Download

1 / 22
220 likes | 237 Views
Explore the concept of Similarity Networks and their applications in identifying types of individuals, featuring local network construction, inference methods, and network completeness.

E N D
Inference Algorithm for Similarity Networks Dan Geiger & David Heckerman Presentation by Jingsong Wang USC CSE BN Reading Club 2008-03-17 Contact: {wang82,mgv}@cse.sc.edu
The secured building story • A guard of a secured building expects four types of persons to approach the building's entrance: executives, regular workers, approved visitors, and spies. As a person approaches the building, the guard can note its gender, whether or not the person wears a badge, and whether or not the person arrives in a limousine. We assume that only executives arrive in limousines and that male and female executives wear badges just as do regular workers (to serve as role models). Furthermore, we assume that spies are mostly men. Spies always wear badges in an attempt to fool the guard. Visitors don't wear badges because they don't have one. Female-workers tend to wear badges more often than do male-workers. • The task of the guard is to identify the type of person approaching the building.
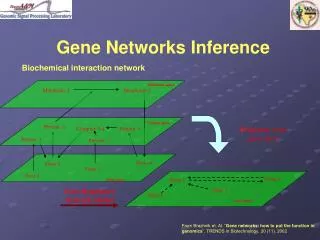
Definition of Similarity Network • Distinguished Variable • Hypothesis • Cover • A cover of a set of hypotheses H is a collection {A1, . . . , Ak} of nonempty subsets of H whose union is H. • Each cover is a hypergraph, called a similarity hypergraph, where the Ai are hyperedges and the hypotheses are nodes. • A cover is connected if the similarity hypergraph is connected.
Definition of Similarity Network • Similarity Network • Let P(h, u1,. . . , un) be a probability distribution and A1,. . . , Akbe a connected cover of the values of h. A directed acyclic graph Di is called a local network of P associated with Aiif Diis a Bayesian network of P(h, v1,. . . , vm | [[Ai]]) where {v1,. . . , vm} is the set of all variables in {u1,. . . , un} that “help to discriminate” the hypotheses in Ai. The set of k local networks is called a similarity network of P.
Definition of Similarity Network • Subset Independence • Hypothesis-specific Independence
Definition of Similarity Network • The practical solution for constructing the similarity hypergraph is to choose a connected cover by grouping together hypotheses that are ``similar'' to each other by some criteria under our control (e.g., spies and visitors). • This choice tends to maximize the number of subset independence assertions encoded in a similarity network. Hence the name for this representation.
Two Types of Similarity Networks • “helps to discriminate” • Related • Relevant • Define event e to be [[Ai]] • A disjunction over a subset of the values of h
Two Types of Similarity Networks • Type 1 • A similarity network constructed by including in each local network Di only those variables u that satisfy related(u, h | [[Ai]]) is said to be of type 1. • Type 2 • relevant(u, h | [[Ai]])
Two Types of Similarity Networks • Theorem 1 • Let P(u1, … un | e ) be a probability distribution where U= {u1, … un} and e be a fixed event. Then, ui and uj are unrelated given e iff there exist a partition U1, U2 of U such that ui∈U1, uj∈U2, and P(U1, U2 | e) = P(U1 | e) P(U2 | e)
Two Types of Similarity Networks • Theorem 2 • Let P(u1,…, un | e) be a probability distribution where e is a fixed event. Then, for every ui and uj, relevant(ui, uj | e) implies related(ui, uj | e)
Inference Using Similarity Networks • The main task similarity networks are designed for is to compute the posterior probability of each hypothesis given a set of observations, as is the case in diagnosis. • Under reasonable assumptions, the computation of the posterior probability of each hypothesis can be done in each local network and then be combined coherently according to the axioms of probability theory.
Inference Using Similarity Networks • Strictly Positive • We will remove this assumption later at the cost of obtaining an inference algorithm that operates only on type 1 similarity networks and whose complexity is higher.
Inference Using Similarity Networks • The inference problem • Compute P(hj | v1,…,vm) • INFER procedure • Two parameters: a query, a BN
Inference Using Similarity Networks • Theorem 3 • Let P(h,u1,…,un) be a probability distribution and A= { A1,…, Ak} be a partition of the values of h. Let S be a similarity network based on A. Let v1,…,vm be a subset of variables whose value is given. There exists a single solution for the set of equations defined by Line 7 and 8 of the above algorithm and this solution determines uniquely the conditional probability P(h |v1, …, vm). • Complexity
Inferential And Diagnostic Completeness • Inferential Complete • Diagnostically Complete
Inferential And Diagnostic Completeness • Theorem 4 (restricted inferential completeness) • Theorem 5 (Diagnostic completeness)
Inferential And Diagnostic Completeness • Hypothesis-specific Bayesian multinet of P • Similarity network to Bayesian Multinet conversion
Inferential And Diagnostic Completeness • Hypothesis-specific Bayesian-Multinet Inference Algorithm • For each hypothesis hi • Bi = INFER(P(v1,…,vl | hi), Mi) • For each hypothesis hi • Compute P(hi | v1,…,vl)