Download

1 / 1
10 likes | 181 Views
Celery. Vegetable. Feature Activation <is crunchy> .94 <is edible> .94 <is green> .93 <is nutritious> .93 <eaten with dips> .92 <grows in gardens> .92 <has fibre> .92 <has leaves> .92 <is stringy> .92 <tastes bland> .92 <eaten in salads> .91 <has stalks> .91 <is long> .91

E N D
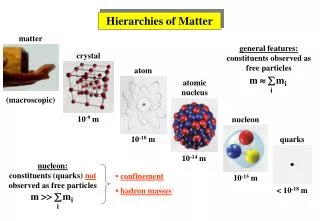
Celery Vegetable Feature Activation <is crunchy> .94 <is edible> .94 <is green> .93 <is nutritious> .93 <eaten with dips> .92 <grows in gardens> .92 <has fibre> .92 <has leaves> .92 <is stringy> .92 <tastes bland> .92 <eaten in salads> .91 <has stalks> .91 <is long> .91 <tastes good> .90 Feature Activation <is edible> .67 <grows in gardens> .45 <is green> .45 <eaten by cooking> .44 <is nutritious> .33 <eaten in salads> .31 <is round> .31 <is small> .31 <tastes good> .29 <has seeds> .24 <is crunchy> .24 <is white> .24 <used for cooking> .23 <grows in ground> .22 <has leaves> .22 Conceptual Hierarchies Arise from the Dynamics of Learning and Processing: Insights from a Flat Attractor Network Christopher M. O’ConnorKen McRaeGeorge S. Cree University of Western Ontario University of Western Ontario University of Toronto at Scarborough London, Ontario, Canada London, Ontario, Canada Toronto, Ontario, Canada cmoconno@uwo.camcrae@uwo.cagcree@utsc.utoronto.ca Acknowledgements NSERC grant OGP0155704 & NIH grant R01-MH6051701 to Ken McRae Superordinate & Basic-level Representations • Introduction • people’s conceptual knowledge structure for concrete nouns traditionally viewed as hierarchical (Collins & Quillian, 1969) • superordinate concepts (vegetable) represented at a different level in hierarchy than basic-level concepts (carrot, or pumpkin) • flat attractor networks – i.e., models with a single layer of semantics – have provided insight to a number of phenomena regarding basic-level concepts • semantic priming • statistically-based feature correlations • concept-feature distributional statistics • unclear how these networks could learn and represent superordinate concepts • can such a network account for established results and provide novel insights? Goals • demonstrate that a flat attractor network can learn superordinate concepts • simulate typicality ratings to show model accounts for graded structure • simulate feature verification latencies to demonstrate superordinate representations may be computed similarly to basic-level concepts • simulate superordinate semantic priming to provide insight into the temporal dynamics of similarity • Superordinate Priming & Temporal Dynamics of Similarity • both spreading activation (Collins & Loftus, 1975) and attractor networks predict that magnitude of semantic priming is determined by degree of semantic similarity • supported experimentally using basic-level concepts (McRae & Boisvert, 1998) • simulated using feature-based attractor nets (Cree, McRae, & McNorgan, 1999) • therefore, the degree that an exemplar target is primed by its superordinate should vary as a function of typicality • high typicality > medium typicality > low typicality • however, Schwanenflugel and Rey (1986) found that short SOA superordinate priming does not vary as a function of target exemplar typicality • replicated and simulated their experiment Experiment • 72 superordinate-exemplar pairs, e.g., vegetable paired with peas, turnip, garlic • 12 superordinate primes with 2 exemplars each of low, medium, and high typicality • 200ms superordinate prime, 50ms ISI, exemplar target until response (concrete object?) Results: replicated Schwanenflugel and Rey (1986) • main effect of relatedness, F1(1, 42) = 8.09, p < .01,F2(1, 66) = 3.52, p < .07 • no interaction between typicality & relatedness, F1 < 1, F2 < 1 • activation of features influenced by: • Feature Frequency: • if many exemplars possess a feature, it is strongly activated • Category Cohesion: • degree of featural overlap of exemplars determines activation of superordinate features • more overlap = more activation • Feature Correlations: • activate one another during the computation of meaning • Basic-level representations: • all features have activations close to 1 (on) • Superordinate representations: • most features have intermediate activations Simulation • superordinate prime wordform presented to model for 15 ticks • exemplar target presented for 20 ticks • cross entropy error recorded over last 20 ticks Results • typicality & relatedness did not interact, F < 1 • main effect of relatedness, F(1, 66) = 187.27, p < .001 • related lower than unrelated for ticks 1 to 13 Category N Cosine/ Fam Res/ Cosine/ Typicality Typicality Fam Res Feature Verification • Typicality Ratings • important for any semantic memory model to simulate graded structure Experiment • collected behavioral typicality ratings for all 20 categories (7-point scale) Simulation • superordinate wordform presented & representation recorded • basic-level wordform presented & representation recorded • computed cosine similarity between each superordinate & exemplar • computed correlation between typicality ratings & cosines for each category • correlation between typicality ratings & family resemblance served as baseline Results • Model Structure • input: 30 wordform units representing spelling/sound of a word • output: 2349 semantic feature units representing features taken from McRae et al.’s (2005) feature production norms • e.g., <has wings>, <made of metal>, <is red>, <has seeds> • single layer of semantics; taxonomic features removed; all semantic features were interconnected • thus, no hierarchy built into the model Training • model learned to map random 3-unit wordform for each concept to semantic features for that concept • basic-level concepts trained in 1-to-1 manner: • 3-unit wordform paired with same set of semantic features on every learning trial • superordinate concepts trained in 1-to-many manner • wordform paired with semantic features of one of its exemplars on each trial • e.g., wordform for vegetable paired with features of carrot on one trial, spinach on another, etc. • each exemplar was presented equally often • thus, typicality was NOT built into the model furniture 17 .76** .62** .78** fruit 29 .71** .69** .91** appliance 14 .61* .73** .89** weapon 39 .58** .70** .76** utensil 22 .57** .52** .68** bird 29 .57** .49** .69** insect 13 .52* .69** .77** carnivore 19 .52* .45* .83** container 14 .46* .50* .51** vegetable 31 .45** .50** .90** musical instrument 18 .44* .54* .94** clothing 39 .43** .50** .73** tool 34 .41** .38* .65** fish 11 .41 .36 .93** animal 133 .18* .12 .55** pet 22 .15 -.01 .86** herbivore 18 .04 .21 .78** predator 17 -.14 .06 .60** mammal 57 -.03 .14 .64** vehicle 27 -.14 .18 .72** * p < .05, ** p < .01 Fam Res = Family Resemblance • Explanation • why is priming from superordinate to exemplar different than priming between basic-level concepts? • superordinate features have intermediate activations, which (due to the sigmoid activation function) require less change in net input to be turned on or off • basic-level priming: features in prime but not in target relatively difficult to turn off • prime & target must have high degree of featural overlap to produce priming • superordinate priming: activation of prime's features more easily changed • priming still results (vs. unrelated superordinate), but less sensitive to similarity • therefore, same amount of facilitation for exemplars of all typicality levels • Conclusions • semantic memory can be represented as a single layer of semantics • without a transparent hierarchical structure • accounts for graded structure of categories • predicts online superordinate verification latencies; novel result • due to the temporal dynamics of similarity, accounts for counterintuitive and seemingly inconsistent results regarding basic-level vs. superordinate priming • results counter to hierarchical spreading activation theories • models predicts typicality ratings at least as well as family resemblance • therefore, the model was successful in simulating graded structure • Feature Verification • similar “flat” attractor networks have simulated basic-level feature verification • model can also simulate verification of superordinate features Experiment • 54 superordinate-feature pairs such as: furniture <made of wood> & fruit <tastes sweet> • superordinate name for 400 ms, feature name until participant responded • "Is the feature characteristic of the category?" Simulation • present superordinate wordform and record feature's activation over 20 time ticks • correlated model's feature activation with human verification latency • feature activation in model predicts human verification from ticks 6 - 20 Semantic Features (2349 units) References Collins, A. M., & Quillian, M. R. (1969). Retrieval time from semantic memory. Journal of Verbal Learning and Verbal Behavior, 8, 240-247. Collins, A. M., & Loftus, E. F. (1975). A spreading activation theory of semantic processing. Psychological Review, 82, 407-428. Cree, G. S., McRae, K, & McNorgan, C. (1999). An attractor model of lexical conceptual processing: Simulating semantic priming. Cognitive Science, 23, 371-414. McRae, K. & Boivert, S. (1998). Automatic semantic similarity priming. Journal of Experimental Psychology: Learning, Memory and Cognition, 24, 558-572. McRae, K., Cree, G. S., Seidenberg, M. S., & McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 37, 547-559. Schwanenflugel, P. J., & Rey, M. (1986). Interlingual semantic facilitation: Evidence for a common representational system in the bilingual lexicon. Journal of Memory and Language, 25, 605-618. Wordform (30 units)