1에 가깝지 아니하면 표준화된 확률변수 는 근사적으로 표준정규 분포 를 따르게 된다. 1.-3 중심극한정리 (Central Limit Theorem) 평균이 고 분산이 인 임의의 확률분포를 가지는 모집단으로부터 크기 n 인 확률표본 X1,X2,…,Xn 을 취했을 때 표본평균 는 n 이 충분히 크면 대략적으로 정규분포 을 따른다. 2. t 분포 (Student t-Distribution) 대표본에서는 모집단의 분포가 정규분포가 아닐 때에도 중심극한 정리에 의하여 는 정규분포에 가까운 분포를 따르며 대신에 표본표준편차(s)를 대입해도 위의 사실은 근사적으로 성립한다. 그러나 소표본에서는 모집단이 정규분포를 따를 때에도 대신에 s를 대입한 것이 정규분포와는 많이 다를 수 있음 보통 n이 30보다 작은 경우 분포는 Z-통계량에서 대신에 s를 대입한 t-통계량의 분포를 사용. X1, X2, ... , Xn이 에서의 랜덤하게 추출한 표본일 때 (n < 30) n-1 : 자유도(Degree of Freedom) 6시그마를 위한 기초통계
Example 1 • 어느 제조 공장의 불량률이 0.2%로 알려져 있다. 무작위로 1,000개를 취하여 검사할 때 • 불량품이 5개 이상 나올 확률은 얼마인가? < 풀이 2> 정규분포에 의한 근사적 계산으로 비교해보자 n=1,000, p=0.002 이때, x를 N(2, 1.996)에 0.5의 구간보정을 하여 확률을 계산하면, 포아송 분포로 구한 실제확률 0.053에 가까워짐을 볼 수 있다. 6시그마를 위한 기초통계
확률분포와 표본분포 6시그마를 위한 기초통계
Ⅰ. 확률표본(Random Sample) 1. 확률 표본: 서로 독립이고 같은 분포를 따르는 확률 변수들 I i d(Independently IdenticallyDistributed) 2. 통계량(Statistic) : 확률표본의 함수 (표본에서 얻은 정보량) 표본평균 : 표본분산 : 3. 표본평균의 분포와 중심극한정리 에서 구한 표본평균 는 을 따른다. 중심극한정리 : 앞 Chapter의 정규분포 참조 N 이 증가할수록 (a)->(b)->(c)->(d)로 변함 6시그마를 위한 기초통계
Ⅱ. 표본분포(Sample Distribution) -1 1. 분포 (Chi-Squared Distribution) 확률변수 가 각각 표준정규분포 N(0, 1)을 따르고 서로 독립일 때, 의 분포를 자유도(Degree of Freedom) K 인 (카이제곱,Chi-Square)분포라 한다. 표본분산 의 분포는 단일모집단의 경우 : ~ 독립인 두 집단의 경우 : ~ 단, 2. t 분포 (t-Distribution) 확률 변수 Z ~ N(0,1) 이고, 이고 서로 독립이라면, 을 자유도가 K인 t분포라 한다. 분산을 모를 경우 표본 분산을 사용하여 분산이 동일한 두 정규모집단일 경우 6시그마를 위한 기초통계
Ⅱ.표본분포-2 3. F 분포 (F-Distribution) 분산이 동일한 두 개의 정규 모집단으로부터 각각 랜덤하게 추출한 의 2조의 표본에서 의 비 (단, F>1 즉, ) 는 자유도 인 F분포 를 한다. 1) 일때 이다. 2) 두 정규모집단에서의 표본분산의 비에 대한 분포 6시그마를 위한 기초통계
추론(추정/검정) 6시그마를 위한 기초통계
추론(Inference) 1. 점 추정(Point estimation) : 표본에서 얻어지는 정보를 이용하여 미지인 모수의 참값으로 생각되는 하나의 수 값을 택하는 과정 추정 량(Estimator) : 모수를 추정하기 위하여 사용되는 통계량 추정 값(Estimate) : 추정량의 관측 값 표준오차(Standard Error) : 추정량의 표준편차 (1) 점 추정에 요구되어지는 성질 a. 불편성(Unbiased) : 추정량의 분포의 중심위치에 요구되는 성질 b. 유효성(Efficiency) : 추정량의 산포에 요구되는 성질 c. 일치성(Consistency) d. 충분성(Sufficiency) : 표본이 제공하는 모수에 대한 모든 정보를 이용한 통계량 불편추정량(Unbiased estimator) 통계적 추론 : 표본에서 얻은 정보를 이용하여 모집단(모수)에 대한추측을 하는 과정 추 정 :점 추정 --- 불편성, 유효성(최소분산불편추정량) 구간추정 --- 같은 신뢰수준 하에서는 구간의 길이가 최소 검 정 : 모수에 대한 주장의 옳고 그름을 판정하는 과정 6시그마를 위한 기초통계
검정(Testing) 6시그마를 위한 기초통계
가설검정 가설검정의 개요 • 가설검정(假設檢定 : Hypothesis testing)의 개요 • 정의 : 모집단의 모수 또는 분포 등에 관하여 귀무가설과 대립가설을 설정한 후에 표본을 통하여 얻어지는 정보에 따라서 어떤 가설이 맞는가를 결정하는 통계적 분석(용어적 정의임) • 가설검정의 의미: 관심이 되는 모집단 특성에 대한 어떠한 주장을 확인하기 위해 그 모집단으로부터 표본을 추출하여 분석해 봄으로써 모집단에 대한 어떠한 주장의 타당성을 검토해 보는 것 6시그마를 위한 기초통계
분석목적에 따른 통계적 가설검정의 형태 6시그마를 위한 기초통계
가설검정 로드 맵 계수형 데이터 하나의 모집단 1-Proportion Stat -Basic Stats -1 proportion 두 개의 모집단 계량형 데이터 2-Proportion Stat -Basic Stats -2 proportion 둘 이상의 모집단 Normality Test 카이제곱검정 비정규 데이터 정규 데이터 Ho: 정규분포를 따른다, H1: 정규분포가 아니다 Stat - Basic Stat - Normality Test Stat -Tables - Chi-square Test 하나의 모집단 둘 이상의 모집단 표준편차의 신뢰구간 Test for Equal Variances (Levene’s Test) Test for Equal Variances (F Test or Bartlett’s Test) Ho: s1 = s (목표 값) H1: s1 ¹ s (목표 값) 표준편차가 특정 값과 같은 지에 대한 검정은 Minitab이 지원하지 못한다. 다만 표준편차의 추정치와 신뢰구간을 구하기 위해서는 다음 메뉴를 활용한다. Stat -Basic Statistics - Display Descriptive Stats Ho: s1 = s2 = s3 = ... H1: 적어도 하나는 다르다 Stat - Anova - Test for Equal Variances 두 모집단만을 비교할 때는F-test 사용 하나의 모집단 1 Sample-Sign 또는 1 Sample-Wilcoxon 1 Sample t 또는 1 Sample Z No 등 분산 Ho: M1 = M (목표 값) H1: M1 ¹ M (목표 값) Stat - Nonparametric - 1 Sample-Sign 또는 Stat - Nonparametric - 1 Sample-Wilcoxon Ho: m1 = m (목표 값) H1: m1 ¹ m (목표 값) Stat - Basic Stats - 1 Sample-t (s를 모를 때) 1Sample Z (s를 알 때) 둘 이상의 모집단 Yes 두 개의 모집단 두 개의 모집단 Mann-Whitney Test One-way ANOVA 2 Sample t (동일한 분산) Ho: M1 = M2 H1: M1 ¹ M2 Stat - Nonparametric - Mann-Whitney 2 Sample t (분산이 다를 때) Kruskal-Wallis Test Ho: m1 = m2 H1: m1 ¹ m2 Stat - Basic Stats - 2-Sample t “assume equal variances” 선택 Ho: m1 = m2 = m3 = ... H1: 적어도 하나는 다르다 Stat - Anova- One-way Ho: m1 = m2 H1: m1 ¹ m2 Stat - Basic Stats - 2-Sample t “assume equal variances” 선택 안 함 둘 이상의 모집단 Ho: M1 = M2 = M3 = ... H1: 적어도 하나는 다르다 Stat - Nonparametric - Kruskal-Wallis 유의수준 = 0.05인 경우: P-값 >0.05 이면 Ho 기각하지 못함 P-값< 0.05 이면 Ho 기각 가설검정 6시그마를 위한 기초통계
