Download

1 / 4
40 likes | 194 Views
Project 2 SIFT Matching by Hierarchical K -means Quantization. 2014-4-21. Experiment Setting. Image database UKBench dataset: http://pan.baidu.com/s/1jGgFY6q 10200 images from 2550 categories Feature extraction SIFT feature The source code will be provided

E N D
Project 2SIFT Matching by Hierarchical K-means Quantization 2014-4-21
Experiment Setting • Image database • UKBench dataset: http://pan.baidu.com/s/1jGgFY6q • 10200 images from 2550 categories • Feature extraction • SIFT feature • The source code will be provided • http://staff.ustc.edu.cn/~zhwg/download/DSift.rar
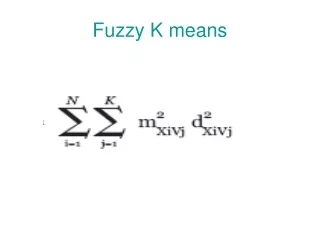
Tasks • Codebook training • Sample SIFT features from the UKB data set • Training sample number: 100K • Train visual codebook by hierarchical k-means • Codebook size: 10K (level = 4, branch = 10) • Each cluster center is regarded as a visual word • Feature quantization with visual codebook • Identify the closest visual word for a test feature • Assign the cluster ID to the feature as quantization result • Feature matching based on quantization • Two features from two images are considered as a match if they are quantized to the same visual word • Select 5 relevant image pairs to conduct feature matching • Select 5 irrelevant image pairs to conduct feature matching
Implementation • Program with C++ or Matlab • You may need Open CV when programing with C++ • OpenCV 210 library files are provided • You do not need to install the OpenCV source file • Refer to OpenCV China for instructions to set programming environment • http://wiki.opencv.org.cn/index.php/Template:Install • Refer to OpenCV China for instructions to process images : • http://wiki.opencv.org.cn/index.php/%E9%A6%96%E9%A1%B5