Download

1 / 48
480 likes | 582 Views
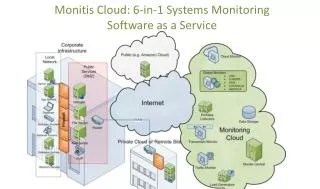
Trace-Oriented Monitoring for Cloud Systems. Jingwen Zhou jwzhou@nudt.edu.cn. 2014.10.16. Background. The lovely & horrible cloud systems. Microsoft: 218,000 in 2008. 2013.7. Increasing in scale. Increasing in complexity. March 13-14, 2008

E N D
Trace-Oriented Monitoringfor Cloud Systems Jingwen Zhou jwzhou@nudt.edu.cn 2014.10.16
Background The lovely & horrible cloud systems
Microsoft: 218,000in 2008 2013.7 Increasing in scale Increasing in complexity
March 13-14, 2008 Malfunction in Windows Azure last 22 hours … January 31, 2009 Google search outage due to programming error last 40 min February 24, 2009 Gmail and Google Apps Engine outage last 2.5 hours June 17, 2008 Google AppEngine partial outage due to programming error last 5 hours August, 2013 meltdowns Amazon: $7,000,000/100min Google: $550,000/5min & 40% ...... August 11, 2008 Gmail site unavailable due to outage in contacts system last 1.5 hours February 15, 2008 S3 outage: the authentication service overload leading to unavailability last 2 hours July 20, 2008 S3 outage: single bit error leading to gossip protocol blowup last >6 hours June 29, 2010 intermittent performance problems last 3 hours
March 13-14, 2008 Malfunction in Windows Azure last 22 hours … January 31, 2009 Google search outage due to programming error last 40 min February 24, 2009 Gmail and Google Apps Engine outage last 2.5 hours June 17, 2008 Google AppEngine partial outage due to programming error last 5 hours August, 2013 meltdowns Amazon: $7,000,000/100min Google: $550,000/5min & 40% ...... August 11, 2008 Gmail site unavailable due to outage in contacts system last 1.5 hours February 15, 2008 S3 outage: the authentication service overload leading to unavailability last 2 hours July 20, 2008 S3 outage: single bit error leading to gossip protocol blowup last >6 hours June 29, 2010 intermittent performance problems last 3 hours
Trace-Oriented Monitoring Remediation Detection Diagnosis Trace Dataset Data Trace
Trace-Oriented Monitoring Remediation Detection Diagnosis ④ TraceBench Data ① ③ Trace ② MTracer
Trace Tracking the causal path of system running
In the rest, the traces discussed are collected in HDFS, which is a widely used cloud file storage system. HDFS
Monitoring Resource-oriented Monitoring Trace-oriented Monitoring • Record execution paths, or called the traces of requests • X-Trace, P-Tracer, Zipkin … • Record the resource consumption, such as CPU and memory • Ganglia, Chukwa …
Monitoring Resource-oriented Monitoring Trace-oriented Monitoring • Record execution paths, or called the traces of requests • X-Trace, P-Tracer, Zipkin … • Record the resource consumption, such as CPU and memory • Ganglia, Chukwa …
The tracerecords the execution path of a user request. • Trace = events + relationships • Event: function name and latency … • Relationship: local and remote function calls … • Trace → Trace Tree • Nodes correspond to events. • Edges correspond to relationships, e.g., a and c. • Trace Tree → linear event sequence • DFS: 1,2,4,3,5 • Call and Return: C1C2C4R4R2C3C5R5R3R1 Comparing with the resource-oriented methods, traces can record more valuable (and fine-grained) information, such as function calls and host communications.
Example 1 Normal Meet a killDN fault
Example 2 Meet a slowHDFSfault Normal
In total, trace can effectively support failure detection, fault analysis, …
MTracer A efficient and lightweight tracing system
Motivation P-Tracer ?? MTracer X-Trace • In prototype: • store trace in text file • simple visualization • … • too little function to use • For Medium-scale DS: • Lightweight • Efficient • Real time • Visualized • For large-scale DS: • construct call trees using a map-reduce process • … • exceptions also occur in monitors and hard to recovery
Architecture Visualizing UI Manager Database Monitor Server Recovering … Monitor Server writer writer Storing extractor Receiver DS Network Event Recording Node1 Reporter Node2 Noden … info … DS instrumentation
Recording Request start Request end Node TraceIDNID Timestamp Name R1 Node1 Trace1 NID1 ST1 ET1 F1 R2 Node1 Trace1 NID1 ST2 ET2 F2 R3 Node2 Trace1 NID2 ST3 ET3 F3 R4 Node2 Trace1 NID3 ST4 ET4 F4 R5 Node1 Trace1 NID1 ST5 ET5 F5 NID1 F1 ET1 ST1 Event NID1 NID1 F2 F5 Node1 ET2 ST5 ET5 ST2 E2 E3 TraceIDFatherNIDFatherSTChildNID NID2 NID3 E1 Trace1 0 0 NID1 E2 Trace1 NID1 T2 NID2 E3 Trace1 NID1 T2 NID3 F3 F4 Node2 Edge ST3 ET3 ST4 ET4 Name, latency, node, … Local call, remote call, …
Recording • Generating an event: 0.046ms • vs. seconds or minutes in DS • Size of an event: 0.315KB • 2MB bandwidth vs. GB-level network • Generating an ID: 0.057ms • >50% less using our method The overhead on a client is negligible!
Storing Optimization 1: Batch Inserting T_Trace Q_Trace TraceWriter Event EventWriter T_Event Q_Event Extractor Parallelization T_Edge EdgeWriter Q_Edge T_Operation OperationWriter Q_Operation Optimization 2: Information updating in memory
Storing The optimizations are effective!
Visualizing Demo
Publications • Jingwen Zhou, Zhenbang Chen, HaiboMi, and Ji Wang. “MTracer: A Trace-Oriented Monitoring Framework for Medium-Scale Distributed Systems,” in Proceedings of the IEEE eighth International Symposium on Service Oriented System Engineering (SOSE 2014), pp. 266-271, 2014. Available at: http://mtracer.github.io/MTracer/ http://mtracer.github.io/MTracer-Viz/ http://www.wsdream.net/mtracer-viz
TraceBench An open trace dataset
Motivation TraceBench Diagnosis Detection Remediation Trace-based research We collected a trace data set. Instrumenting and deploying a target system Choosing or implementing a tracing system … Collecting traces There is limited free available trace data set existing in industry and academia.
Environment … client001 client002 clientN Clients monitor HDFS requests control track … Datanode001 Datanode002 DatanodeM monitor control monitor controller MTracer Server Ganglia Server Namenode HDFS control track control inject faults monitor CloudStack
Three Subsets stop MTracer and HDFS start MTracer and HDFS trace collection period start Clients stop Clients Normal request handling period inject a fault recover the system Abnormal request handling period inject a fault inject a fault inject a fault inject a fault inject a fault Combination request handling period
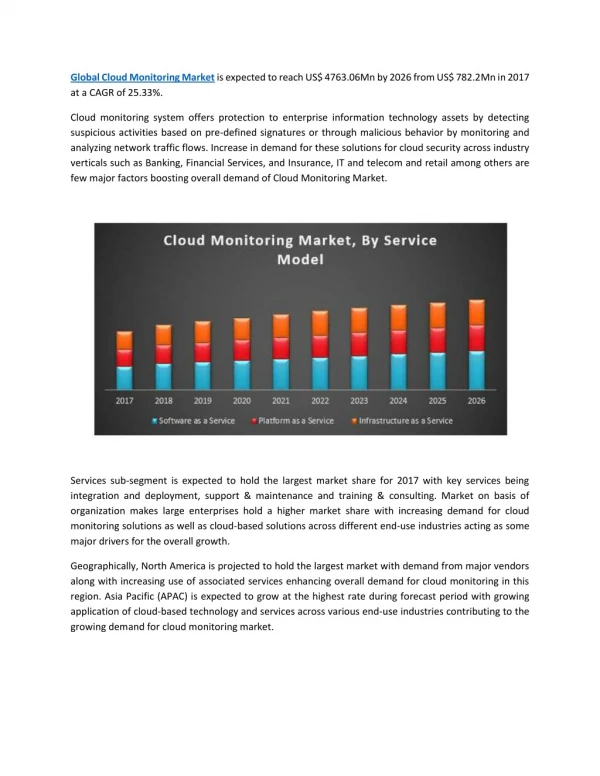
Statistics • The whole collection work lasted for more than half a year. • 50 clients + (50+1) HDFS nodes + others > 100 VMs • inject 14 faults of 4 types • whole size of TraceBench≈ 3.2 GB,including: • 361 .sql files • 366,487 traces • 14,724,959 events • 6,273,497 relationships • trace length=[5, 420] • nodes per trace = [2, 44] • ……
Applications • Detecting failed requests • Mining temporal invariants • Diagnosing performance anomalies
Applications with TraceBench with synthetic logs [1] [1] I. Beschastnikh, Y. Brun, M. D. Ernst, A. Krishnamurthy, and T. E. Anderson, “Mining temporal invariants from partially ordered logs,” ACM SIGOPS Operating Systems Review, vol. 45, no. 3, pp. 39–46, 2011.
Publications • Jingwen Zhou, Zhenbang Chen, Ji Wang, ZibinZheng, and Michael R. Lyu. “Towards An Open Data Set for Trace-Oriented Monitoring,” In Proceedings of the 2014 IEEE International Conference on Cloud Computing (CLOUD 2014),pp. 922-923, 2014. • Jingwen Zhou, Zhenbang Chen, Ji Wang, ZibinZheng, and Michael R. Lyu. “TraceBench: An Open Data Set for Trace-Oriented Monitoring,” In Proceedings of the 6th IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2014),to appear, 2014. Available at: http://mtracer.github.io/TraceBench/ http://www.wsdream.net/mtracer-viz
Various Algorithms ofDetection, Analysis, Remediation, … An ongoing work
Based on TraceBench, we extract many properties of HDFS which can be expressing with various languages! Following are some samples. Each read request contains at least one reading operation. And the last reading operation should be successful. Or else, we say it is a failed read request.
These properties can be used to monitor HDFS running, using methods in runtime verification (RV). • The preliminary experimental results indicate the promise.
Publications • Jingwen Zhou, Zhenbang Chen, Ji Wang, ZibinZheng, and Wei Dong “A Runtime Verification Based Trace-Oriented Monitoring Framework for Cloud Systems,” In SupplementalProceedings of the 25th IEEE International Symposium on Software Reliability Engineering (ISSRE 2014),to appear, 2014.
Conclusion & Future Work A not too bad beginning & A really long way
Conclusion A RV based method and TraceBench MTracer Trace
Future Work • Temporal invariants with superscript • e.g., C -> W3 • More examples? • Probabilistic models • Performance-aware models • Any suggestions?
Thanks and Any Questions? Jingwen Zhou jwzhou@nudt.edu.cn 2014.10.16