Download

1 / 25
260 likes | 495 Views
A Tutorial on the Partially Observable Markov Decision Process and Its Applications. Lawrence Carin June 7,2006. Outline. Overview of Markov decision Processes (MDPs) Introduction to partially observable decision processes (POMDPs) Some applications of POMDPs Conclusions.

E N D
A Tutorial on the Partially Observable Markov Decision Process and Its Applications Lawrence Carin June 7,2006
Outline • Overview of Markov decision Processes (MDPs) • Introduction to partially observable decision processes (POMDPs) • Some applications of POMDPs • Conclusions
Overview of MDPs • Introduction to POMDPs model • Some applications of POMDPs • Conclusions
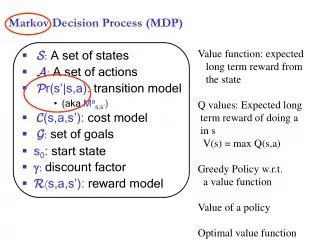
Markov decision processes The MDP is defined by the tuple < S, A, T, R > • S is a finite set of states of the world. • A is a finite set of actions. • T: SA (S) is the state-transition function, the probability of an action changing the the world state from one to another,T(s, a, s’). • R: SA is the reward for the agent in a given world state after performing an action, R(s, a).
WORLD: T(s,a, s’) State s Action a AGENT Markov decision processes Two properties of the MDP • The action-dependent state transition is Markovian • The state is fully observable after taking action a Illustration of MDPs
Markov decision processes Objective of MDPs • Finding the optimal policy , mapping state s to action • a in order to maximize the value function V(s).
Overview of MDPs • Introduction to POMDPs • Some applications of POMDPs • Conclusions
Introduction to POMDPs The POMDP is defined by the tuple < S, A, T, R, , O> • S, A, T, and R are defined the same as in MDPs • is a finite set of observations the agent can experience its world. • O: SA () is the observation function, the probability of making a certain observation after performing a particular action, landing in state s’, O(s’, a, o).
Introduction to POMDPs Differences between MDPs and POMDPs • The state is hidden after taking action a. • The hidden state information is inferred from the action-state dependent observation function O(s’, a, o). Uncertainty of state s in POMDPs
Introduction to POMDPs A new concept in POMDPs: Belief State b(s) b(st) = Pr(st= s| o1, a1, o2, a2, …, ot-1, at-1, ot)
s1 s1 o1 o2 b’=T(b|a, o1) b b’=T(b|a, o2) s2 s2 s3 s3 n-1 control interval remaining n control interval remaining Introduction to POMDPs The belief state b(s)evolves according to Bayes rule (1)
WORLD: T(s,a, s’) O(s’, a, o) Action a Observation o AGENT b SE: Introduction to POMDPs Illustration of POMDPs SE: State Estimator using (1) : Policy Search
Expected immediate reward Introduction to POMDPs Objective of POMDPs • Finding the optimal policy for POMDPs, mapping • belief point b to action a in order to maximize the • value function V(b). (2)
p1 V(b) p2 p3 p4 p5 Pr(S1) a(p1) a(p2) a(p5) 1 0 Introduction to POMDPs • Piecewise linearity and convexity of optimal • value function for finite horizon in POMDPs (3) Optimal value function
Introduction to POMDPs Substituting (3), (1) into (2) Maximizing to obtain the index l (4) -vector of belief point b Optimal value of belief point b
Introduction to POMDPs Approaches to solving POMDPs problem • Exact algorithms: finding all -vectors for the whole • belief space which is exact but intractable for large • size problems. • Approximate algorithms: finding -vectors of a • subset of the belief space, which is fast and can deal • with large size problems.
Point-Based Value Iteration Point-based value iteration (PBVI) b0 b1 b3 b4 b5 • focus on a finite set of belief points • maintain an -vector for each point
Region-Based Value Iteration (RBVI) • RBVI maintains an -vector for each convex region over which the optimal value function is linear. • RBVI simultaneously determines the -vectors for all relevant convex regions based on all available belief points.
RBVI (Contd) The piecewise linear value function: which can be reformulated as by introducing hidden variables z(b)=k, denoting bBk
RBVI (Contd) The belief space is partitioned using hyper-ellipsoids, Then we have
RBVI (Contd) The joint distribution of V(b) and b can be written as where Expectation-Maximization (EM) Estimation: E step: M step:
Overview of MDPs • Introduction to POMDPs model • Some applications of POMDPs • Conclusions
Applications of POMDPs • Application of Partially Observable Markov Decision • Processes to robot navigation in a Minefield • Application of Partially Observable Markov Decision • Processes to feature selection • Application of Partially Observable Markov Decision • Processes to sensor scheduling
Applications of POMDPs Some considerations in applying POMDPs to new problems • How to define the state • How to obtain the transition and observation matrix • How to set the reward
References • Leslie Pack Kaelbling, Michael L. Littman and Anthony R. Cassandra. Planning and Acting in Partially Observable Stochastic Domains. Artificial Intelligence, Vol. 101,1998. • Smallwood, R. D., and Sondik, E. J. 1973. The optimal control of partially observable markov processes over a finite horizon. Operational Research 21:1071–1088. • J. Pineau, G. Gordon & S. Thrun. Point-based value iteration: An anytime algorithm for POMDPs. International Joint Conference on Artificial Intelligence (IJCAI), Acapulco, Mexico, Aug. 2003. • D. P. Bertsekas. Dynamic Programming and Optimal Control. Athena Scientific, Blemont, Massachusetts,2001, Vol.1 & Vol.2. • Bellman, R. 1957. Dynamic Programming. Princeton University Press.