Download

1 / 16
160 likes | 310 Views
Syntax Analysis. Sections 4.1-4.4:. Other Derivation Concepts. . . lm. rm. Leftmost : Replace the leftmost non-terminal symbol E E A E id A E id * E id * id Rightmost : Replace the rightmost non-terminal symbol E E A E E A id E * id id * id. lm.

E N D
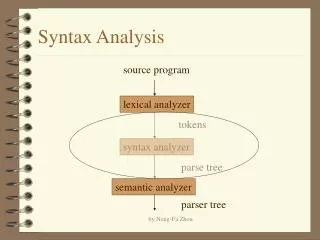
Syntax Analysis Sections 4.1-4.4:
Other Derivation Concepts lm rm Leftmost: Replace the leftmost non-terminal symbol E E A E id A E id * E id * id Rightmost: Replace the rightmost non-terminal symbol E E A E E A id E *id id * id lm lm lm lm rm rm rm rm Important Notes: A If A , what’s true about ? If A , what’s true about ? Derivations: Actions to parse input can be represented pictorially in a parse tree.
Examples of LM / RM Derivations E E A E | ( E ) | -E | id A + | - | * | / | A leftmost derivation of : id + id * id A rightmost derivation of : id + id * id
Derivations & Parse Tree E E E E * E E E E A A A A E E E E id * id id * E E A E E * E id * E id * id
Parse Trees and Derivations E E E E E + E id+ E E E E E + + * + E E E E id+ E id+ E * E id id Consider the expression grammar: E E+E | E*E | (E) | -E | id Leftmost derivations of id + id * id E E + E
Parse Tree & Derivations - continued id+ E * E id+id* E id id id id id E E E E E E E E + * * + E E E E id+id* E id+id* id
Alternative Parse Tree & Derivation E E E * E E + E id id id E E * E E + E * E id + E * E id + id * E id + id * id WHAT’S THE ISSUE HERE ? Two distinct leftmost derivations!
Resolving Grammar Problems/Difficulties Reg. Lang. CFLs Regular Expressions : Basis of Lexical Analysis Reg. Expr. generate/represent regular languages Reg. Languages smallest, most well defined class of languages Context Free Grammars: Basis of Parsing CFGs represent context free languages CFLs contain more powerful languages anbn – CFL that’s not regular.
Resolving Problems/Difficulties – (2) a start a b b 0 2 1 3 b Since Reg. Lang. Context Free Lang., it is possible to go from reg. expr. to CFGs via NFA. Recall: (a | b)*abb
Resolving Problems/Difficulties – (3) a start a b b 1 2 0 3 b b a j i j i Construct CFG as follows: • Each State I has non-terminal Ai : A0, A1, A2, A3 • If then Aia Aj • If then Ai bAj • If I is an accepting state, Ai : A3 • If I is a starting state, Ai is the start symbol : A0 : A0 aA0, A0 aA1 : A0 bA0,A1 bA2 : A2 bA3 T={a,b}, NT={A0, A1, A2, A3}, S = A0 PR ={ A0 aA0 | aA1 | bA0 ; A1 bA2 ; A2 bA3 ; A3 }
How Does This CFG Derive Strings ? a start a b b 0 2 1 3 b vs. A0 aA0, A0 aA1 A0 bA0, A1 bA2 A2 bA3, A3 How is abaabb derived in each ?
Regular Expressions vs. CFGs • Regular expressions for lexical syntax • CFGs are overkill, lexical rules are quite simple and straightforward • REs – concise / easy to understand • More efficient lexical analyzer can be constructed • RE for lexical analysis and CFGs for parsing promotes modularity, low coupling & high cohesion. CFGs : Match tokens “(“ “)”, begin / end, if-then-else, whiles, proc/func calls, … Intended for structural associations between tokens ! Are tokens in correct order ?
Resolving Grammar Difficulties : Motivation • ambiguity • -moves • cycles • left recursion • left factoring • The structure of a grammar affects the compiler designrecall “syntax-directed” translation • Different parsing approaches have different needs Top-Down vs. Bottom-Up redesigning a grammar may assist in producing better parsing methods. Grammar Problems
Resolving Problems: Ambiguous Grammars stmt expr if then stmt else stmt stmt else stmt expr then if E2 S1 S3 E1 S2 Consider the following grammar segment: stmt if exprthen stmt | if exprthen stmtelse stmt | other (any other statement) What’s problem here ? Let’s consider a simple parse tree: Else must match to previous then. Structure indicates parse subtree for expression.
Example : What Happens with this string? If E1then if E2then S1else S2 How is this parsed ? if E1then if E2then S1 else S2 if E1then if E2then S1 else S2 vs. What’s the issue here ?
Parse Trees for Example stmt expr if then stmt stmt else stmt expr then if stmt expr if then stmt else stmt stmt expr then if E1 E1 S2 E2 S2 E2 S1 S1 Form 1: Form 2: What’s the issue here ?